 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEGASUS: Personalized Generative 3D Avatars with Composable Attributes
Feb 16, 2024We present, PEGASUS, a method for constructing personalized generative 3D face avatars from monocular video sources. As a compositional generative model, our model enables disentangled controls to selectively alter the facial attributes (e.g., hair or nose) of the target individual, while preserving the identity. We present two key approaches to achieve this goal. First, we present a method to construct a person-specific generative 3D avatar by building a synthetic video collection of the target identity with varying facial attributes, where the videos are synthesized by borrowing parts from diverse individuals from other monocular videos. Through several experiments, we demonstrate the superior performance of our approach by generating unseen attributes with high realism. Subsequently, we introduce a zero-shot approach to achieve the same generative modeling more efficiently by leveraging a previously constructed personalized generative model.
Zero-Shot Learning for the Primitives of 3D Affordance in General Objects
Jan 24, 2024



One of the major challenges in AI is teaching machines to precisely respond and utilize environmental functionalities, thereby achieving the affordance awareness that humans possess. Despite its importance, the field has been lagging in terms of learning, especially in 3D, as annotating affordance accompanies a laborious process due to the numerous variations of human-object interaction. The low availability of affordance data limits the learning in terms of generalization for object categories, and also simplifies the representation of affordance, capturing only a fraction of the affordance. To overcome these challenges, we propose a novel, self-supervised method to generate the 3D affordance examples given only a 3D object, without any manual annotations. The method starts by capturing the 3D object into images and creating 2D affordance images by inserting humans into the image via inpainting diffusion models, where we present the Adaptive Mask algorithm to enable human insertion without altering the original details of the object. The method consequently lifts inserted humans back to 3D to create 3D human-object pairs, where the depth ambiguity is resolved within a depth optimization framework that utilizes pre-generated human postures from multiple viewpoints. We also provide a novel affordance representation defined on relative orientations and proximity between dense human and object points, that can be easily aggregated from any 3D HOI datasets. The proposed representation serves as a primitive that can be manifested to conventional affordance representations via simple transformations, ranging from physically exerted affordances to nonphysical ones. We demonstrate the efficacy of our method and representation by generating the 3D affordance samples and deriving high-quality affordance examples from the representation, including contact, orientation, and spatial occupancies.
GALA: Generating Animatable Layered Assets from a Single Scan
Jan 23, 2024We present GALA, a framework that takes as input a single-layer clothed 3D human mesh and decomposes it into complete multi-layered 3D assets. The outputs can then be combined with other assets to create novel clothed human avatars with any pose. Existing reconstruction approaches often treat clothed humans as a single-layer of geometry and overlook the inherent compositionality of humans with hairstyles, clothing, and accessories, thereby limiting the utility of the meshes for downstream applications. Decomposing a single-layer mesh into separate layers is a challenging task because it requires the synthesis of plausible geometry and texture for the severely occluded regions. Moreover, even with successful decomposition, meshes are not normalized in terms of poses and body shapes, failing coherent composition with novel identities and poses. To address these challenges, we propose to leverage the general knowledge of a pretrained 2D diffusion model as geometry and appearance prior for humans and other assets. We first separate the input mesh using the 3D surface segmentation extracted from multi-view 2D segmentations. Then we synthesize the missing geometry of different layers in both posed and canonical spaces using a novel pose-guided Score Distillation Sampling (SDS) loss. Once we complete inpainting high-fidelity 3D geometry, we also apply the same SDS loss to its texture to obtain the complete appearance including the initially occluded regions. Through a series of decomposition steps, we obtain multiple layers of 3D assets in a shared canonical space normalized in terms of poses and human shapes, hence supporting effortless composition to novel identities and reanimation with novel poses. Our experiments demonstrate the effectiveness of our approach for decomposition, canonicalization, and composition tasks compared to existing solutions.
ParaHome: Parameterizing Everyday Home Activities Towards 3D Generative Modeling of Human-Object Interactions
Jan 18, 2024To enable machines to learn how humans interact with the physical world in our daily activities, it is crucial to provide rich data that encompasses the 3D motion of humans as well as the motion of objects in a learnable 3D representation. Ideally, this data should be collected in a natural setup, capturing the authentic dynamic 3D signals during human-object interactions. To address this challenge, we introduce the ParaHome system, designed to capture and parameterize dynamic 3D movements of humans and objects within a common home environment. Our system consists of a multi-view setup with 70 synchronized RGB cameras, as well as wearable motion capture devices equipped with an IMU-based body suit and hand motion capture gloves. By leveraging the ParaHome system, we collect a novel large-scale dataset of human-object interaction. Notably, our dataset offers key advancement over existing datasets in three main aspects: (1) capturing 3D body and dexterous hand manipulation motion alongside 3D object movement within a contextual home environment during natural activities; (2) encompassing human interaction with multiple objects in various episodic scenarios with corresponding descriptions in texts; (3) including articulated objects with multiple parts expressed with parameterized articulations. Building upon our dataset, we introduce new research tasks aimed at building a generative model for learning and synthesizing human-object interactions in a real-world room setting.
