 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Aware Adversarial Network in Human Mobility Prediction
Aug 09, 2022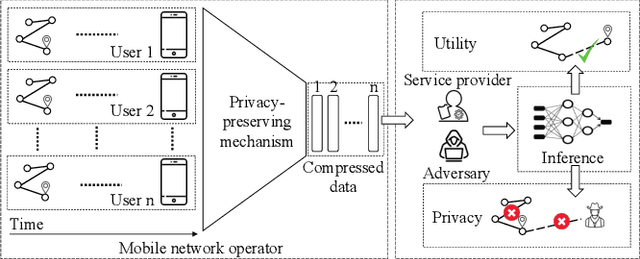
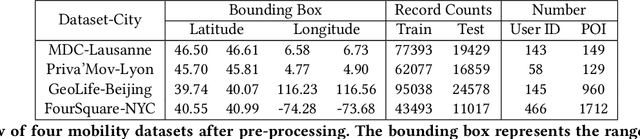
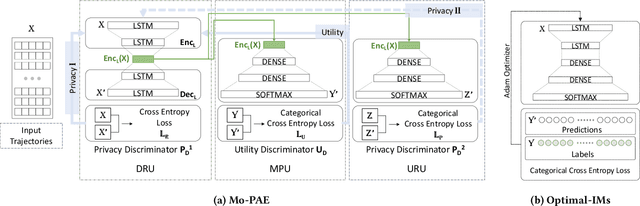
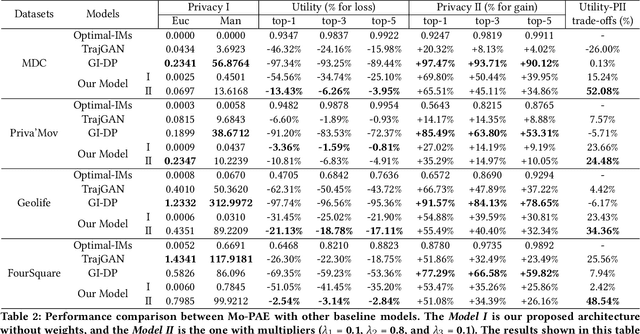
As mobile devices and location-based services are increasingly developed in different smart city scenarios and applications, many unexpected privacy leakages have arisen due to geolocated data collection and sharing. User re-identification and other sensitive inferences are major privacy threats when geolocated data are shared with cloud-assisted applications. Significantly, four spatio-temporal points are enough to uniquely identify 95\% of the individuals, which exacerbates personal information leakages. To tackle malicious purposes such as user re-identification, we propose an LSTM-based adversarial mechanism with representation learning to attain a privacy-preserving feature representation of the original geolocated data (i.e., mobility data) for a sharing purpose. These representations aim to maximally reduce the chance of user re-identification and full data reconstruction with a minimal utility budget (i.e., loss). We train the mechanism by quantifying privacy-utility trade-off of mobility datasets in terms of trajectory reconstruction risk, user re-identification risk, and mobility predictability. We report an exploratory analysis that enables the user to assess this trade-off with a specific loss function and its weight parameters. The extensive comparison results on four representative mobility datasets demonstrate the superiority of our proposed architecture in mobility privacy protection and the efficiency of the proposed privacy-preserving features extractor. We show that the privacy of mobility traces attains decent protection at the cost of marginal mobility utility. Our results also show that by exploring the Pareto optimal setting, we can simultaneously increase both privacy (45%) and utility (32%).
