 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Annotation-Free Validation of MLLMs: A Vision-Language Logical Consistency Metric
May 07, 2026Dominant accuracy evaluation might reward unwarranted guessing of Large Language Models, and it might not be applicable to novel tasks for model validation without ground-truth (gt) annotation. Based on basic logic principle, we propose a novel framework to evaluate the vision-language logical consistency of MLLMs on both sufficient and necessary cause-effect relations. We define Vision-Language Logical Consistency Metric (VL-LCM) on traditional MC-VQA tests, and recent NaturalBench tests without the need for gt annotation. Through systematic experiments on representative VL benchmark MMMU and recent VL challenges like NaturalBench, we evaluated 11 recent open-source MLLMs from 4 frontier families. Our findings reveal that, despite significant progress of recent MLLMs on accuracy, logical consistency lags behind significantly. Extensive evaluations on the correlations of VL-LCM with metrics on gt, the reliability of LCM, and the relation of VL-LCM with response distribution justify the validity and applicability of VL-LCM even without gt annotation. Our findings suggest that, beyond accuracy, logical consistency could be employed for both accuracy and reliability. VL-LCM can also be employed for MLLM selection, validation, and reliable answer justification in novel tasks without gt annotation.
Explicit Logic Channel for Validation and Enhancement of MLLMs on Zero-Shot Tasks
Mar 12, 2026Frontier Multimodal Large Language Models (MLLMs) exhibit remarkable capabilities in Visual-Language Comprehension (VLC) tasks. However, they are often deployed as zero-shot solution to new tasks in a black-box manner. Validating and understanding the behavior of these models become important for application to new task. We propose an Explicit Logic Channel, in parallel with the black-box model channel, to perform explicit logical reasoning for model validation, selection and enhancement. The frontier MLLM, encapsulating latent vision-language knowledge, can be considered as an Implicit Logic Channel. The proposed Explicit Logic Channel, mimicking human logical reasoning, incorporates a LLM, a VFM, and logical reasoning with probabilistic inference for factual, counterfactual, and relational reasoning over the explicit visual evidence. A Consistency Rate (CR) is proposed for cross-channel validation and model selection, even without ground-truth annotations. Additionally, cross-channel integration further improves performance in zero-shot tasks over MLLMs, grounded with explicit visual evidence to enhance trustworthiness. Comprehensive experiments conducted for two representative VLC tasks, i.e., MC-VQA and HC-REC, on three challenging benchmarks, with 11 recent open-source MLLMs from 4 frontier families. Our systematic evaluations demonstrate the effectiveness of proposed ELC and CR for model validation, selection and improvement on MLLMs with enhanced explainability and trustworthiness.
Combined CNN Transformer Encoder for Enhanced Fine-grained Human Action Recognition
Aug 03, 2022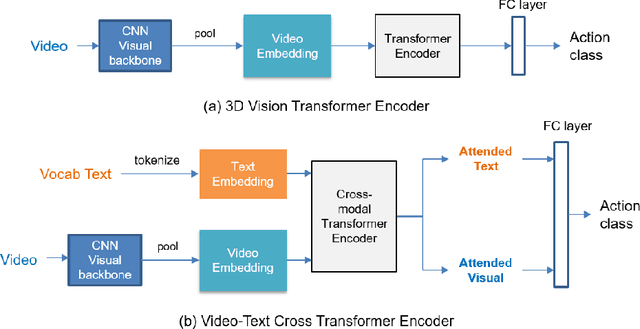

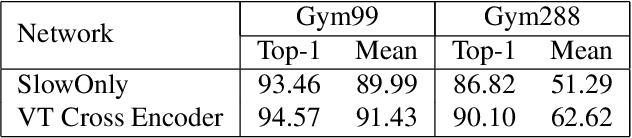
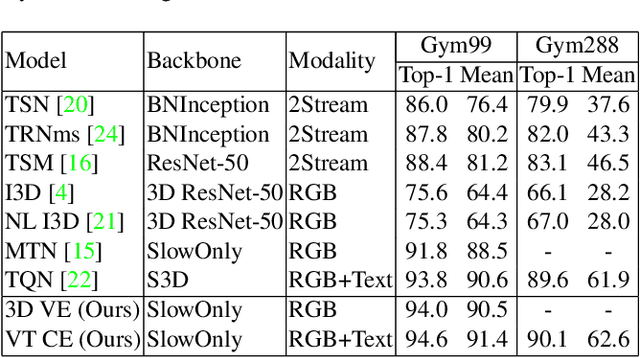
Fine-grained action recognition is a challenging task in computer vision. As fine-grained datasets have small inter-class variations in spatial and temporal space, fine-grained action recognition model requires good temporal reasoning and discrimination of attribute action semantics. Leveraging on CNN's ability in capturing high level spatial-temporal feature representations and Transformer's modeling efficiency in capturing latent semantics and global dependencies, we investigate two frameworks that combine CNN vision backbone and Transformer Encoder to enhance fine-grained action recognition: 1) a vision-based encoder to learn latent temporal semantics, and 2) a multi-modal video-text cross encoder to exploit additional text input and learn cross association between visual and text semantics. Our experimental results show that both our Transformer encoder frameworks effectively learn latent temporal semantics and cross-modality association, with improved recognition performance over CNN vision model. We achieve new state-of-the-art performance on the FineGym benchmark dataset for both proposed architectures.