Mocap Everyone Everywhere: Lightweight Motion Capture With Smartwatches and a Head-Mounted Camera
Jan 01, 2024



We present a lightweight and affordable motion capture method based on two smartwatches and a head-mounted camera. In contrast to the existing approaches that use six or more expert-level IMU devices, our approach is much more cost-effective and convenient. Our method can make wearable motion capture accessible to everyone everywhere, enabling 3D full-body motion capture in diverse environments. As a key idea to overcome the extreme sparsity and ambiguities of sensor inputs, we integrate 6D head poses obtained from the head-mounted cameras for motion estimation. To enable capture in expansive indoor and outdoor scenes, we propose an algorithm to track and update floor level changes to define head poses, coupled with a multi-stage Transformer-based regression module. We also introduce novel strategies leveraging visual cues of egocentric images to further enhance the motion capture quality while reducing ambiguities. We demonstrate the performance of our method on various challenging scenarios, including complex outdoor environments and everyday motions including object interactions and social interactions among multiple individuals.
CHORUS: Learning Canonicalized 3D Human-Object Spatial Relations from Unbounded Synthesized Images
Sep 03, 2023We present a method for teaching machines to understand and model the underlying spatial common sense of diverse human-object interactions in 3D in a self-supervised way. This is a challenging task, as there exist specific manifolds of the interactions that can be considered human-like and natural, but the human pose and the geometry of objects can vary even for similar interactions. Such diversity makes the annotating task of 3D interactions difficult and hard to scale, which limits the potential to reason about that in a supervised way. One way of learning the 3D spatial relationship between humans and objects during interaction is by showing multiple 2D images captured from different viewpoints when humans interact with the same type of objects. The core idea of our method is to leverage a generative model that produces high-quality 2D images from an arbitrary text prompt input as an "unbounded" data generator with effective controllability and view diversity. Despite its imperfection of the image quality over real images, we demonstrate that the synthesized images are sufficient to learn the 3D human-object spatial relations. We present multiple strategies to leverage the synthesized images, including (1) the first method to leverage a generative image model for 3D human-object spatial relation learning; (2) a framework to reason about the 3D spatial relations from inconsistent 2D cues in a self-supervised manner via 3D occupancy reasoning with pose canonicalization; (3) semantic clustering to disambiguate different types of interactions with the same object types; and (4) a novel metric to assess the quality of 3D spatial learning of interaction.
NCHO: Unsupervised Learning for Neural 3D Composition of Humans and Objects
May 23, 2023Deep generative models have been recently extended to synthesizing 3D digital humans. However, previous approaches treat clothed humans as a single chunk of geometry without considering the compositionality of clothing and accessories. As a result, individual items cannot be naturally composed into novel identities, leading to limited expressiveness and controllability of generative 3D avatars. While several methods attempt to address this by leveraging synthetic data, the interaction between humans and objects is not authentic due to the domain gap, and manual asset creation is difficult to scale for a wide variety of objects. In this work, we present a novel framework for learning a compositional generative model of humans and objects (backpacks, coats, scarves, and more) from real-world 3D scans. Our compositional model is interaction-aware, meaning the spatial relationship between humans and objects, and the mutual shape change by physical contact is fully incorporated. The key challenge is that, since humans and objects are in contact, their 3D scans are merged into a single piece. To decompose them without manual annotations, we propose to leverage two sets of 3D scans of a single person with and without objects. Our approach learns to decompose objects and naturally compose them back into a generative human model in an unsupervised manner. Despite our simple setup requiring only the capture of a single subject with objects, our experiments demonstrate the strong generalization of our model by enabling the natural composition of objects to diverse identities in various poses and the composition of multiple objects, which is unseen in training data.
