 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama See, Llama Do: A Mechanistic Perspective on Contextual Entrainment and Distraction in LLMs
May 14, 2025We observe a novel phenomenon, contextual entrainment, across a wide range of language models (LMs) and prompt settings, providing a new mechanistic perspective on how LMs become distracted by ``irrelevant'' contextual information in the input prompt. Specifically, LMs assign significantly higher logits (or probabilities) to any tokens that have previously appeared in the context prompt, even for random tokens. This suggests that contextual entrainment is a mechanistic phenomenon, occurring independently of the relevance or semantic relation of the tokens to the question or the rest of the sentence. We find statistically significant evidence that the magnitude of contextual entrainment is influenced by semantic factors. Counterfactual prompts have a greater effect compared to factual ones, suggesting that while contextual entrainment is a mechanistic phenomenon, it is modulated by semantic factors. We hypothesise that there is a circuit of attention heads -- the entrainment heads -- that corresponds to the contextual entrainment phenomenon. Using a novel entrainment head discovery method based on differentiable masking, we identify these heads across various settings. When we ``turn off'' these heads, i.e., set their outputs to zero, the effect of contextual entrainment is significantly attenuated, causing the model to generate output that capitulates to what it would produce if no distracting context were provided. Our discovery of contextual entrainment, along with our investigation into LM distraction via the entrainment heads, marks a key step towards the mechanistic analysis and mitigation of the distraction problem.
Robust Candidate Generation for Entity Linking on Short Social Media Texts
Oct 14, 2022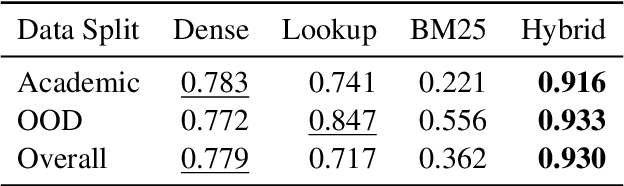
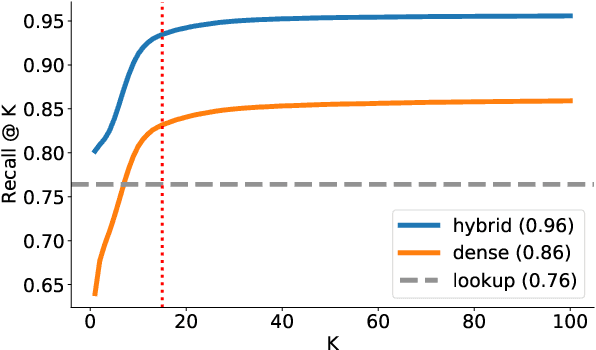
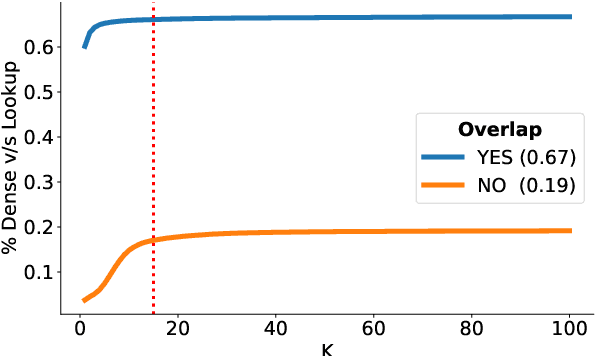
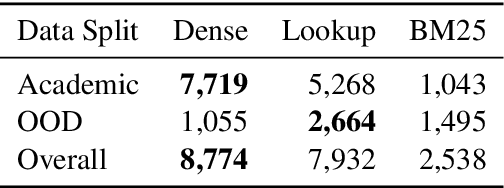
Entity Linking (EL) is the gateway into Knowledge Bases. Recent advances in EL utilize dense retrieval approaches for Candidate Generation, which addresses some of the shortcomings of the Lookup based approach of matching NER mentions against pre-computed dictionaries. In this work, we show that in the domain of Tweets, such methods suffer as users often include informal spelling, limited context, and lack of specificity, among other issues. We investigate these challenges on a large and recent Tweets benchmark for EL, empirically evaluate lookup and dense retrieval approaches, and demonstrate a hybrid solution using long contextual representation from Wikipedia is necessary to achieve considerable gains over previous work, achieving 0.93 recall.