FIB: A Method for Evaluation of Feature Impact Balance in Multi-Dimensional Data
Jul 10, 2022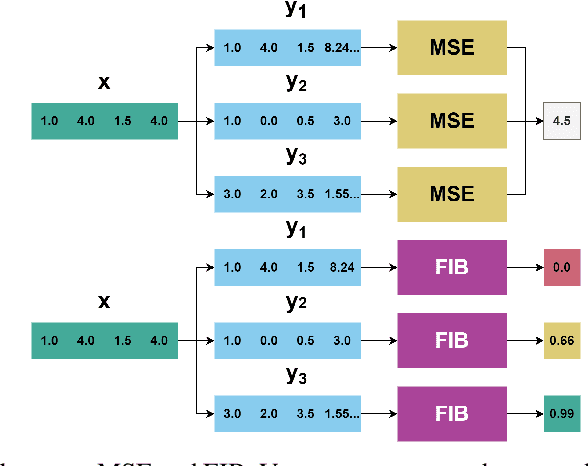

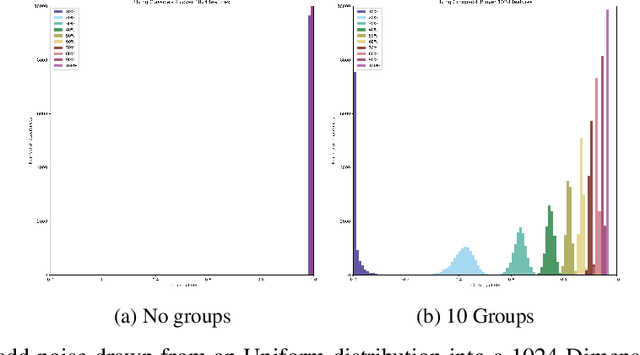
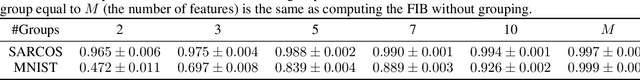
Errors might not have the same consequences depending on the task at hand. Nevertheless, there is limited research investigating the impact of imbalance in the contribution of different features in an error vector. Therefore, we propose the Feature Impact Balance (FIB) score. It measures whether there is a balanced impact of features in the discrepancies between two vectors. We designed the FIB score to lie in [0, 1]. Scores close to 0 indicate that a small number of features contribute to most of the error, and scores close to 1 indicate that most features contribute to the error equally. We experimentally study the FIB on different datasets, using AutoEncoders and Variational AutoEncoders. We show how the feature impact balance varies during training and showcase its usability to support model selection for single output and multi-output tasks.
Distributed data analytics
Mar 26, 2022



Machine Learning (ML) techniques have begun to dominate data analytics applications and services. Recommendation systems are a key component of online service providers. The financial industry has adopted ML to harness large volumes of data in areas such as fraud detection, risk-management, and compliance. Deep Learning is the technology behind voice-based personal assistants, etc. Deployment of ML technologies onto cloud computing infrastructures has benefited numerous aspects of our daily life. The advertising and associated online industries in particular have fuelled a rapid rise the in deployment of personal data collection and analytics tools. Traditionally, behavioural analytics relies on collecting vast amounts of data in centralised cloud infrastructure before using it to train machine learning models that allow user behaviour and preferences to be inferred. A contrasting approach, distributed data analytics, where code and models for training and inference are distributed to the places where data is collected, has been boosted by two recent, ongoing developments: increased processing power and memory capacity available in user devices at the edge of the network, such as smartphones and home assistants; and increased sensitivity to the highly intrusive nature of many of these devices and services and the attendant demands for improved privacy. Indeed, the potential for increased privacy is not the only benefit of distributing data analytics to the edges of the network: reducing the movement of large volumes of data can also improve energy efficiency, helping to ameliorate the ever increasing carbon footprint of our digital infrastructure, enabling much lower latency for service interactions than is possible when services are cloud-hosted. These approaches often introduce challenges in privacy, utility, and efficiency trade-offs, while having to ensure fruitful user engagement.
