 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGASTON: Graph-Aware Social Transformer for Online Networks
Jan 26, 2026Online communities have become essential places for socialization and support, yet they also possess toxicity, echo chambers, and misinformation. Detecting this harmful content is difficult because the meaning of an online interaction stems from both what is written (textual content) and where it is posted (social norms). We propose GASTON (Graph-Aware Social Transformer for Online Networks), which learns text and user embeddings that are grounded in their local norms, providing the necessary context for downstream tasks. The heart of our solution is a contrastive initialization strategy that pretrains community embeddings based on user membership patterns, capturing a community's user base before processing any text. This allows GASTON to distinguish between communities (e.g., a support group vs. a hate group) based on who interacts there, even if they share similar vocabulary. Experiments on tasks such as stress detection, toxicity scoring, and norm violation demonstrate that the embeddings produced by GASTON outperform state-of-the-art baselines.
Community Norms in the Spotlight: Enabling Task-Agnostic Unsupervised Pre-Training to Benefit Online Social Media
Jan 26, 2026Modelling the complex dynamics of online social platforms is critical for addressing challenges such as hate speech and misinformation. While Discussion Transformers, which model conversations as graph structures, have emerged as a promising architecture, their potential is severely constrained by reliance on high-quality, human-labelled datasets. In this paper, we advocate a paradigm shift from task-specific fine-tuning to unsupervised pretraining, grounded in an entirely novel consideration of community norms. We posit that this framework not only mitigates data scarcity but also enables interpretation of the social norms underlying the decisions made by such an AI system. Ultimately, we believe that this direction offers many opportunities for AI for Social Good.
REGEN: A Dataset and Benchmarks with Natural Language Critiques and Narratives
Mar 14, 2025This paper introduces a novel dataset REGEN (Reviews Enhanced with GEnerative Narratives), designed to benchmark the conversational capabilities of recommender Large Language Models (LLMs), addressing the limitations of existing datasets that primarily focus on sequential item prediction. REGEN extends the Amazon Product Reviews dataset by inpainting two key natural language features: (1) user critiques, representing user "steering" queries that lead to the selection of a subsequent item, and (2) narratives, rich textual outputs associated with each recommended item taking into account prior context. The narratives include product endorsements, purchase explanations, and summaries of user preferences. Further, we establish an end-to-end modeling benchmark for the task of conversational recommendation, where models are trained to generate both recommendations and corresponding narratives conditioned on user history (items and critiques). For this joint task, we introduce a modeling framework LUMEN (LLM-based Unified Multi-task Model with Critiques, Recommendations, and Narratives) which uses an LLM as a backbone for critiquing, retrieval and generation. We also evaluate the dataset's quality using standard auto-rating techniques and benchmark it by training both traditional and LLM-based recommender models. Our results demonstrate that incorporating critiques enhances recommendation quality by enabling the recommender to learn language understanding and integrate it with recommendation signals. Furthermore, LLMs trained on our dataset effectively generate both recommendations and contextual narratives, achieving performance comparable to state-of-the-art recommenders and language models.
Beyond Retrieval: Generating Narratives in Conversational Recommender Systems
Oct 22, 2024



The recent advances in Large Language Model's generation and reasoning capabilities present an opportunity to develop truly conversational recommendation systems. However, effectively integrating recommender system knowledge into LLMs for natural language generation which is tailored towards recommendation tasks remains a challenge. This paper addresses this challenge by making two key contributions. First, we introduce a new dataset (REGEN) for natural language generation tasks in conversational recommendations. REGEN (Reviews Enhanced with GEnerative Narratives) extends the Amazon Product Reviews dataset with rich user narratives, including personalized explanations of product preferences, product endorsements for recommended items, and summaries of user purchase history. REGEN is made publicly available to facilitate further research. Furthermore, we establish benchmarks using well-known generative metrics, and perform an automated evaluation of the new dataset using a rater LLM. Second, the paper introduces a fusion architecture (CF model with an LLM) which serves as a baseline for REGEN. And to the best of our knowledge, represents the first attempt to analyze the capabilities of LLMs in understanding recommender signals and generating rich narratives. We demonstrate that LLMs can effectively learn from simple fusion architectures utilizing interaction-based CF embeddings, and this can be further enhanced using the metadata and personalization data associated with items. Our experiments show that combining CF and content embeddings leads to improvements of 4-12% in key language metrics compared to using either type of embedding individually. We also provide an analysis to interpret how CF and content embeddings contribute to this new generative task.
