 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Precision Quantization for Federated Learning on Resource-Constrained Heterogeneous Devices
Nov 29, 2023While federated learning (FL) systems often utilize quantization to battle communication and computational bottlenecks, they have heretofore been limited to deploying fixed-precision quantization schemes. Meanwhile, the concept of mixed-precision quantization (MPQ), where different layers of a deep learning model are assigned varying bit-width, remains unexplored in the FL settings. We present a novel FL algorithm, FedMPQ, which introduces mixed-precision quantization to resource-heterogeneous FL systems. Specifically, local models, quantized so as to satisfy bit-width constraint, are trained by optimizing an objective function that includes a regularization term which promotes reduction of precision in some of the layers without significant performance degradation. The server collects local model updates, de-quantizes them into full-precision models, and then aggregates them into a global model. To initialize the next round of local training, the server relies on the information learned in the previous training round to customize bit-width assignments of the models delivered to different clients. In extensive benchmarking experiments on several model architectures and different datasets in both iid and non-iid settings, FedMPQ outperformed the baseline FL schemes that utilize fixed-precision quantization while incurring only a minor computational overhead on the participating devices.
Accelerating Non-IID Federated Learning via Heterogeneity-Guided Client Sampling
Sep 30, 2023Statistical heterogeneity of data present at client devices in a federated learning (FL) system renders the training of a global model in such systems difficult. Particularly challenging are the settings where due to resource constraints only a small fraction of clients can participate in any given round of FL. Recent approaches to training a global model in FL systems with non-IID data have focused on developing client selection methods that aim to sample clients with more informative updates of the model. However, existing client selection techniques either introduce significant computation overhead or perform well only in the scenarios where clients have data with similar heterogeneity profiles. In this paper, we propose HiCS-FL (Federated Learning via Hierarchical Clustered Sampling), a novel client selection method in which the server estimates statistical heterogeneity of a client's data using the client's update of the network's output layer and relies on this information to cluster and sample the clients. We analyze the ability of the proposed techniques to compare heterogeneity of different datasets, and characterize convergence of the training process that deploys the introduced client selection method. Extensive experimental results demonstrate that in non-IID settings HiCS-FL achieves faster convergence and lower training variance than state-of-the-art FL client selection schemes. Notably, HiCS-FL drastically reduces computation cost compared to existing selection schemes and is adaptable to different heterogeneity scenarios.
XVir: A Transformer-Based Architecture for Identifying Viral Reads from Cancer Samples
Aug 28, 2023It is estimated that approximately 15% of cancers worldwide can be linked to viral infections. The viruses that can cause or increase the risk of cancer include human papillomavirus, hepatitis B and C viruses, Epstein-Barr virus, and human immunodeficiency virus, to name a few. The computational analysis of the massive amounts of tumor DNA data, whose collection is enabled by the recent advancements in sequencing technologies, have allowed studies of the potential association between cancers and viral pathogens. However, the high diversity of oncoviral families makes reliable detection of viral DNA difficult and thus, renders such analysis challenging. In this paper, we introduce XVir, a data pipeline that relies on a transformer-based deep learning architecture to reliably identify viral DNA present in human tumors. In particular, XVir is trained on genomic sequencing reads from viral and human genomes and may be used with tumor sequence information to find evidence of viral DNA in human cancers. Results on semi-experimental data demonstrate that XVir is capable of achieving high detection accuracy, generally outperforming state-of-the-art competing methods while being more compact and less computationally demanding.