Towards Battery-Free Machine Learning and Inference in Underwater Environments
Feb 16, 2022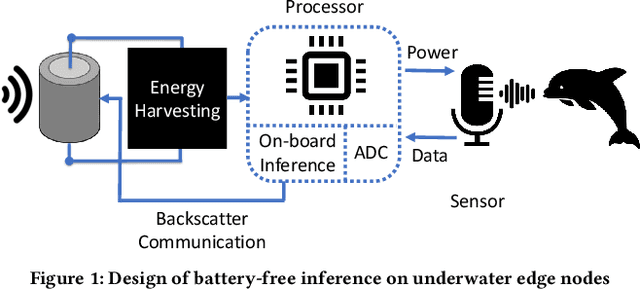
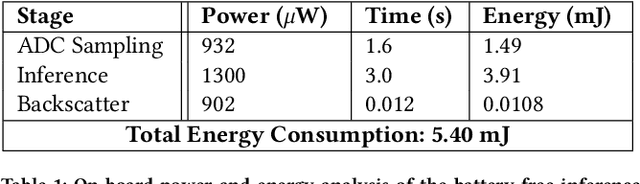
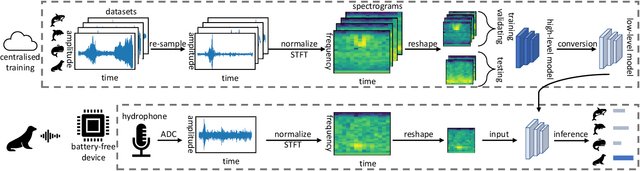

This paper is motivated by a simple question: Can we design and build battery-free devices capable of machine learning and inference in underwater environments? An affirmative answer to this question would have significant implications for a new generation of underwater sensing and monitoring applications for environmental monitoring, scientific exploration, and climate/weather prediction. To answer this question, we explore the feasibility of bridging advances from the past decade in two fields: battery-free networking and low-power machine learning. Our exploration demonstrates that it is indeed possible to enable battery-free inference in underwater environments. We designed a device that can harvest energy from underwater sound, power up an ultra-low-power microcontroller and on-board sensor, perform local inference on sensed measurements using a lightweight Deep Neural Network, and communicate the inference result via backscatter to a receiver. We tested our prototype in an emulated marine bioacoustics application, demonstrating the potential to recognize underwater animal sounds without batteries. Through this exploration, we highlight the challenges and opportunities for making underwater battery-free inference and machine learning ubiquitous.
Privacy-Aware Human Mobility Prediction via Adversarial Networks
Jan 19, 2022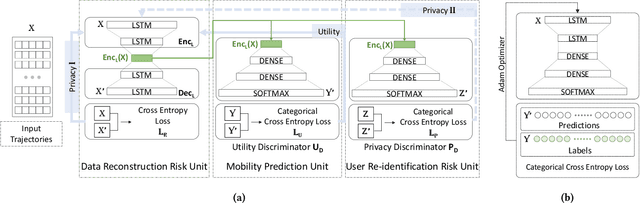

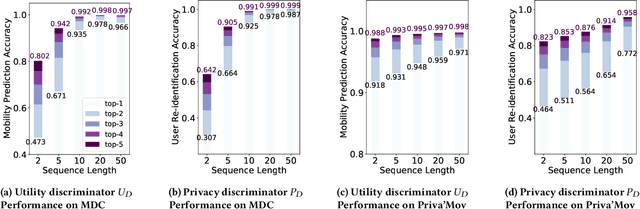
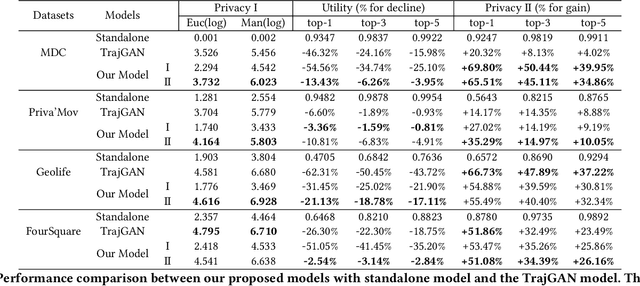
As various mobile devices and location-based services are increasingly developed in different smart city scenarios and applications, many unexpected privacy leakages have arisen due to geolocated data collection and sharing. While these geolocated data could provide a rich understanding of human mobility patterns and address various societal research questions, privacy concerns for users' sensitive information have limited their utilization. In this paper, we design and implement a novel LSTM-based adversarial mechanism with representation learning to attain a privacy-preserving feature representation of the original geolocated data (mobility data) for a sharing purpose. We quantify the utility-privacy trade-off of mobility datasets in terms of trajectory reconstruction risk, user re-identification risk, and mobility predictability. Our proposed architecture reports a Pareto Frontier analysis that enables the user to assess this trade-off as a function of Lagrangian loss weight parameters. The extensive comparison results on four representative mobility datasets demonstrate the superiority of our proposed architecture and the efficiency of the proposed privacy-preserving features extractor. Our results show that by exploring Pareto optimal setting, we can simultaneously increase both privacy (45%) and utility (32%).