FLARE: Fusing Language Models and Collaborative Architectures for Recommender Enhancement
Sep 18, 2024



Hybrid recommender systems, combining item IDs and textual descriptions, offer potential for improved accuracy. However, previous work has largely focused on smaller datasets and model architectures. This paper introduces Flare (Fusing Language models and collaborative Architectures for Recommender Enhancement), a novel hybrid recommender that integrates a language model (mT5) with a collaborative filtering model (Bert4Rec) using a Perceiver network. This architecture allows Flare to effectively combine collaborative and content information for enhanced recommendations. We conduct a two-stage evaluation, first assessing Flare's performance against established baselines on smaller datasets, where it demonstrates competitive accuracy. Subsequently, we evaluate Flare on a larger, more realistic dataset with a significantly larger item vocabulary, introducing new baselines for this setting. Finally, we showcase Flare's inherent ability to support critiquing, enabling users to provide feedback and refine recommendations. We further leverage critiquing as an evaluation method to assess the model's language understanding and its transferability to the recommendation task.
PERSOMA: PERsonalized SOft ProMpt Adapter Architecture for Personalized Language Prompting
Aug 02, 2024



Understanding the nuances of a user's extensive interaction history is key to building accurate and personalized natural language systems that can adapt to evolving user preferences. To address this, we introduce PERSOMA, Personalized Soft Prompt Adapter architecture. Unlike previous personalized prompting methods for large language models, PERSOMA offers a novel approach to efficiently capture user history. It achieves this by resampling and compressing interactions as free form text into expressive soft prompt embeddings, building upon recent research utilizing embedding representations as input for LLMs. We rigorously validate our approach by evaluating various adapter architectures, first-stage sampling strategies, parameter-efficient tuning techniques like LoRA, and other personalization methods. Our results demonstrate PERSOMA's superior ability to handle large and complex user histories compared to existing embedding-based and text-prompt-based techniques.
Multi-Modal Discussion Transformer: Integrating Text, Images and Graph Transformers to Detect Hate Speech on Social Media
Jul 18, 2023



We present the Multi-Modal Discussion Transformer (mDT), a novel multi-modal graph-based transformer model for detecting hate speech in online social networks. In contrast to traditional text-only methods, our approach to labelling a comment as hate speech centers around the holistic analysis of text and images. This is done by leveraging graph transformers to capture the contextual relationships in the entire discussion that surrounds a comment, with interwoven fusion layers to combine text and image embeddings instead of processing different modalities separately. We compare the performance of our model to baselines that only process text; we also conduct extensive ablation studies. We conclude with future work for multimodal solutions to deliver social value in online contexts, arguing that capturing a holistic view of a conversation greatly advances the effort to detect anti-social behavior.
Qualitative Analysis of a Graph Transformer Approach to Addressing Hate Speech: Adapting to Dynamically Changing Content
Jan 25, 2023Our work advances an approach for predicting hate speech in social media, drawing out the critical need to consider the discussions that follow a post to successfully detect when hateful discourse may arise. Using graph transformer networks, coupled with modelling attention and BERT-level natural language processing, our approach can capture context and anticipate upcoming anti-social behaviour. In this paper, we offer a detailed qualitative analysis of this solution for hate speech detection in social networks, leading to insights into where the method has the most impressive outcomes in comparison with competitors and identifying scenarios where there are challenges to achieving ideal performance. Included is an exploration of the kinds of posts that permeate social media today, including the use of hateful images. This suggests avenues for extending our model to be more comprehensive. A key insight is that the focus on reasoning about the concept of context positions us well to be able to support multi-modal analysis of online posts. We conclude with a reflection on how the problem we are addressing relates especially well to the theme of dynamic change, a critical concern for all AI solutions for social impact. We also comment briefly on how mental health well-being can be advanced with our work, through curated content attuned to the extent of hate in posts.
