 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlick: Few Labels Text Classification using K-Aware Intermediate Learning in Multi-Task Low-Resource Languages
Jun 12, 2025Training deep learning networks with minimal supervision has gained significant research attention due to its potential to reduce reliance on extensive labelled data. While self-training methods have proven effective in semi-supervised learning, they remain vulnerable to errors from noisy pseudo labels. Moreover, most recent approaches to the few-label classification problem are either designed for resource-rich languages such as English or involve complex cascading models that are prone to overfitting. To address the persistent challenge of few-label text classification in truly low-resource linguistic contexts, where existing methods often struggle with noisy pseudo-labels and domain adaptation, we propose Flick. Unlike prior methods that rely on generic multi-cluster pseudo-labelling or complex cascading architectures, Flick leverages the fundamental insight that distilling high-confidence pseudo-labels from a broader set of initial clusters can dramatically improve pseudo-label quality, particularly for linguistically diverse, low-resource settings. Flick introduces a novel pseudo-label refinement component, a departure from traditional pseudo-labelling strategies by identifying and leveraging top-performing pseudo-label clusters. This component specifically learns to distil highly reliable pseudo-labels from an initial broad set by focusing on single-cluster cohesion and leveraging an adaptive top-k selection mechanism. This targeted refinement process is crucial for mitigating the propagation of errors inherent in low-resource data, allowing for robust fine-tuning of pre-trained language models with only a handful of true labels. We demonstrate Flick's efficacy across 14 diverse datasets, encompassing challenging low-resource languages such as Arabic, Urdu, and Setswana, alongside English, showcasing its superior performance and adaptability.
IDoFew: Intermediate Training Using Dual-Clustering in Language Models for Few Labels Text Classification
Jan 08, 2024



Language models such as Bidirectional Encoder Representations from Transformers (BERT) have been very effective in various Natural Language Processing (NLP) and text mining tasks including text classification. However, some tasks still pose challenges for these models, including text classification with limited labels. This can result in a cold-start problem. Although some approaches have attempted to address this problem through single-stage clustering as an intermediate training step coupled with a pre-trained language model, which generates pseudo-labels to improve classification, these methods are often error-prone due to the limitations of the clustering algorithms. To overcome this, we have developed a novel two-stage intermediate clustering with subsequent fine-tuning that models the pseudo-labels reliably, resulting in reduced prediction errors. The key novelty in our model, IDoFew, is that the two-stage clustering coupled with two different clustering algorithms helps exploit the advantages of the complementary algorithms that reduce the errors in generating reliable pseudo-labels for fine-tuning. Our approach has shown significant improvements compared to strong comparative models.
Weather impact on daily cases of COVID-19 in Saudi Arabia using machine learning
May 07, 2021
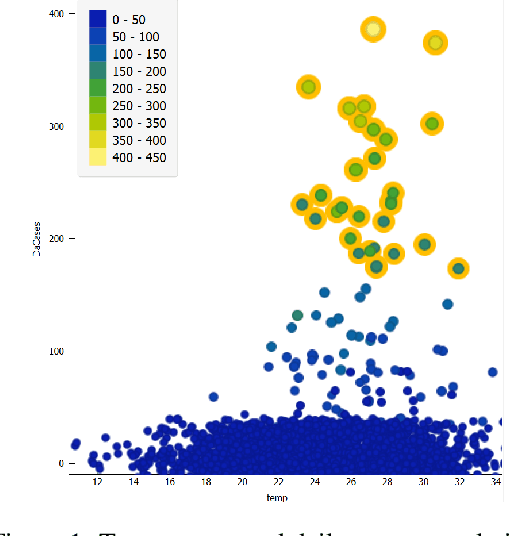
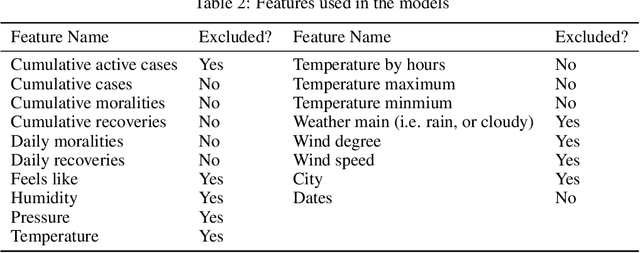
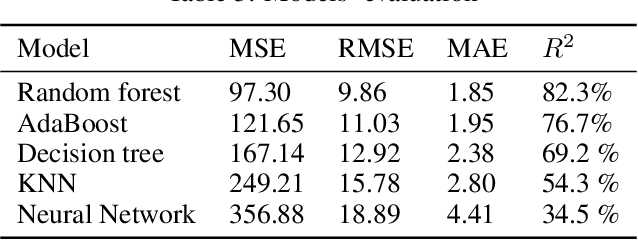
COVID-19 was announced by the World Health Organisation (WHO) as a global pandemic. The severity of the disease spread is determined by various factors such as the countries' health care capacity and the enforced lockdown. However, it is not clear if a country's climate acts as a contributing factor towards the number of infected cases. This paper aims to examine the relationship between COVID-19 and the weather of 89 cities in Saudi Arabia using machine learning techniques. We compiled and preprocessed data using the official daily report of the Ministry of Health of Saudi Arabia for COVID-19 cases and obtained historical weather data aligned with the reported case daily reports. We preprocessed and prepared the data to be used in models' training and evaluation. Our results show that temperature and wind have the strongest association with the spread of the pandemic. Our main contribution is data collection, preprocessing, and prediction of daily cases. For all tested models, we used cross-validation of K-fold of K=5. Our best model is the random forest that has a Mean Square Error(MSE), Root Mean Square (RMSE), Mean Absolute Error (MAE), and R{2} of 97.30, 9.86, 1.85, and 82.3\%, respectively.