Rapid IoT Device Identification at the Edge
Oct 26, 2021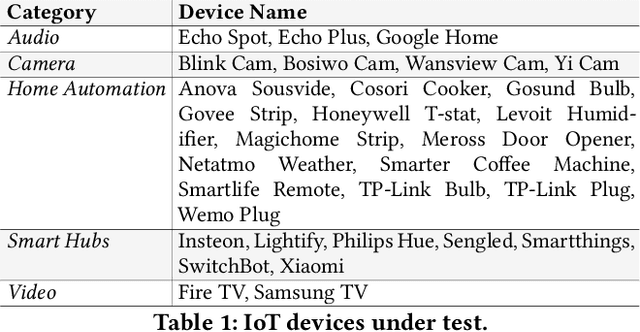
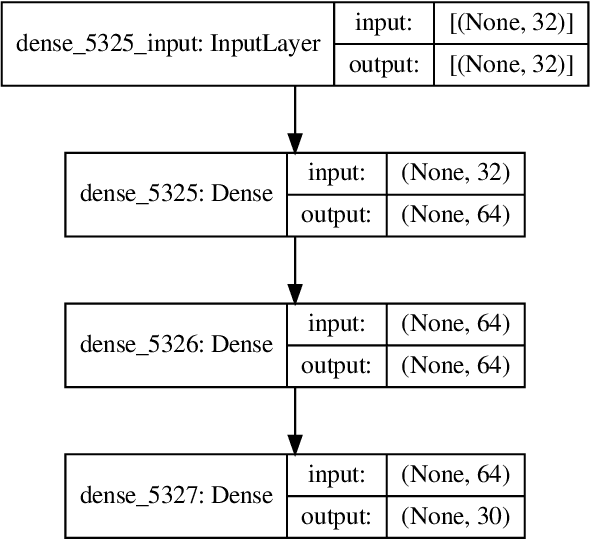
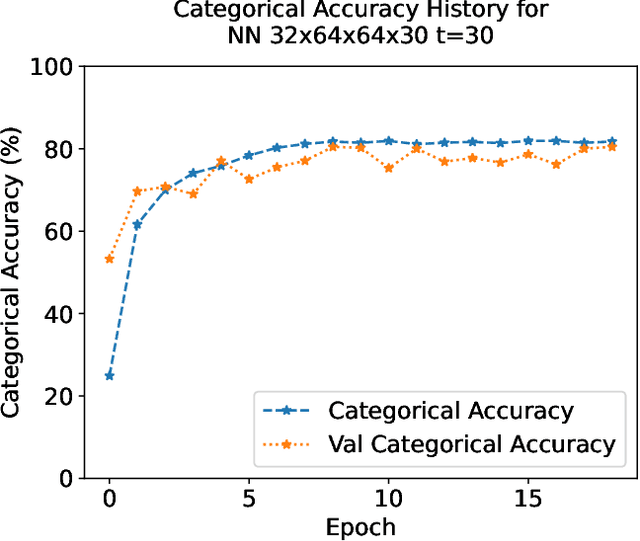

Consumer Internet of Things (IoT) devices are increasingly common in everyday homes, from smart speakers to security cameras. Along with their benefits come potential privacy and security threats. To limit these threats we must implement solutions to filter IoT traffic at the edge. To this end the identification of the IoT device is the first natural step. In this paper we demonstrate a novel method of rapid IoT device identification that uses neural networks trained on device DNS traffic that can be captured from a DNS server on the local network. The method identifies devices by fitting a model to the first seconds of DNS second-level-domain traffic following their first connection. Since security and privacy threat detection often operate at a device specific level, rapid identification allows these strategies to be implemented immediately. Through a total of 51,000 rigorous automated experiments, we classify 30 consumer IoT devices from 27 different manufacturers with 82% and 93% accuracy for product type and device manufacturers respectively.