Automotive RADAR sub-sampling via object detection networks: Leveraging prior signal information
Feb 21, 2023



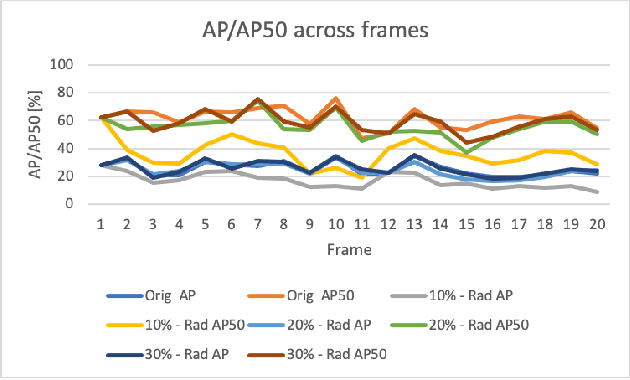
Automotive radar has increasingly attracted attention due to growing interest in autonomous driving technologies. Acquiring situational awareness using multimodal data collected at high sampling rates by various sensing devices including cameras, LiDAR, and radar requires considerable power, memory and compute resources which are often limited at an edge device. In this paper, we present a novel adaptive radar sub-sampling algorithm designed to identify regions that require more detailed/accurate reconstruction based on prior environmental conditions' knowledge, enabling near-optimal performance at considerably lower effective sampling rates. Designed to robustly perform under variable weather conditions, the algorithm was shown on the Oxford raw radar and RADIATE dataset to achieve accurate reconstruction utilizing only 10% of the original samples in good weather and 20% in extreme (snow, fog) weather conditions. A further modification of the algorithm incorporates object motion to enable reliable identification of important regions. This includes monitoring possible future occlusions caused by objects detected in the present frame. Finally, we train a YOLO network on the RADIATE dataset to perform object detection directly on RADAR data and obtain a 6.6% AP50 improvement over the baseline Faster R-CNN network.
The Best of Both Worlds: Accurate Global and Personalized Models through Federated Learning with Data-Free Hyper-Knowledge Distillation
Jan 21, 2023



Heterogeneity of data distributed across clients limits the performance of global models trained through federated learning, especially in the settings with highly imbalanced class distributions of local datasets. In recent years, personalized federated learning (pFL) has emerged as a potential solution to the challenges presented by heterogeneous data. However, existing pFL methods typically enhance performance of local models at the expense of the global model's accuracy. We propose FedHKD (Federated Hyper-Knowledge Distillation), a novel FL algorithm in which clients rely on knowledge distillation (KD) to train local models. In particular, each client extracts and sends to the server the means of local data representations and the corresponding soft predictions -- information that we refer to as ``hyper-knowledge". The server aggregates this information and broadcasts it to the clients in support of local training. Notably, unlike other KD-based pFL methods, FedHKD does not rely on a public dataset nor it deploys a generative model at the server. We analyze convergence of FedHKD and conduct extensive experiments on visual datasets in a variety of scenarios, demonstrating that FedHKD provides significant improvement in both personalized as well as global model performance compared to state-of-the-art FL methods designed for heterogeneous data settings.
Federated Learning in Non-IID Settings Aided by Differentially Private Synthetic Data
Jun 01, 2022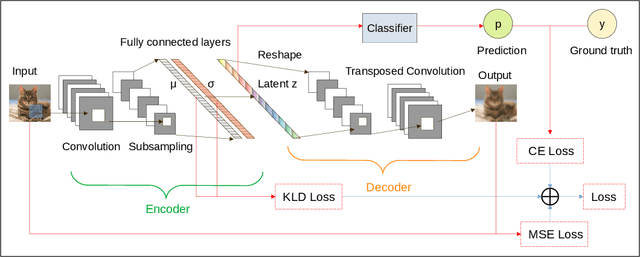
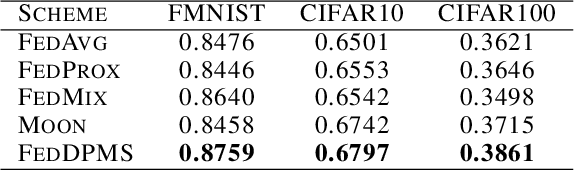
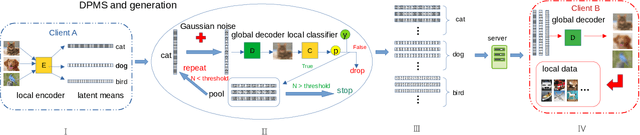
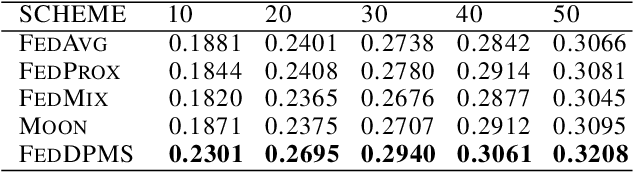
Federated learning (FL) is a privacy-promoting framework that enables potentially large number of clients to collaboratively train machine learning models. In a FL system, a server coordinates the collaboration by collecting and aggregating clients' model updates while the clients' data remains local and private. A major challenge in federated learning arises when the local data is heterogeneous -- the setting in which performance of the learned global model may deteriorate significantly compared to the scenario where the data is identically distributed across the clients. In this paper we propose FedDPMS (Federated Differentially Private Means Sharing), an FL algorithm in which clients deploy variational auto-encoders to augment local datasets with data synthesized using differentially private means of latent data representations communicated by a trusted server. Such augmentation ameliorates effects of data heterogeneity across the clients without compromising privacy. Our experiments on deep image classification tasks demonstrate that FedDPMS outperforms competing state-of-the-art FL methods specifically designed for heterogeneous data settings.
