 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Data Minimization: Shallow Model as Your Privacy Filter
Oct 24, 2023



Face recognition service has been used in many fields and brings much convenience to people. However, once the user's facial data is transmitted to a service provider, the user will lose control of his/her private data. In recent years, there exist various security and privacy issues due to the leakage of facial data. Although many privacy-preserving methods have been proposed, they usually fail when they are not accessible to adversaries' strategies or auxiliary data. Hence, in this paper, by fully considering two cases of uploading facial images and facial features, which are very typical in face recognition service systems, we proposed a data privacy minimization transformation (PMT) method. This method can process the original facial data based on the shallow model of authorized services to obtain the obfuscated data. The obfuscated data can not only maintain satisfactory performance on authorized models and restrict the performance on other unauthorized models but also prevent original privacy data from leaking by AI methods and human visual theft. Additionally, since a service provider may execute preprocessing operations on the received data, we also propose an enhanced perturbation method to improve the robustness of PMT. Besides, to authorize one facial image to multiple service models simultaneously, a multiple restriction mechanism is proposed to improve the scalability of PMT. Finally, we conduct extensive experiments and evaluate the effectiveness of the proposed PMT in defending against face reconstruction, data abuse, and face attribute estimation attacks. These experimental results demonstrate that PMT performs well in preventing facial data abuse and privacy leakage while maintaining face recognition accuracy.
Generative Tweening: Long-term Inbetweening of 3D Human Motions
May 28, 2020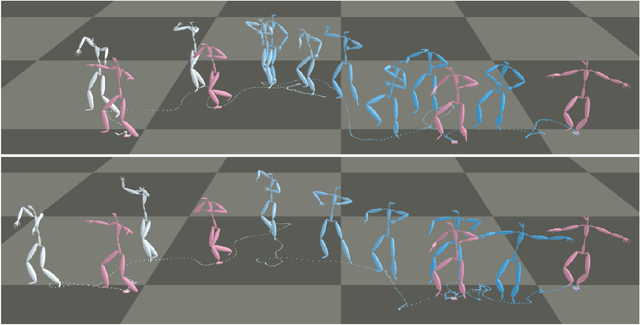
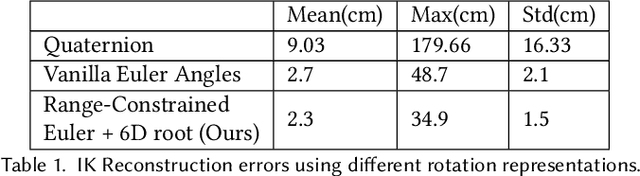
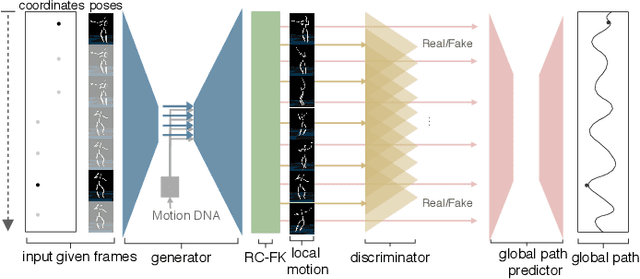

The ability to generate complex and realistic human body animations at scale, while following specific artistic constraints, has been a fundamental goal for the game and animation industry for decades. Popular techniques include key-framing, physics-based simulation, and database methods via motion graphs. Recently, motion generators based on deep learning have been introduced. Although these learning models can automatically generate highly intricate stylized motions of arbitrary length, they still lack user control. To this end, we introduce the problem of long-term inbetweening, which involves automatically synthesizing complex motions over a long time interval given very sparse keyframes by users. We identify a number of challenges related to this problem, including maintaining biomechanical and keyframe constraints, preserving natural motions, and designing the entire motion sequence holistically while considering all constraints. We introduce a biomechanically constrained generative adversarial network that performs long-term inbetweening of human motions, conditioned on keyframe constraints. This network uses a novel two-stage approach where it first predicts local motion in the form of joint angles, and then predicts global motion, i.e. the global path that the character follows. Since there are typically a number of possible motions that could satisfy the given user constraints, we also enable our network to generate a variety of outputs with a scheme that we call Motion DNA. This approach allows the user to manipulate and influence the output content by feeding seed motions (DNA) to the network. Trained with 79 classes of captured motion data, our network performs robustly on a variety of highly complex motion styles.