Joint Learning On The Hierarchy Representation for Fine-Grained Human Action Recognition
Oct 12, 2021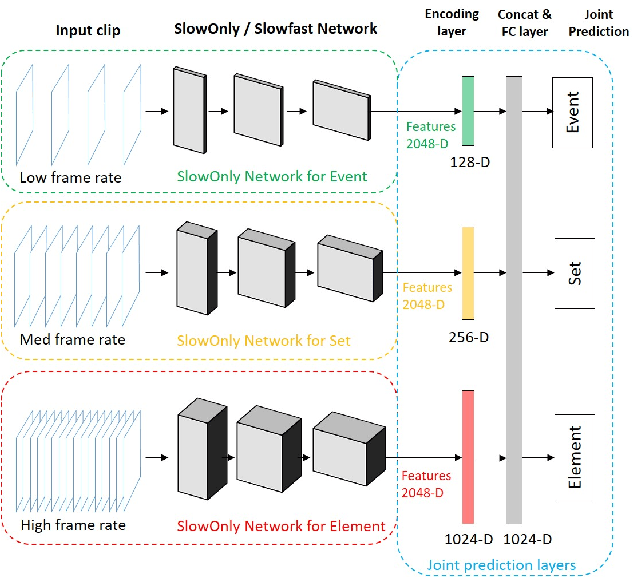
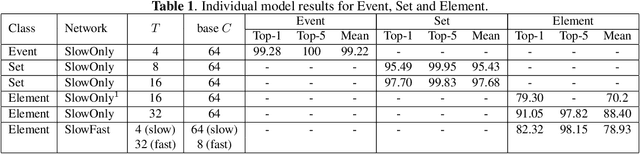

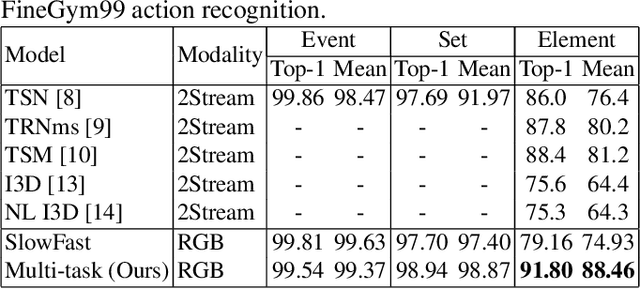
Fine-grained human action recognition is a core research topic in computer vision. Inspired by the recently proposed hierarchy representation of fine-grained actions in FineGym and SlowFast network for action recognition, we propose a novel multi-task network which exploits the FineGym hierarchy representation to achieve effective joint learning and prediction for fine-grained human action recognition. The multi-task network consists of three pathways of SlowOnly networks with gradually increased frame rates for events, sets and elements of fine-grained actions, followed by our proposed integration layers for joint learning and prediction. It is a two-stage approach, where it first learns deep feature representation at each hierarchical level, and is followed by feature encoding and fusion for multi-task learning. Our empirical results on the FineGym dataset achieve a new state-of-the-art performance, with 91.80% Top-1 accuracy and 88.46% mean accuracy for element actions, which are 3.40% and 7.26% higher than the previous best results.
* Camera ready for IEEE ICIP 2021