Predicting Hateful Discussions on Reddit using Graph Transformer Networks and Communal Context
Jan 10, 2023We propose a system to predict harmful discussions on social media platforms. Our solution uses contextual deep language models and proposes the novel idea of integrating state-of-the-art Graph Transformer Networks to analyze all conversations that follow an initial post. This framework also supports adapting to future comments as the conversation unfolds. In addition, we study whether a community-specific analysis of hate speech leads to more effective detection of hateful discussions. We evaluate our approach on 333,487 Reddit discussions from various communities. We find that community-specific modeling improves performance two-fold and that models which capture wider-discussion context improve accuracy by 28\% (35\% for the most hateful content) compared to limited context models.
Robust Candidate Generation for Entity Linking on Short Social Media Texts
Oct 14, 2022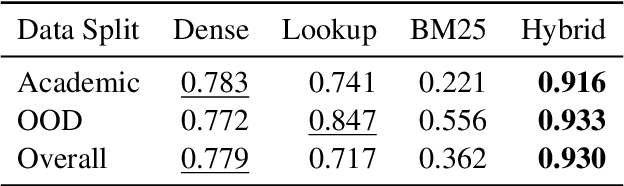
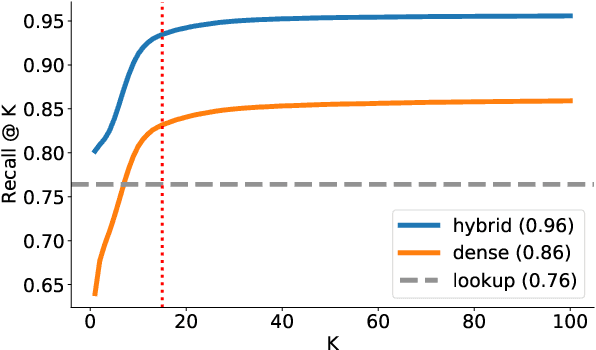
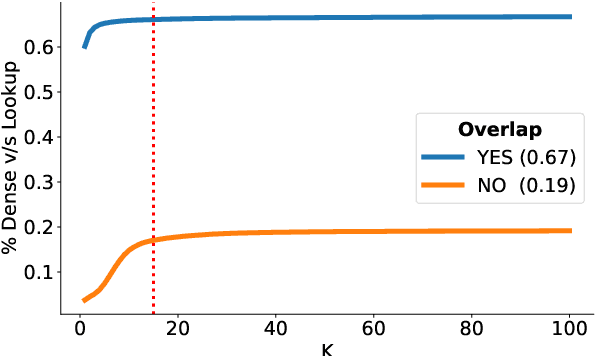
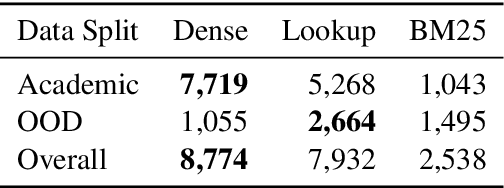
Entity Linking (EL) is the gateway into Knowledge Bases. Recent advances in EL utilize dense retrieval approaches for Candidate Generation, which addresses some of the shortcomings of the Lookup based approach of matching NER mentions against pre-computed dictionaries. In this work, we show that in the domain of Tweets, such methods suffer as users often include informal spelling, limited context, and lack of specificity, among other issues. We investigate these challenges on a large and recent Tweets benchmark for EL, empirically evaluate lookup and dense retrieval approaches, and demonstrate a hybrid solution using long contextual representation from Wikipedia is necessary to achieve considerable gains over previous work, achieving 0.93 recall.