 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Network Approximation: Achieving Arbitrary Accuracy with Fixed Number of Neurons
Jul 07, 2021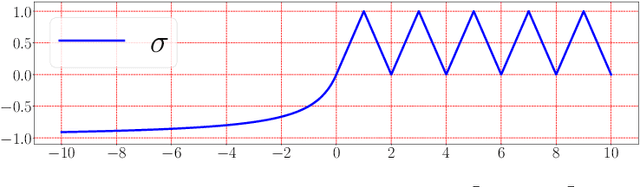
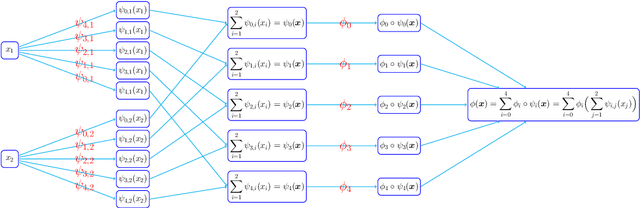
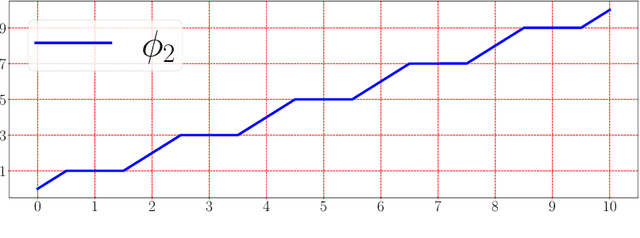
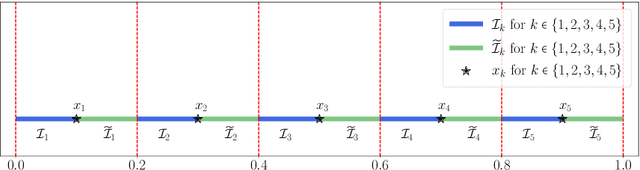
This paper develops simple feed-forward neural networks that achieve the universal approximation property for all continuous functions with a fixed finite number of neurons. These neural networks are simple because they are designed with a simple and computable continuous activation function $\sigma$ leveraging a triangular-wave function and a softsign function. We prove that $\sigma$-activated networks with width $36d(2d+1)$ and depth $11$ can approximate any continuous function on a $d$-dimensioanl hypercube within an arbitrarily small error. Hence, for supervised learning and its related regression problems, the hypothesis space generated by these networks with a size not smaller than $36d(2d+1)\times 11$ is dense in the space of continuous functions. Furthermore, classification functions arising from image and signal classification are in the hypothesis space generated by $\sigma$-activated networks with width $36d(2d+1)$ and depth $12$, when there exist pairwise disjoint closed bounded subsets of $\mathbb{R}^d$ such that the samples of the same class are located in the same subset.