Federated Learning Under Intermittent Client Availability and Time-Varying Communication Constraints
May 13, 2022
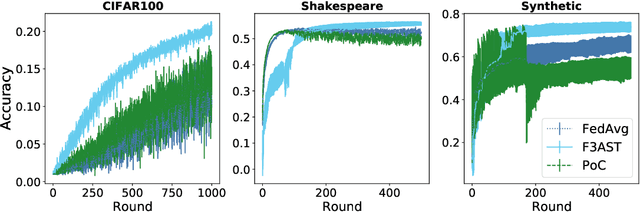
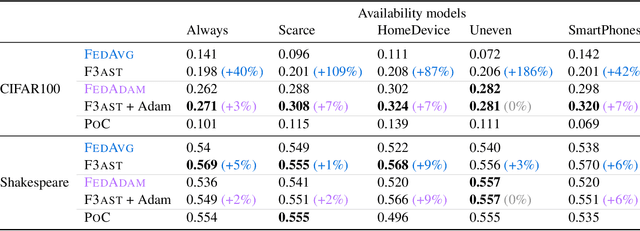
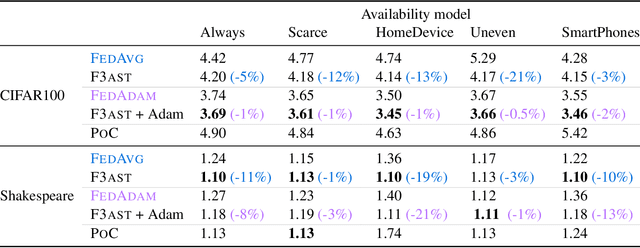
Federated learning systems facilitate training of global models in settings where potentially heterogeneous data is distributed across a large number of clients. Such systems operate in settings with intermittent client availability and/or time-varying communication constraints. As a result, the global models trained by federated learning systems may be biased towards clients with higher availability. We propose F3AST, an unbiased algorithm that dynamically learns an availability-dependent client selection strategy which asymptotically minimizes the impact of client-sampling variance on the global model convergence, enhancing performance of federated learning. The proposed algorithm is tested in a variety of settings for intermittently available clients under communication constraints, and its efficacy demonstrated on synthetic data and realistically federated benchmarking experiments using CIFAR100 and Shakespeare datasets. We show up to 186% and 8% accuracy improvements over FedAvg, and 8% and 7% over FedAdam on CIFAR100 and Shakespeare, respectively.
End-to-end system for object detection from sub-sampled radar data
Mar 08, 2022
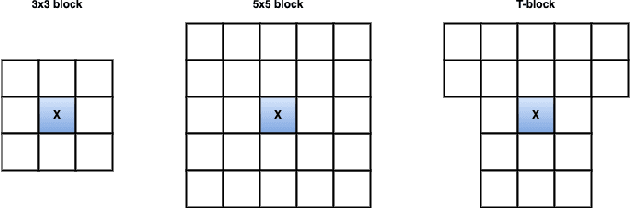
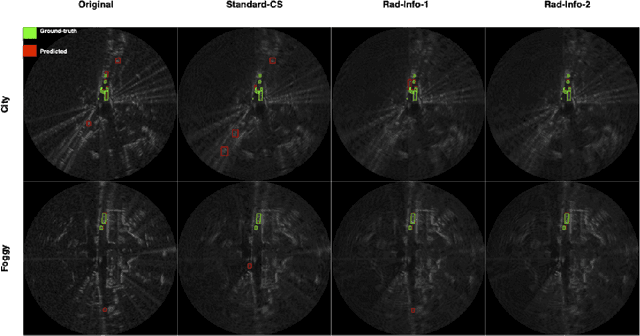
Robust and accurate sensing is of critical importance for advancing autonomous automotive systems. The need to acquire situational awareness in complex urban conditions using sensors such as radar has motivated research on power and latency-efficient signal acquisition methods. In this paper, we present an end-to-end signal processing pipeline, capable of operating in extreme weather conditions, that relies on sub-sampled radar data to perform object detection in vehicular settings. The results of the object detection are further utilized to sub-sample forthcoming radar data, which stands in contrast to prior work where the sub-sampling relies on image information. We show robust detection based on radar data reconstructed using 20% of samples under extreme weather conditions such as snow or fog, and on low-illuminated nights. Additionally, we generate 20% sampled radar data in a fine-tuning set and show 1.1% gain in AP50 across scenes and 3% AP50 gain in motorway condition.
