 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free RL Agents Demonstrate System 1-Like Intentionality
Jan 30, 2025This paper argues that model-free reinforcement learning (RL) agents, while lacking explicit planning mechanisms, exhibit behaviours that can be analogised to System 1 ("thinking fast") processes in human cognition. Unlike model-based RL agents, which operate akin to System 2 ("thinking slow") reasoning by leveraging internal representations for planning, model-free agents react to environmental stimuli without anticipatory modelling. We propose a novel framework linking the dichotomy of System 1 and System 2 to the distinction between model-free and model-based RL. This framing challenges the prevailing assumption that intentionality and purposeful behaviour require planning, suggesting instead that intentionality can manifest in the structured, reactive behaviours of model-free agents. By drawing on interdisciplinary insights from cognitive psychology, legal theory, and experimental jurisprudence, we explore the implications of this perspective for attributing responsibility and ensuring AI safety. These insights advocate for a broader, contextually informed interpretation of intentionality in RL systems, with implications for their ethical deployment and regulation.
Beyond Preferences in AI Alignment
Aug 30, 2024



The dominant practice of AI alignment assumes (1) that preferences are an adequate representation of human values, (2) that human rationality can be understood in terms of maximizing the satisfaction of preferences, and (3) that AI systems should be aligned with the preferences of one or more humans to ensure that they behave safely and in accordance with our values. Whether implicitly followed or explicitly endorsed, these commitments constitute what we term a preferentist approach to AI alignment. In this paper, we characterize and challenge the preferentist approach, describing conceptual and technical alternatives that are ripe for further research. We first survey the limits of rational choice theory as a descriptive model, explaining how preferences fail to capture the thick semantic content of human values, and how utility representations neglect the possible incommensurability of those values. We then critique the normativity of expected utility theory (EUT) for humans and AI, drawing upon arguments showing how rational agents need not comply with EUT, while highlighting how EUT is silent on which preferences are normatively acceptable. Finally, we argue that these limitations motivate a reframing of the targets of AI alignment: Instead of alignment with the preferences of a human user, developer, or humanity-writ-large, AI systems should be aligned with normative standards appropriate to their social roles, such as the role of a general-purpose assistant. Furthermore, these standards should be negotiated and agreed upon by all relevant stakeholders. On this alternative conception of alignment, a multiplicity of AI systems will be able to serve diverse ends, aligned with normative standards that promote mutual benefit and limit harm despite our plural and divergent values.
Concept Extrapolation: A Conceptual Primer
Jun 19, 2023This article is a primer on concept extrapolation - the ability to take a concept, a feature, or a goal that is defined in one context and extrapolate it safely to a more general context. Concept extrapolation aims to solve model splintering - a ubiquitous occurrence wherein the features or concepts shift as the world changes over time. Through discussing value splintering and value extrapolation the article argues that concept extrapolation is necessary for Artificial Intelligence alignment.
Solutions to preference manipulation in recommender systems require knowledge of meta-preferences
Sep 14, 2022
Iterative machine learning algorithms used to power recommender systems often change people's preferences by trying to learn them. Further a recommender can better predict what a user will do by making its users more predictable. Some preference changes on the part of the user are self-induced and desired whether the recommender caused them or not. This paper proposes that solutions to preference manipulation in recommender systems must take into account certain meta-preferences (preferences over another preference) in order to respect the autonomy of the user and not be manipulative.
Preference Change in Persuasive Robotics
Jun 21, 2022Human-robot interaction exerts influence towards the human, which often changes behavior. This article explores an externality of this changed behavior - preference change. It expands on previous work on preference change in AI systems. Specifically, this article will explore how a robot's adaptive behavior, personalized to the user, can exert influence through social interactions, that in turn change a user's preference. It argues that the risk of this is high given a robot's unique ability to influence behavior compared to other pervasive technologies. Persuasive Robotics thus runs the risk of being manipulative.