Multimodal Federated Learning
Sep 10, 2021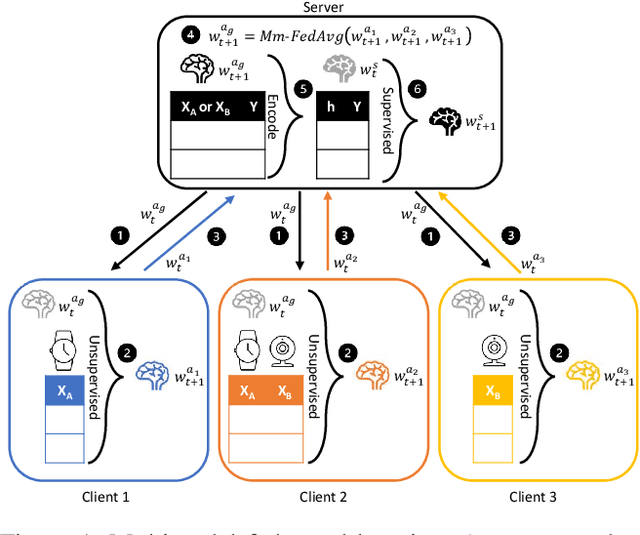
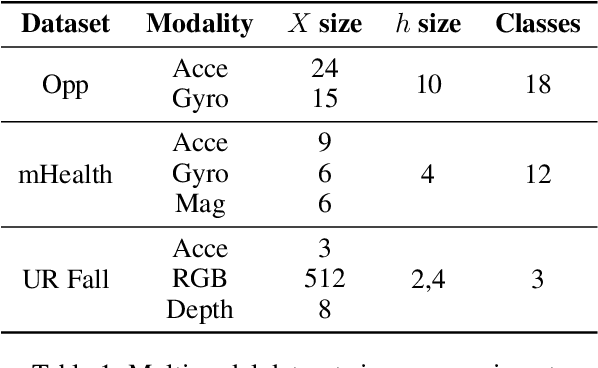
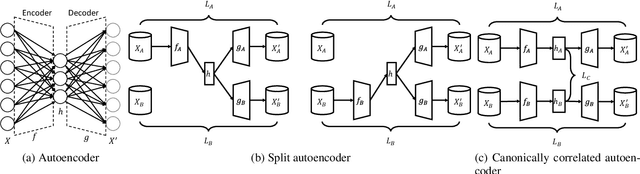
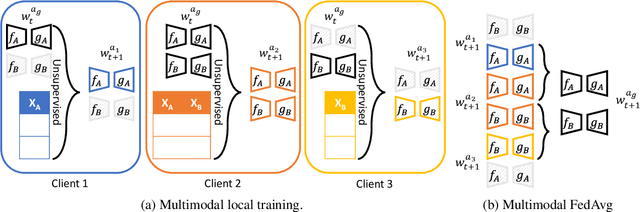
Federated learning is proposed as an alternative to centralized machine learning since its client-server structure provides better privacy protection and scalability in real-world applications. In many applications, such as smart homes with IoT devices, local data on clients are generated from different modalities such as sensory, visual, and audio data. Existing federated learning systems only work on local data from a single modality, which limits the scalability of the systems. In this paper, we propose a multimodal and semi-supervised federated learning framework that trains autoencoders to extract shared or correlated representations from different local data modalities on clients. In addition, we propose a multimodal FedAvg algorithm to aggregate local autoencoders trained on different data modalities. We use the learned global autoencoder for a downstream classification task with the help of auxiliary labelled data on the server. We empirically evaluate our framework on different modalities including sensory data, depth camera videos, and RGB camera videos. Our experimental results demonstrate that introducing data from multiple modalities into federated learning can improve its accuracy. In addition, we can use labelled data from only one modality for supervised learning on the server and apply the learned model to testing data from other modalities to achieve decent accuracy (e.g., approximately 70% as the best performance), especially when combining contributions from both unimodal clients and multimodal clients.
