 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSV: Towards Understanding the User-generated Short-form Videos
May 20, 2026Several large-scale video datasets have been published these years and have advanced the area of video understanding. However, the newly emerged user-generated short-form videos have rarely been studied. This paper presents USV, the User-generated Short-form Video dataset for high-level semantic video understanding. The dataset contains around 224K videos collected from UGC platforms by label queries without extra manual verification and trimming. Although video understanding has achieved plausible improvement these years, most works focus on instance-level recognition, which is not sufficient for learning the representation of the high-level semantic information of videos. Therefore, we further establish two tasks: topic recognition and video-text retrieval on USV. We propose two unified and effective baseline methods Multi-Modality Fusion Network (MMF-Net) and Video-Text Contrastive Learning (VTCL), to tackle the topic recognition task and video-text retrieval respectively, and carry out comprehensive benchmarks to facilitate future research. Our project page is https://usvdataset.github.io.
Joint-Modal Label Denoising for Weakly-Supervised Audio-Visual Video Parsing
Apr 28, 2022
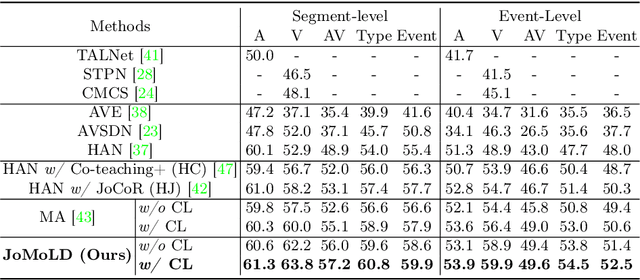
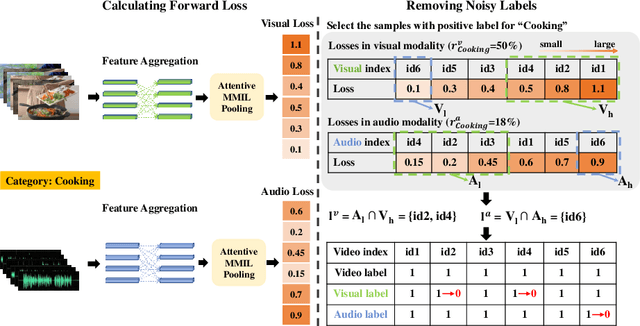
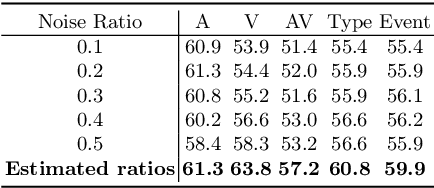
This paper focuses on the weakly-supervised audio-visual video parsing task, which aims to recognize all events belonging to each modality and localize their temporal boundaries. This task is challenging because only overall labels indicating the video events are provided for training. However, an event might be labeled but not appear in one of the modalities, which results in a modality-specific noisy label problem. Motivated by two observations that networks tend to learn clean samples first and that a labeled event would appear in at least one modality, we propose a training strategy to identify and remove modality-specific noisy labels dynamically. Specifically, we sort the losses of all instances within a mini-batch individually in each modality, then select noisy samples according to relationships between intra-modal and inter-modal losses. Besides, we also propose a simple but valid noise ratio estimation method by calculating the proportion of instances whose confidence is below a preset threshold. Our method makes large improvements over the previous state of the arts (e.g., from 60.0% to 63.8% in segment-level visual metric), which demonstrates the effectiveness of our approach.