A Cross-Domain Transferable Neural Coherence Model
May 28, 2019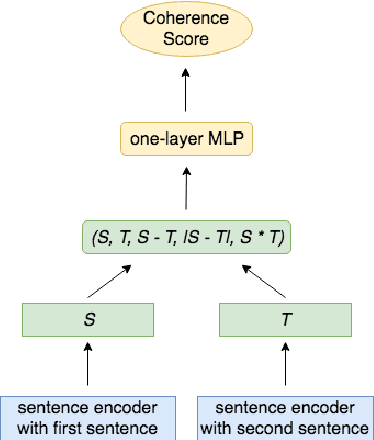
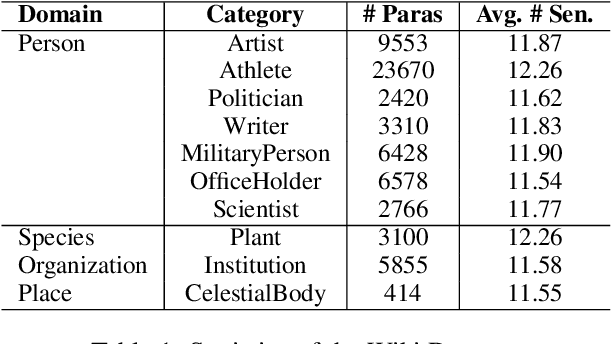
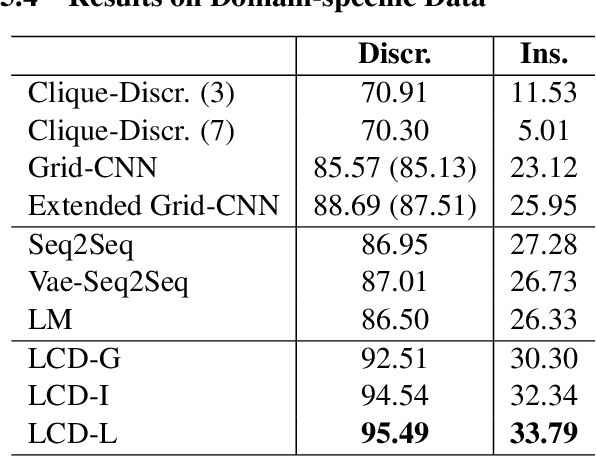
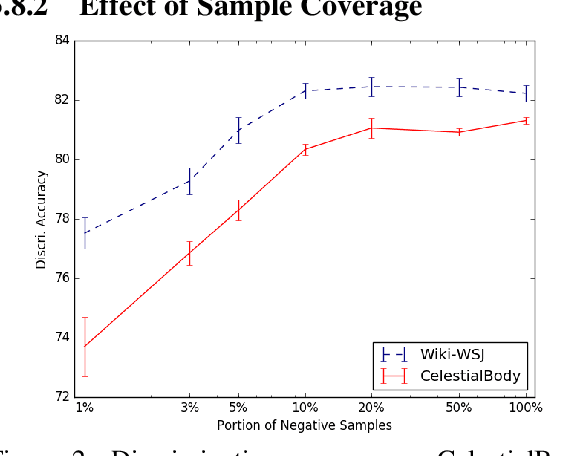
Coherence is an important aspect of text quality and is crucial for ensuring its readability. One important limitation of existing coherence models is that training on one domain does not easily generalize to unseen categories of text. Previous work advocates for generative models for cross-domain generalization, because for discriminative models, the space of incoherent sentence orderings to discriminate against during training is prohibitively large. In this work, we propose a local discriminative neural model with a much smaller negative sampling space that can efficiently learn against incorrect orderings. The proposed coherence model is simple in structure, yet it significantly outperforms previous state-of-art methods on a standard benchmark dataset on the Wall Street Journal corpus, as well as in multiple new challenging settings of transfer to unseen categories of discourse on Wikipedia articles.