A Tandem Framework Balancing Privacy and Security for Voice User Interfaces
Jul 21, 2021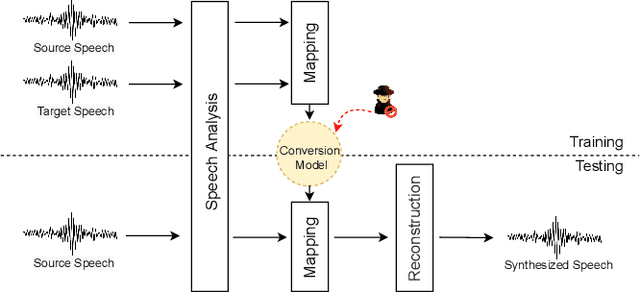

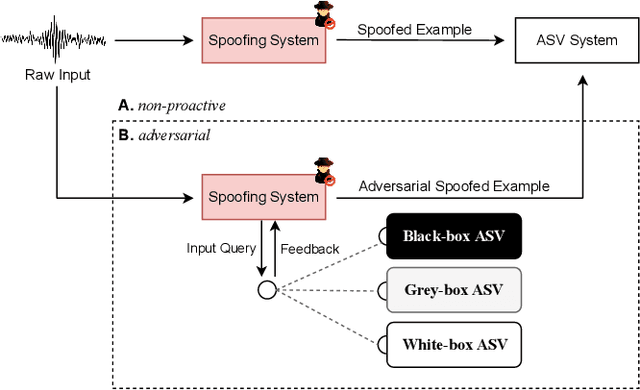
Speech synthesis, voice cloning, and voice conversion techniques present severe privacy and security threats to users of voice user interfaces (VUIs). These techniques transform one or more elements of a speech signal, e.g., identity and emotion, while preserving linguistic information. Adversaries may use advanced transformation tools to trigger a spoofing attack using fraudulent biometrics for a legitimate speaker. Conversely, such techniques have been used to generate privacy-transformed speech by suppressing personally identifiable attributes in the voice signals, achieving anonymization. Prior works have studied the security and privacy vectors in parallel, and thus it raises alarm that if a benign user can achieve privacy by a transformation, it also means that a malicious user can break security by bypassing the anti-spoofing mechanism. In this paper, we take a step towards balancing two seemingly conflicting requirements: security and privacy. It remains unclear what the vulnerabilities in one domain imply for the other, and what dynamic interactions exist between them. A better understanding of these aspects is crucial for assessing and mitigating vulnerabilities inherent with VUIs and building effective defenses. In this paper,(i) we investigate the applicability of the current voice anonymization methods by deploying a tandem framework that jointly combines anti-spoofing and authentication models, and evaluate the performance of these methods;(ii) examining analytical and empirical evidence, we reveal a duality between the two mechanisms as they offer different ways to achieve the same objective, and we show that leveraging one vector significantly amplifies the effectiveness of the other;(iii) we demonstrate that to effectively defend from potential attacks against VUIs, it is necessary to investigate the attacks from multiple complementary perspectives(security and privacy).
Revisiting IoT Device Identification
Jul 16, 2021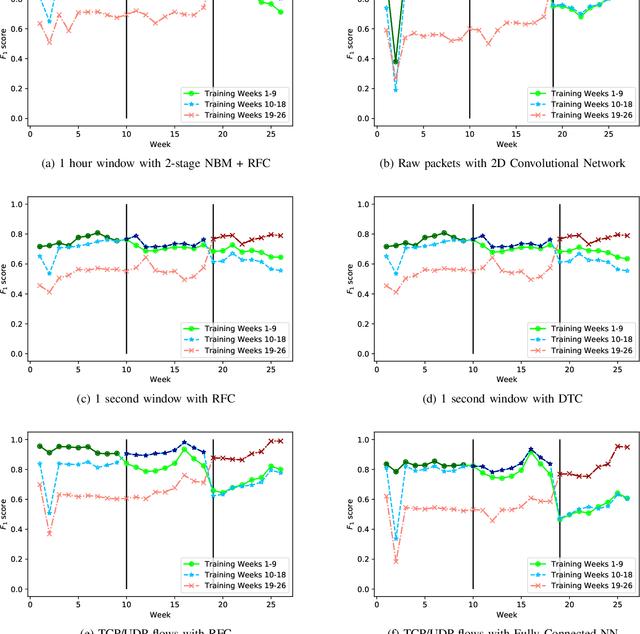
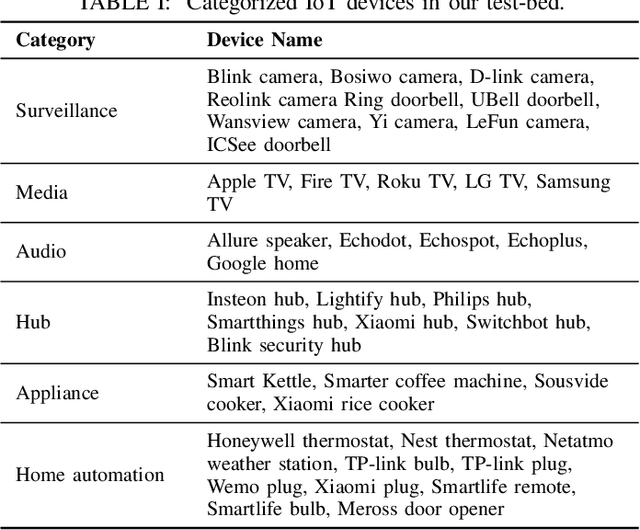

Internet-of-Things (IoT) devices are known to be the source of many security problems, and as such, they would greatly benefit from automated management. This requires robustly identifying devices so that appropriate network security policies can be applied. We address this challenge by exploring how to accurately identify IoT devices based on their network behavior, while leveraging approaches previously proposed by other researchers. We compare the accuracy of four different previously proposed machine learning models (tree-based and neural network-based) for identifying IoT devices. We use packet trace data collected over a period of six months from a large IoT test-bed. We show that, while all models achieve high accuracy when evaluated on the same dataset as they were trained on, their accuracy degrades over time, when evaluated on data collected outside the training set. We show that on average the models' accuracy degrades after a couple of weeks by up to 40 percentage points (on average between 12 and 21 percentage points). We argue that, in order to keep the models' accuracy at a high level, these need to be continuously updated.