Recognising the importance of preference change: A call for a coordinated multidisciplinary research effort in the age of AI
Mar 30, 2022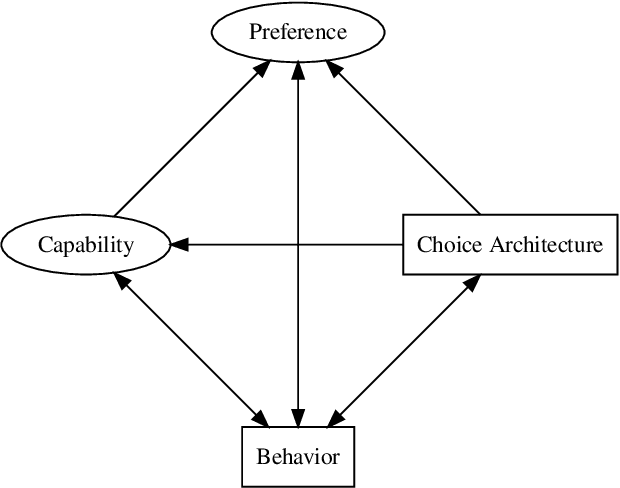
As artificial intelligence becomes more powerful and a ubiquitous presence in daily life, it is imperative to understand and manage the impact of AI systems on our lives and decisions. Modern ML systems often change user behavior (e.g. personalized recommender systems learn user preferences to deliver recommendations that change online behavior). An externality of behavior change is preference change. This article argues for the establishment of a multidisciplinary endeavor focused on understanding how AI systems change preference: Preference Science. We operationalize preference to incorporate concepts from various disciplines, outlining the importance of meta-preferences and preference-change preferences, and proposing a preliminary framework for how preferences change. We draw a distinction between preference change, permissible preference change, and outright preference manipulation. A diversity of disciplines contribute unique insights to this framework.
* Accepted at the AAAI-22 Workshop on AI For Behavior Change held at the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22), 7 pages, 1 figure
Definitions of intent suitable for algorithms
Jun 08, 2021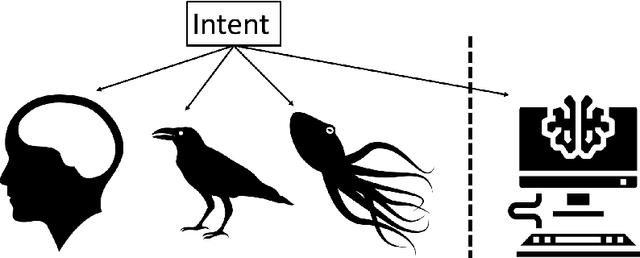
Intent modifies an actor's culpability of many types wrongdoing. Autonomous Algorithmic Agents have the capability of causing harm, and whilst their current lack of legal personhood precludes them from committing crimes, it is useful for a number of parties to understand under what type of intentional mode an algorithm might transgress. From the perspective of the creator or owner they would like ensure that their algorithms never intend to cause harm by doing things that would otherwise be labelled criminal if committed by a legal person. Prosecutors might have an interest in understanding whether the actions of an algorithm were internally intended according to a transparent definition of the concept. The presence or absence of intention in the algorithmic agent might inform the court as to the complicity of its owner. This article introduces definitions for direct, oblique (or indirect) and ulterior intent which can be used to test for intent in an algorithmic actor.
