 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: Capability-Targeted Agentic Training
Apr 07, 2026Large Language Models (LLMs) deployed in agentic environments must exercise multiple capabilities across different task instances, where a capability is performing one or more actions in a trajectory that are necessary for successfully solving a subset of tasks in the environment. Many existing approaches either rely on synthetic training data that is not targeted to the model's actual capability deficits in the target environment or train directly on the target environment, where the model needs to implicitly learn the capabilities across tasks. We introduce TRACE (Turning Recurrent Agent failures into Capability-targeted training Environments), an end-to-end system for environment-specific agent self-improvement. TRACE contrasts successful and failed trajectories to automatically identify lacking capabilities, synthesizes a targeted training environment for each that rewards whether the capability was exercised, and trains a LoRA adapter via RL on each synthetic environment, routing to the relevant adapter at inference. Empirically, TRACE generalizes across different environments, improving over the base agent by +14.1 points on $τ^2$-bench (customer service) and +7 perfect scores on ToolSandbox (tool use), outperforming the strongest baseline by +7.4 points and +4 perfect scores, respectively. Given the same number of rollouts, TRACE scales more efficiently than baselines, outperforming GRPO and GEPA by +9.2 and +7.4 points on $τ^2$-bench.
TRAP: Targeted Redirecting of Agentic Preferences
May 29, 2025



Autonomous agentic AI systems powered by vision-language models (VLMs) are rapidly advancing toward real-world deployment, yet their cross-modal reasoning capabilities introduce new attack surfaces for adversarial manipulation that exploit semantic reasoning across modalities. Existing adversarial attacks typically rely on visible pixel perturbations or require privileged model or environment access, making them impractical for stealthy, real-world exploitation. We introduce TRAP, a generative adversarial framework that manipulates the agent's decision-making using diffusion-based semantic injections. Our method combines negative prompt-based degradation with positive semantic optimization, guided by a Siamese semantic network and layout-aware spatial masking. Without requiring access to model internals, TRAP produces visually natural images yet induces consistent selection biases in agentic AI systems. We evaluate TRAP on the Microsoft Common Objects in Context (COCO) dataset, building multi-candidate decision scenarios. Across these scenarios, TRAP achieves a 100% attack success rate on leading models, including LLaVA-34B, Gemma3, and Mistral-3.1, significantly outperforming baselines such as SPSA, Bandit, and standard diffusion approaches. These results expose a critical vulnerability: Autonomous agents can be consistently misled through human-imperceptible cross-modal manipulations. These findings highlight the need for defense strategies beyond pixel-level robustness to address semantic vulnerabilities in cross-modal decision-making.
Learning a Pessimistic Reward Model in RLHF
May 26, 2025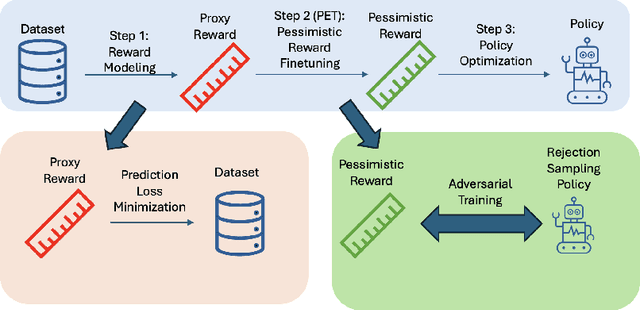

This work proposes `PET', a novel pessimistic reward fine-tuning method, to learn a pessimistic reward model robust against reward hacking in offline reinforcement learning from human feedback (RLHF). Traditional reward modeling techniques in RLHF train an imperfect reward model, on which a KL regularization plays a pivotal role in mitigating reward hacking when optimizing a policy. Such an intuition-based method still suffers from reward hacking, and the policies with large KL divergence from the dataset distribution are excluded during learning. In contrast, we show that when optimizing a policy on a pessimistic reward model fine-tuned through PET, reward hacking can be prevented without relying on any regularization. We test our methods on the standard TL;DR summarization dataset. We find that one can learn a high-quality policy on our pessimistic reward without using any regularization. Such a policy has a high KL divergence from the dataset distribution while having high performance in practice. In summary, our work shows the feasibility of learning a pessimistic reward model against reward hacking. The agent can greedily search for the policy with a high pessimistic reward without suffering from reward hacking.
Stochastic Monkeys at Play: Random Augmentations Cheaply Break LLM Safety Alignment
Nov 05, 2024



Safety alignment of Large Language Models (LLMs) has recently become a critical objective of model developers. In response, a growing body of work has been investigating how safety alignment can be bypassed through various jailbreaking methods, such as adversarial attacks. However, these jailbreak methods can be rather costly or involve a non-trivial amount of creativity and effort, introducing the assumption that malicious users are high-resource or sophisticated. In this paper, we study how simple random augmentations to the input prompt affect safety alignment effectiveness in state-of-the-art LLMs, such as Llama 3 and Qwen 2. We perform an in-depth evaluation of 17 different models and investigate the intersection of safety under random augmentations with multiple dimensions: augmentation type, model size, quantization, fine-tuning-based defenses, and decoding strategies (e.g., sampling temperature). We show that low-resource and unsophisticated attackers, i.e. $\textit{stochastic monkeys}$, can significantly improve their chances of bypassing alignment with just 25 random augmentations per prompt.
Improving LLM Code Generation with Grammar Augmentation
Mar 03, 2024We present SynCode a novel framework for efficient and general syntactical decoding of code with large language models (LLMs). SynCode leverages the grammar of a programming language, utilizing an offline-constructed efficient lookup table called DFA mask store based on language grammar terminals. We demonstrate SynCode's soundness and completeness given the context-free grammar (CFG) of the programming language, presenting its ability to retain syntactically valid tokens while rejecting invalid ones. The framework seamlessly integrates with any language defined by CFG, as evidenced by experiments on CFGs for Python and Go. The results underscore the significant reduction of 96.07% of syntax errors achieved when SynCode is combined with state-of-the-art LLMs, showcasing its substantial impact on enhancing syntactical precision in code generation. Our code is available at https://github.com/uiuc-focal-lab/syncode.