 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUplifting Range-View-based 3D Semantic Segmentation in Real-Time with Multi-Sensor Fusion
Jul 12, 2024



Range-View(RV)-based 3D point cloud segmentation is widely adopted due to its compact data form. However, RV-based methods fall short in providing robust segmentation for the occluded points and suffer from distortion of projected RGB images due to the sparse nature of 3D point clouds. To alleviate these problems, we propose a new LiDAR and Camera Range-view-based 3D point cloud semantic segmentation method (LaCRange). Specifically, a distortion-compensating knowledge distillation (DCKD) strategy is designed to remedy the adverse effect of RV projection of RGB images. Moreover, a context-based feature fusion module is introduced for robust and preservative sensor fusion. Finally, in order to address the limited resolution of RV and its insufficiency of 3D topology, a new point refinement scheme is devised for proper aggregation of features in 2D and augmentation of point features in 3D. We evaluated the proposed method on large-scale autonomous driving datasets \ie SemanticKITTI and nuScenes. In addition to being real-time, the proposed method achieves state-of-the-art results on nuScenes benchmark
AutoSplat: Constrained Gaussian Splatting for Autonomous Driving Scene Reconstruction
Jul 02, 2024



Realistic scene reconstruction and view synthesis are essential for advancing autonomous driving systems by simulating safety-critical scenarios. 3D Gaussian Splatting excels in real-time rendering and static scene reconstructions but struggles with modeling driving scenarios due to complex backgrounds, dynamic objects, and sparse views. We propose AutoSplat, a framework employing Gaussian splatting to achieve highly realistic reconstructions of autonomous driving scenes. By imposing geometric constraints on Gaussians representing the road and sky regions, our method enables multi-view consistent simulation of challenging scenarios including lane changes. Leveraging 3D templates, we introduce a reflected Gaussian consistency constraint to supervise both the visible and unseen side of foreground objects. Moreover, to model the dynamic appearance of foreground objects, we estimate residual spherical harmonics for each foreground Gaussian. Extensive experiments on Pandaset and KITTI demonstrate that AutoSplat outperforms state-of-the-art methods in scene reconstruction and novel view synthesis across diverse driving scenarios. Visit our $\href{https://autosplat.github.io/}{\text{project page}}$.
AOP-Net: All-in-One Perception Network for Joint LiDAR-based 3D Object Detection and Panoptic Segmentation
Feb 02, 2023



LiDAR-based 3D object detection and panoptic segmentation are two crucial tasks in the perception systems of autonomous vehicles and robots. In this paper, we propose All-in-One Perception Network (AOP-Net), a LiDAR-based multi-task framework that combines 3D object detection and panoptic segmentation. In this method, a dual-task 3D backbone is developed to extract both panoptic- and detection-level features from the input LiDAR point cloud. Also, a new 2D backbone that intertwines Multi-Layer Perceptron (MLP) and convolution layers is designed to further improve the detection task performance. Finally, a novel module is proposed to guide the detection head by recovering useful features discarded during down-sampling operations in the 3D backbone. This module leverages estimated instance segmentation masks to recover detailed information from each candidate object. The AOP-Net achieves state-of-the-art performance for published works on the nuScenes benchmark for both 3D object detection and panoptic segmentation tasks. Also, experiments show that our method easily adapts to and significantly improves the performance of any BEV-based 3D object detection method.
A Versatile Multi-View Framework for LiDAR-based 3D Object Detection with Guidance from Panoptic Segmentation
Mar 04, 2022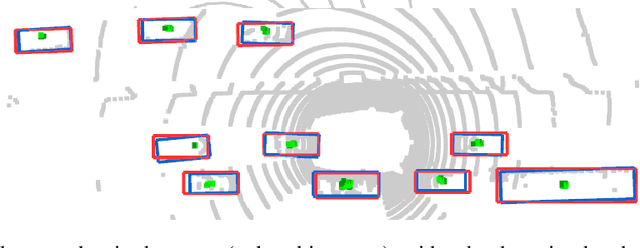
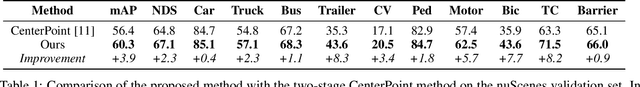
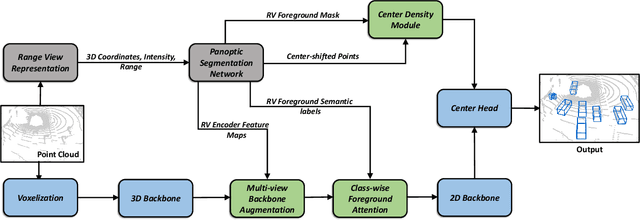
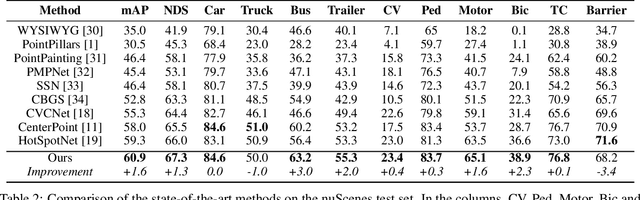
3D object detection using LiDAR data is an indispensable component for autonomous driving systems. Yet, only a few LiDAR-based 3D object detection methods leverage segmentation information to further guide the detection process. In this paper, we propose a novel multi-task framework that jointly performs 3D object detection and panoptic segmentation. In our method, the 3D object detection backbone in Bird's-Eye-View (BEV) plane is augmented by the injection of Range-View (RV) feature maps from the 3D panoptic segmentation backbone. This enables the detection backbone to leverage multi-view information to address the shortcomings of each projection view. Furthermore, foreground semantic information is incorporated to ease the detection task by highlighting the locations of each object class in the feature maps. Finally, a new center density heatmap generated based on the instance-level information further guides the detection backbone by suggesting possible box center locations for objects. Our method works with any BEV-based 3D object detection method, and as shown by extensive experiments on the nuScenes dataset, it provides significant performance gains. Notably, the proposed method based on a single-stage CenterPoint 3D object detection network achieved state-of-the-art performance on nuScenes 3D Detection Benchmark with 67.3 NDS.