Quantifying Information Leakage from Gradients
May 28, 2021
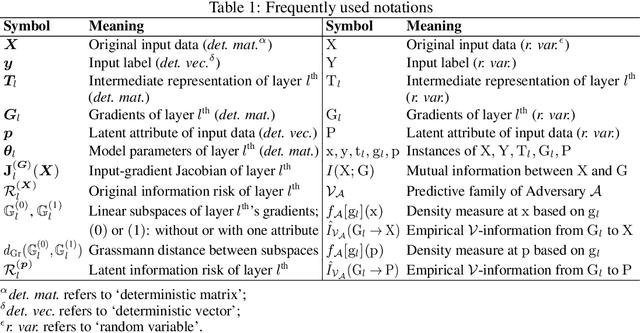
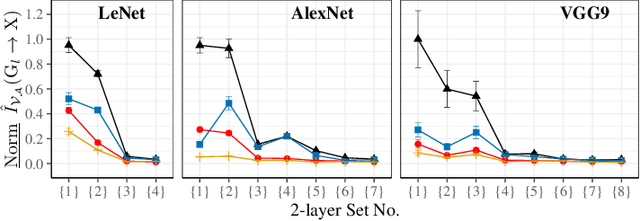

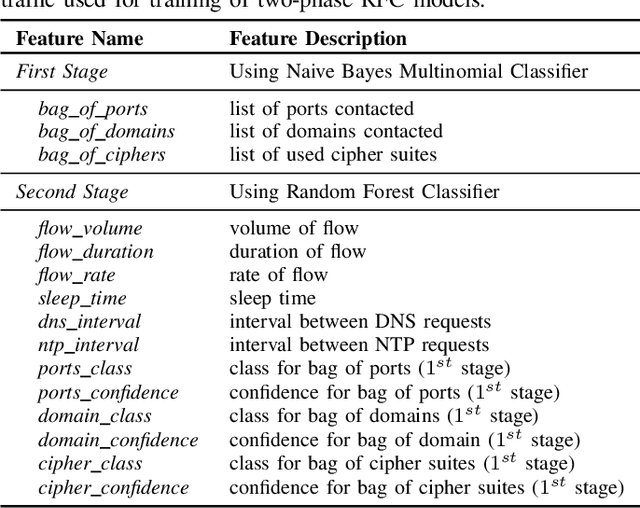
Sharing deep neural networks' gradients instead of training data could facilitate data privacy in collaborative learning. In practice however, gradients can disclose both private latent attributes and original data. Mathematical metrics are needed to quantify both original and latent information leakages from gradients computed over the training data. In this work, we first use an adaptation of the empirical $\mathcal{V}$-information to present an information-theoretic justification for the attack success rates in a layer-wise manner. We then move towards a deeper understanding of gradient leakages and propose more general and efficient metrics, using sensitivity and subspace distance to quantify the gradient changes w.r.t. original and latent information, respectively. Our empirical results, on six datasets and four models, reveal that gradients of the first layers contain the highest amount of original information, while the classifier/fully-connected layers placed after the feature extractor contain the highest latent information. Further, we show how training hyperparameters such as gradient aggregation can decrease information leakages. Our characterization provides a new understanding on gradient-based information leakages using the gradients' sensitivity w.r.t. changes in private information, and portends possible defenses such as layer-based protection or strong aggregation.