Federated Dynamic Sparse Training: Computing Less, Communicating Less, Yet Learning Better
Dec 18, 2021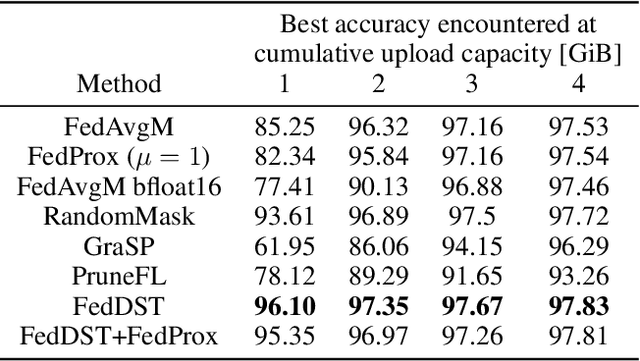
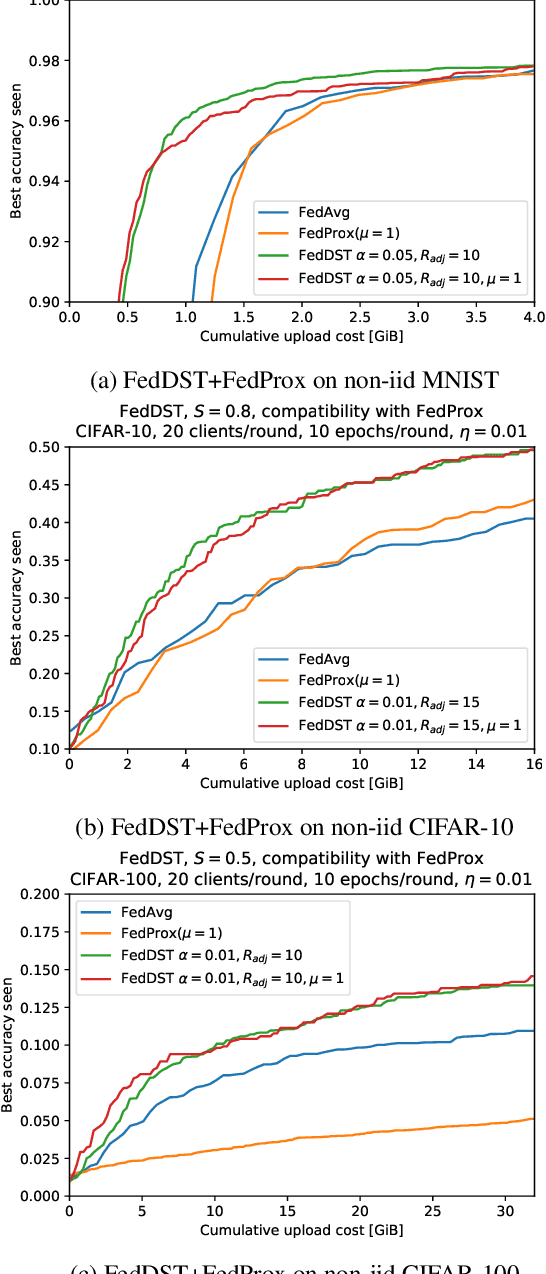
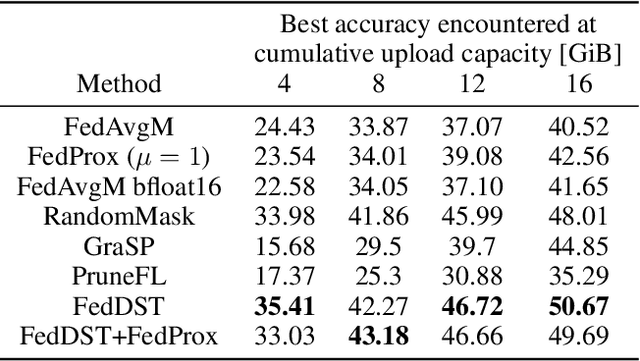
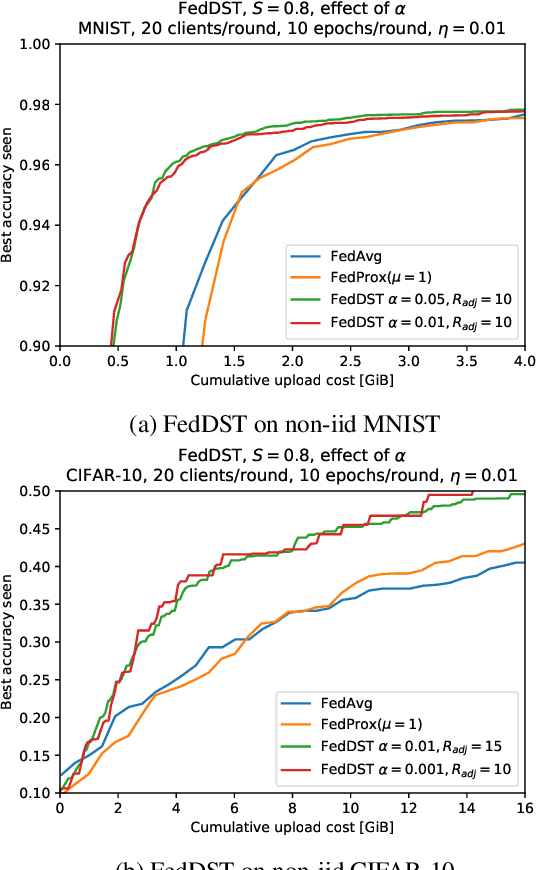
Federated learning (FL) enables distribution of machine learning workloads from the cloud to resource-limited edge devices. Unfortunately, current deep networks remain not only too compute-heavy for inference and training on edge devices, but also too large for communicating updates over bandwidth-constrained networks. In this paper, we develop, implement, and experimentally validate a novel FL framework termed Federated Dynamic Sparse Training (FedDST) by which complex neural networks can be deployed and trained with substantially improved efficiency in both on-device computation and in-network communication. At the core of FedDST is a dynamic process that extracts and trains sparse sub-networks from the target full network. With this scheme, "two birds are killed with one stone:" instead of full models, each client performs efficient training of its own sparse networks, and only sparse networks are transmitted between devices and the cloud. Furthermore, our results reveal that the dynamic sparsity during FL training more flexibly accommodates local heterogeneity in FL agents than the fixed, shared sparse masks. Moreover, dynamic sparsity naturally introduces an "in-time self-ensembling effect" into the training dynamics and improves the FL performance even over dense training. In a realistic and challenging non i.i.d. FL setting, FedDST consistently outperforms competing algorithms in our experiments: for instance, at any fixed upload data cap on non-iid CIFAR-10, it gains an impressive accuracy advantage of 10% over FedAvgM when given the same upload data cap; the accuracy gap remains 3% even when FedAvgM is given 2x the upload data cap, further demonstrating efficacy of FedDST. Code is available at: https://github.com/bibikar/feddst.
