 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrationDep: Narratives on Social Media For Automatic Depression Detection
Jul 24, 2024



Social media posts provide valuable insight into the narrative of users and their intentions, including providing an opportunity to automatically model whether a social media user is depressed or not. The challenge lies in faithfully modelling user narratives from their online social media posts, which could potentially be useful in several different applications. We have developed a novel and effective model called \texttt{NarrationDep}, which focuses on detecting narratives associated with depression. By analyzing a user's tweets, \texttt{NarrationDep} accurately identifies crucial narratives. \texttt{NarrationDep} is a deep learning framework that jointly models individual user tweet representations and clusters of users' tweets. As a result, \texttt{NarrationDep} is characterized by a novel two-layer deep learning model: the first layer models using social media text posts, and the second layer learns semantic representations of tweets associated with a cluster. To faithfully model these cluster representations, the second layer incorporates a novel component that hierarchically learns from users' posts. The results demonstrate that our framework outperforms other comparative models including recently developed models on a variety of datasets.
IDoFew: Intermediate Training Using Dual-Clustering in Language Models for Few Labels Text Classification
Jan 08, 2024



Language models such as Bidirectional Encoder Representations from Transformers (BERT) have been very effective in various Natural Language Processing (NLP) and text mining tasks including text classification. However, some tasks still pose challenges for these models, including text classification with limited labels. This can result in a cold-start problem. Although some approaches have attempted to address this problem through single-stage clustering as an intermediate training step coupled with a pre-trained language model, which generates pseudo-labels to improve classification, these methods are often error-prone due to the limitations of the clustering algorithms. To overcome this, we have developed a novel two-stage intermediate clustering with subsequent fine-tuning that models the pseudo-labels reliably, resulting in reduced prediction errors. The key novelty in our model, IDoFew, is that the two-stage clustering coupled with two different clustering algorithms helps exploit the advantages of the complementary algorithms that reduce the errors in generating reliable pseudo-labels for fine-tuning. Our approach has shown significant improvements compared to strong comparative models.
DepressionNet: A Novel Summarization Boosted Deep Framework for Depression Detection on Social Media
May 23, 2021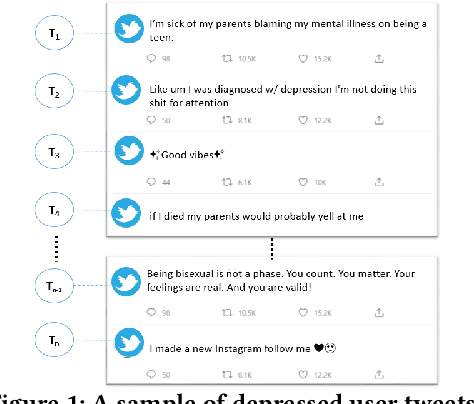

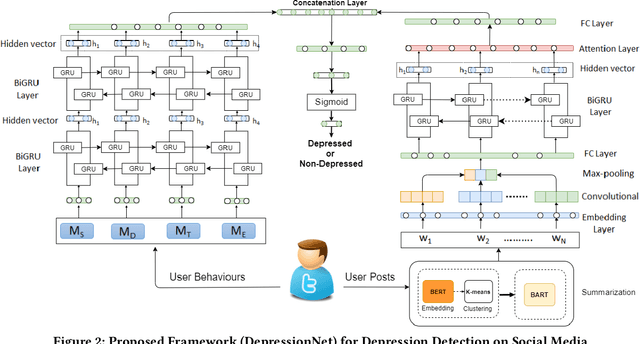

Twitter is currently a popular online social media platform which allows users to share their user-generated content. This publicly-generated user data is also crucial to healthcare technologies because the discovered patterns would hugely benefit them in several ways. One of the applications is in automatically discovering mental health problems, e.g., depression. Previous studies to automatically detect a depressed user on online social media have largely relied upon the user behaviour and their linguistic patterns including user's social interactions. The downside is that these models are trained on several irrelevant content which might not be crucial towards detecting a depressed user. Besides, these content have a negative impact on the overall efficiency and effectiveness of the model. To overcome the shortcomings in the existing automatic depression detection methods, we propose a novel computational framework for automatic depression detection that initially selects relevant content through a hybrid extractive and abstractive summarization strategy on the sequence of all user tweets leading to a more fine-grained and relevant content. The content then goes to our novel deep learning framework comprising of a unified learning machinery comprising of Convolutional Neural Network (CNN) coupled with attention-enhanced Gated Recurrent Units (GRU) models leading to better empirical performance than existing strong baselines.
Depression Detection with Multi-Modalities Using a Hybrid Deep Learning Model on Social Media
Jul 03, 2020
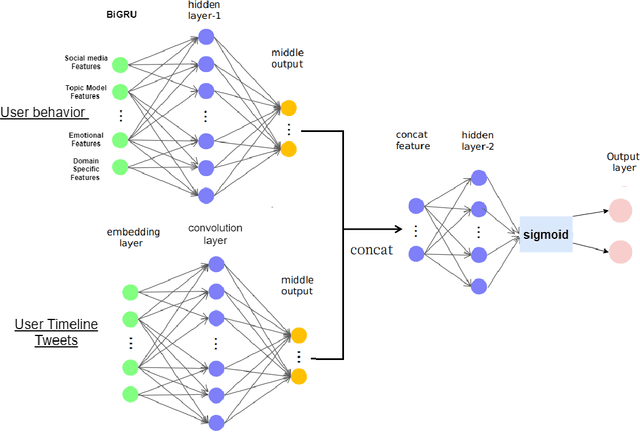
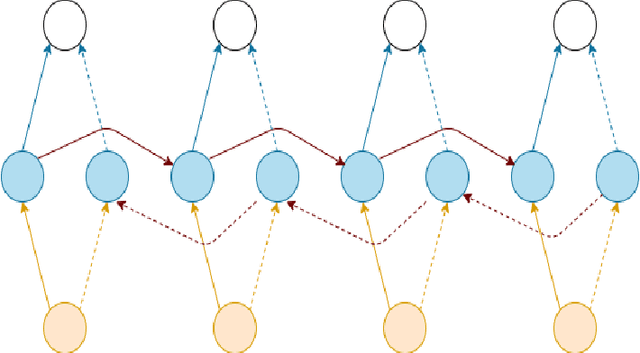

Social networks enable people to interact with one another by sharing information, sending messages, making friends, and having discussions, which generates massive amounts of data every day, popularly called as the user-generated content. This data is present in various forms such as images, text, videos, links, and others and reflects user behaviours including their mental states. It is challenging yet promising to automatically detect mental health problems from such data which is short, sparse and sometimes poorly phrased. However, there are efforts to automatically learn patterns using computational models on such user-generated content. While many previous works have largely studied the problem on a small-scale by assuming uni-modality of data which may not give us faithful results, we propose a novel scalable hybrid model that combines Bidirectional Gated Recurrent Units (BiGRUs) and Convolutional Neural Networks to detect depressed users on social media such as Twitter-based on multi-modal features. Specifically, we encode words in user posts using pre-trained word embeddings and BiGRUs to capture latent behavioural patterns, long-term dependencies, and correlation across the modalities, including semantic sequence features from the user timelines (posts). The CNN model then helps learn useful features. Our experiments show that our model outperforms several popular and strong baseline methods, demonstrating the effectiveness of combining deep learning with multi-modal features. We also show that our model helps improve predictive performance when detecting depression in users who are posting messages publicly on social media.