Chupa: Carving 3D Clothed Humans from Skinned Shape Priors using 2D Diffusion Probabilistic Models
May 19, 2023



We propose a 3D generation pipeline that uses diffusion models to generate realistic human digital avatars. Due to the wide variety of human identities, poses, and stochastic details, the generation of 3D human meshes has been a challenging problem. To address this, we decompose the problem into 2D normal map generation and normal map-based 3D reconstruction. Specifically, we first simultaneously generate realistic normal maps for the front and backside of a clothed human, dubbed dual normal maps, using a pose-conditional diffusion model. For 3D reconstruction, we ``carve'' the prior SMPL-X mesh to a detailed 3D mesh according to the normal maps through mesh optimization. To further enhance the high-frequency details, we present a diffusion resampling scheme on both body and facial regions, thus encouraging the generation of realistic digital avatars. We also seamlessly incorporate a recent text-to-image diffusion model to support text-based human identity control. Our method, namely, Chupa, is capable of generating realistic 3D clothed humans with better perceptual quality and identity variety.
Locomotion-Action-Manipulation: Synthesizing Human-Scene Interactions in Complex 3D Environments
Jan 09, 2023



Synthesizing interaction-involved human motions has been challenging due to the high complexity of 3D environments and the diversity of possible human behaviors within. We present LAMA, Locomotion-Action-MAnipulation, to synthesize natural and plausible long term human movements in complex indoor environments. The key motivation of LAMA is to build a unified framework to encompass a series of motions commonly observable in our daily lives, including locomotion, interactions with 3D scenes, and manipulations of 3D objects. LAMA is based on a reinforcement learning framework coupled with a motion matching algorithm to synthesize locomotion and scene interaction seamlessly under common constraints and collision avoidance handling. LAMA also exploits a motion editing framework via manifold learning to cover possible variations in interaction and manipulation motions. We quantitatively and qualitatively demonstrate that LAMA outperforms existing approaches in various challenging scenarios. Project webpage: https://lama-www.github.io/ .
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion
Apr 18, 2022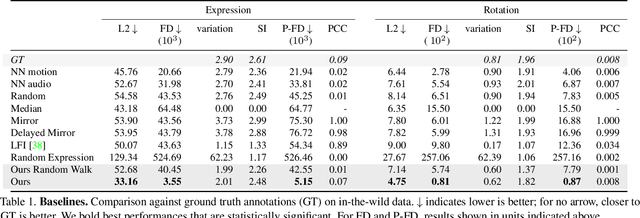
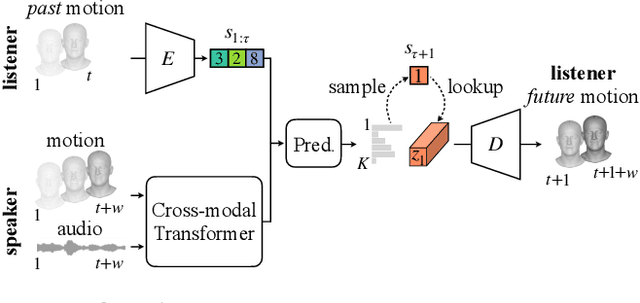
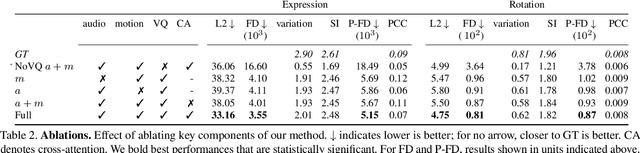
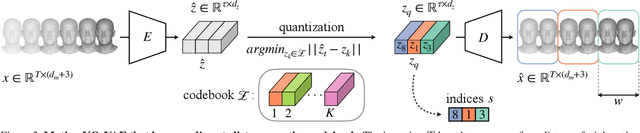
We present a framework for modeling interactional communication in dyadic conversations: given multimodal inputs of a speaker, we autoregressively output multiple possibilities of corresponding listener motion. We combine the motion and speech audio of the speaker using a motion-audio cross attention transformer. Furthermore, we enable non-deterministic prediction by learning a discrete latent representation of realistic listener motion with a novel motion-encoding VQ-VAE. Our method organically captures the multimodal and non-deterministic nature of nonverbal dyadic interactions. Moreover, it produces realistic 3D listener facial motion synchronous with the speaker (see video). We demonstrate that our method outperforms baselines qualitatively and quantitatively via a rich suite of experiments. To facilitate this line of research, we introduce a novel and large in-the-wild dataset of dyadic conversations. Code, data, and videos available at https://evonneng.github.io/learning2listen/.