Extending counterfactual accounts of intent to include oblique intent
Jun 07, 2021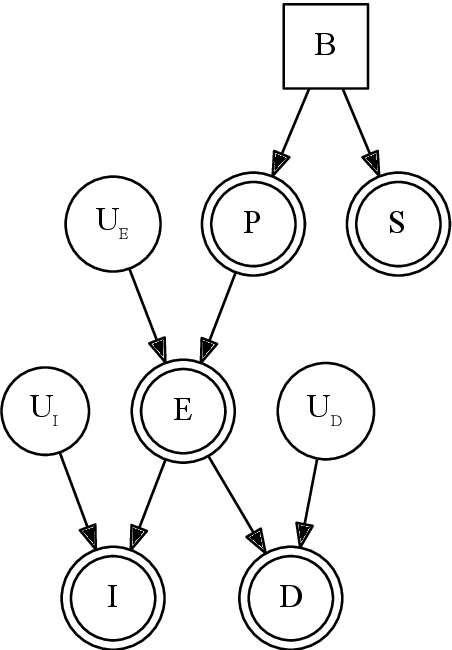
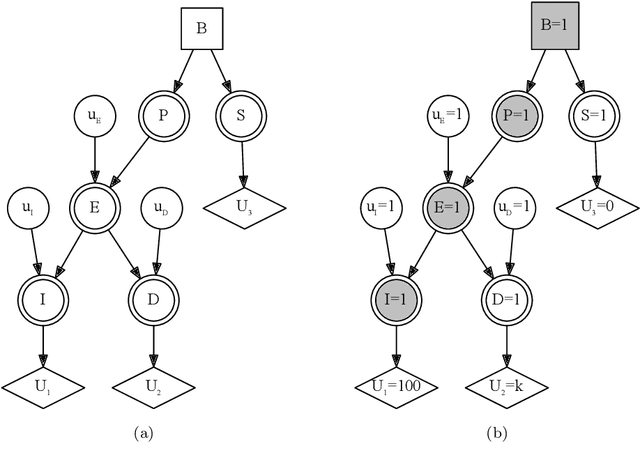
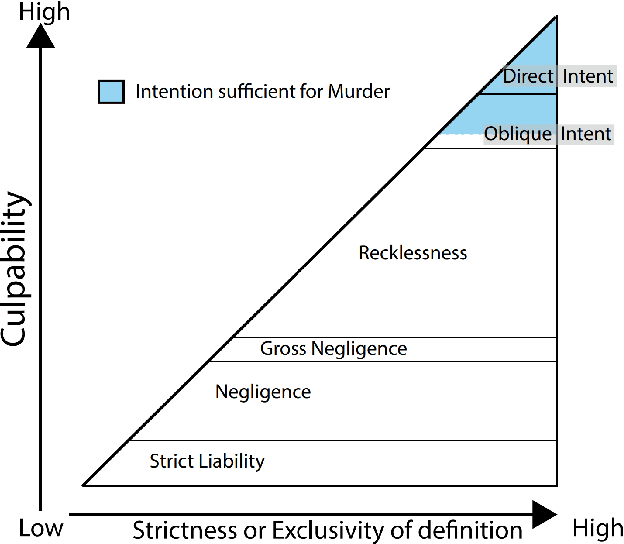
One approach to defining Intention is to use the counterfactual tools developed to define Causality. Direct Intention is considered the highest level of intent in the common law, and is a sufficient component for the most serious crimes to be committed. Loosely defined it is the commission of actions to bring about a desired or targeted outcome. Direct Intention is not always necessary for the most serious category of crimes because society has also found it necessary to develop a theory of intention around side-effects, known as oblique intent or indirect intent. This is to prevent moral harms from going unpunished which were not the aim of the actor, but were natural consequences nevertheless. This paper uses a canonical example of a plane owner, planting a bomb on their own plane in order to collect insurance, to illustrate how two accounts of counterfactual intent do not conclude that murder of the plane's passengers and crew were directly intended. We extend both frameworks to include a definition of oblique intent developed in Ashton (2021)
Causal Campbell-Goodhart's law and Reinforcement Learning
Nov 02, 2020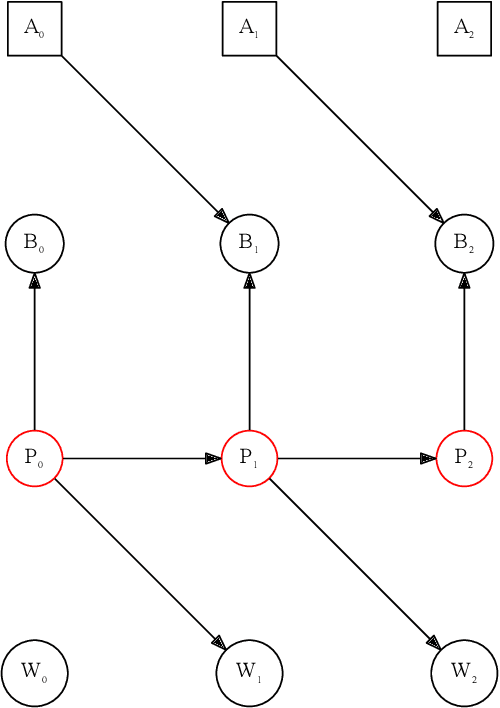


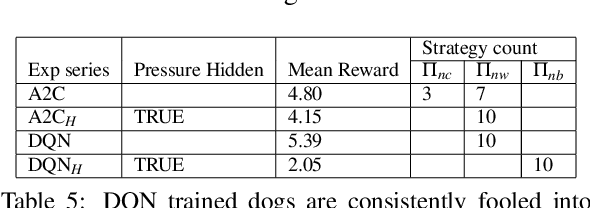
Campbell-Goodhart's law relates to the causal inference error whereby decision-making agents aim to influence variables which are correlated to their goal objective but do not reliably cause it. This is a well known error in Economics and Political Science but not widely labelled in Artificial Intelligence research. Through a simple example, we show how off-the-shelf deep Reinforcement Learning (RL) algorithms are not necessarily immune to this cognitive error. The off-policy learning method is tricked, whilst the on-policy method is not. The practical implication is that naive application of RL to complex real life problems can result in the same types of policy errors that humans make. Great care should be taken around understanding the causal model that underpins a solution derived from Reinforcement Learning.