 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visually-Grounded Semantics from Contrastive Adversarial Samples
Jun 27, 2018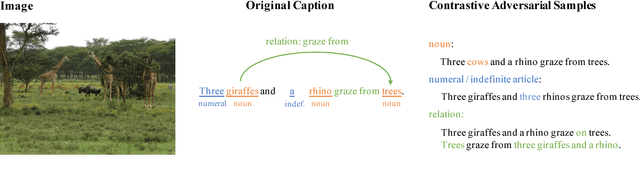

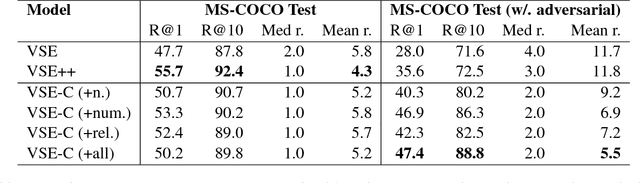

We study the problem of grounding distributional representations of texts on the visual domain, namely visual-semantic embeddings (VSE for short). Begin with an insightful adversarial attack on VSE embeddings, we show the limitation of current frameworks and image-text datasets (e.g., MS-COCO) both quantitatively and qualitatively. The large gap between the number of possible constitutions of real-world semantics and the size of parallel data, to a large extent, restricts the model to establish the link between textual semantics and visual concepts. We alleviate this problem by augmenting the MS-COCO image captioning datasets with textual contrastive adversarial samples. These samples are synthesized using linguistic rules and the WordNet knowledge base. The construction procedure is both syntax- and semantics-aware. The samples enforce the model to ground learned embeddings to concrete concepts within the image. This simple but powerful technique brings a noticeable improvement over the baselines on a diverse set of downstream tasks, in addition to defending known-type adversarial attacks. We release the codes at https://github.com/ExplorerFreda/VSE-C.
Understanding and Improving Multi-Sense Word Embeddings via Extended Robust Principal Component Analysis
Mar 03, 2018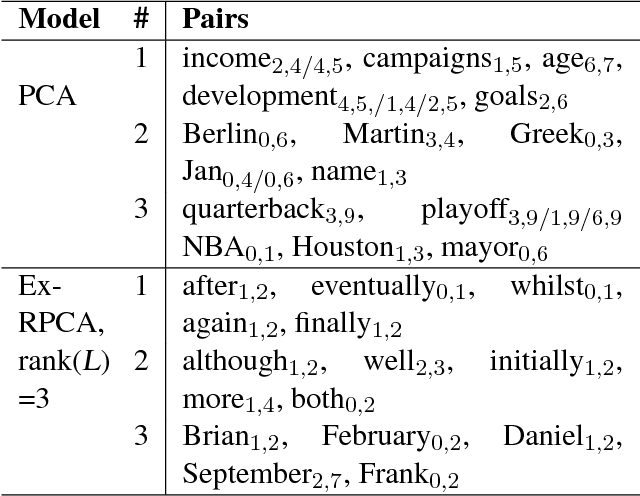

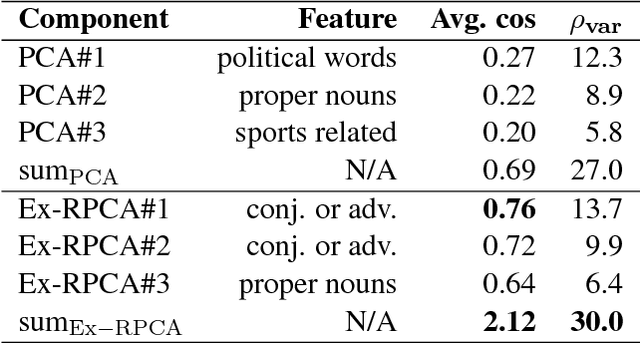
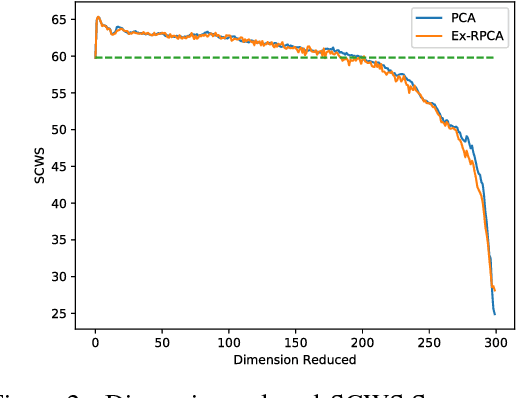
Unsupervised learned representations of polysemous words generate a large of pseudo multi senses since unsupervised methods are overly sensitive to contextual variations. In this paper, we address the pseudo multi-sense detection for word embeddings by dimensionality reduction of sense pairs. We propose a novel principal analysis method, termed Ex-RPCA, designed to detect both pseudo multi senses and real multi senses. With Ex-RPCA, we empirically show that pseudo multi senses are generated systematically in unsupervised method. Moreover, the multi-sense word embeddings can by improved by a simple linear transformation based on Ex-RPCA. Our improved word embedding outperform the original one by 5.6 points on Stanford contextual word similarity (SCWS) dataset. We hope our simple yet effective approach will help the linguistic analysis of multi-sense word embeddings in the future.
Real Multi-Sense or Pseudo Multi-Sense: An Approach to Improve Word Representation
Jan 06, 2017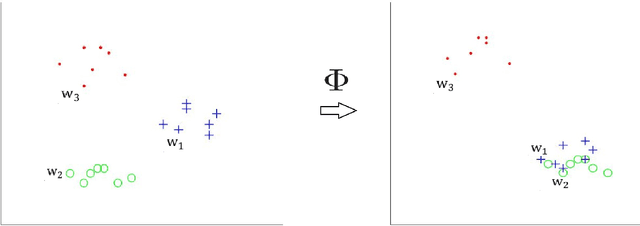
Previous researches have shown that learning multiple representations for polysemous words can improve the performance of word embeddings on many tasks. However, this leads to another problem. Several vectors of a word may actually point to the same meaning, namely pseudo multi-sense. In this paper, we introduce the concept of pseudo multi-sense, and then propose an algorithm to detect such cases. With the consideration of the detected pseudo multi-sense cases, we try to refine the existing word embeddings to eliminate the influence of pseudo multi-sense. Moreover, we apply our algorithm on previous released multi-sense word embeddings and tested it on artificial word similarity tasks and the analogy task. The result of the experiments shows that diminishing pseudo multi-sense can improve the quality of word representations. Thus, our method is actually an efficient way to reduce linguistic complexity.