Opportunistic Federated Learning: An Exploration of Egocentric Collaboration for Pervasive Computing Applications
Mar 24, 2021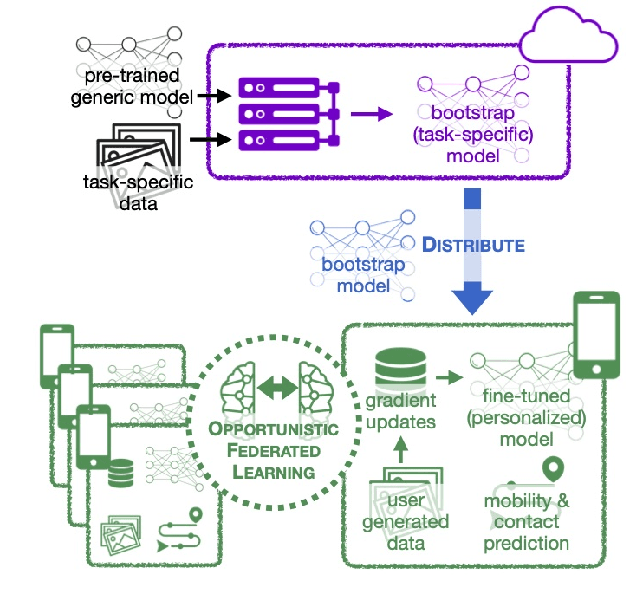
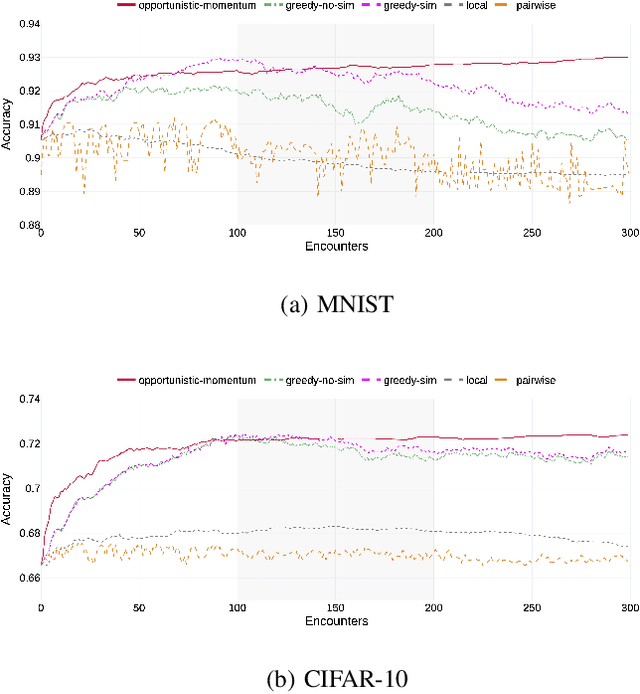
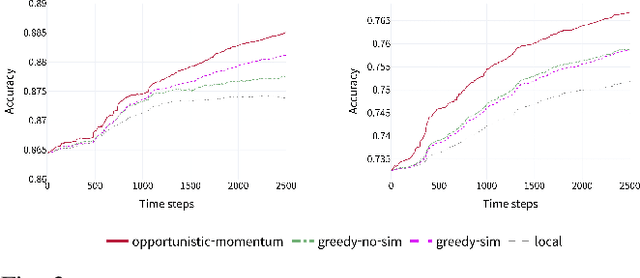
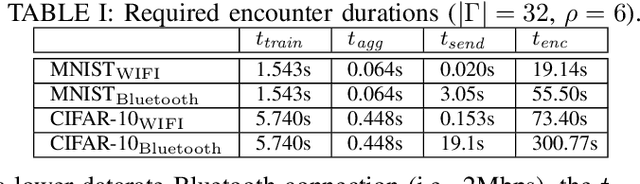
Pervasive computing applications commonly involve user's personal smartphones collecting data to influence application behavior. Applications are often backed by models that learn from the user's experiences to provide personalized and responsive behavior. While models are often pre-trained on massive datasets, federated learning has gained attention for its ability to train globally shared models on users' private data without requiring the users to share their data directly. However, federated learning requires devices to collaborate via a central server, under the assumption that all users desire to learn the same model. We define a new approach, opportunistic federated learning, in which individual devices belonging to different users seek to learn robust models that are personalized to their user's own experiences. However, instead of learning in isolation, these models opportunistically incorporate the learned experiences of other devices they encounter opportunistically. In this paper, we explore the feasibility and limits of such an approach, culminating in a framework that supports encounter-based pairwise collaborative learning. The use of our opportunistic encounter-based learning amplifies the performance of personalized learning while resisting overfitting to encountered data.