Solving PDEs on Unknown Manifolds with Machine Learning
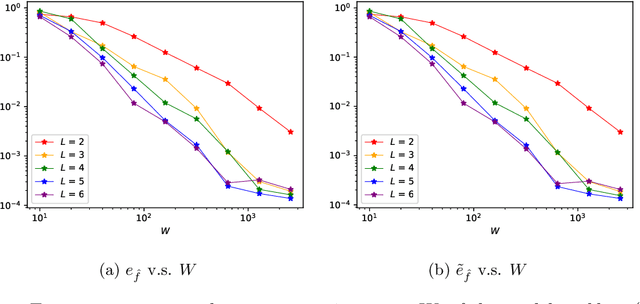
Jun 12, 2021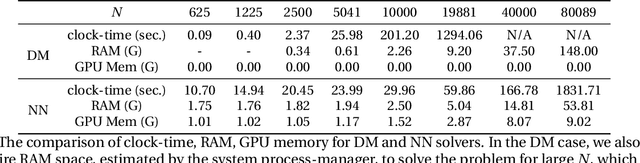
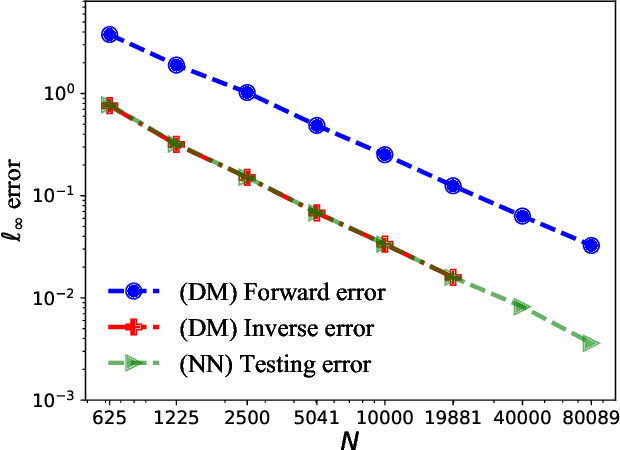

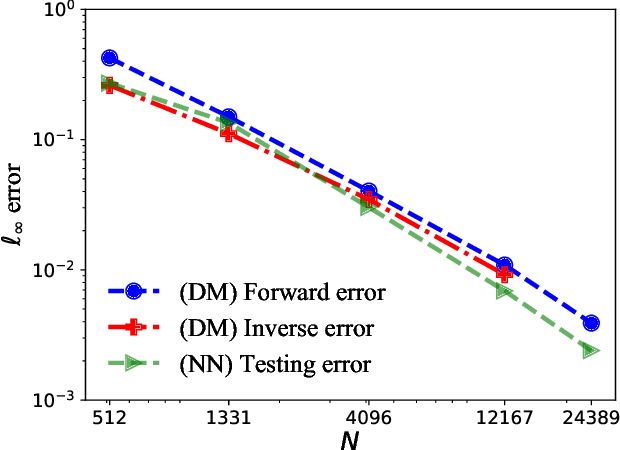
This paper proposes a mesh-free computational framework and machine learning theory for solving elliptic PDEs on unknown manifolds, identified with point clouds, based on diffusion maps (DM) and deep learning. The PDE solver is formulated as a supervised learning task to solve a least-squares regression problem that imposes an algebraic equation approximating a PDE (and boundary conditions if applicable). This algebraic equation involves a graph-Laplacian type matrix obtained via DM asymptotic expansion, which is a consistent estimator of second-order elliptic differential operators. The resulting numerical method is to solve a highly non-convex empirical risk minimization problem subjected to a solution from a hypothesis space of neural-network type functions. In a well-posed elliptic PDE setting, when the hypothesis space consists of feedforward neural networks with either infinite width or depth, we show that the global minimizer of the empirical loss function is a consistent solution in the limit of large training data. When the hypothesis space is a two-layer neural network, we show that for a sufficiently large width, the gradient descent method can identify a global minimizer of the empirical loss function. Supporting numerical examples demonstrate the convergence of the solutions and the effectiveness of the proposed solver in avoiding numerical issues that hampers the traditional approach when a large data set becomes available, e.g., large matrix inversion.
The Discovery of Dynamics via Linear Multistep Methods and Deep Learning: Error Estimation
Mar 21, 2021
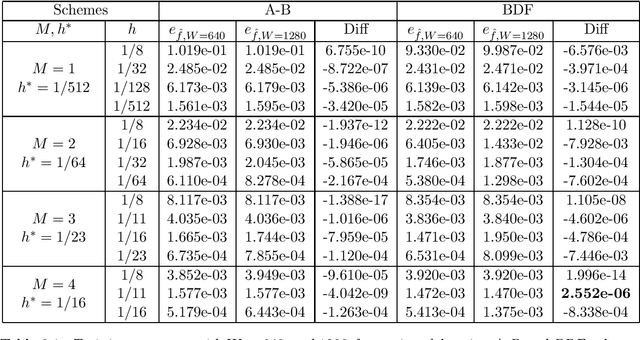
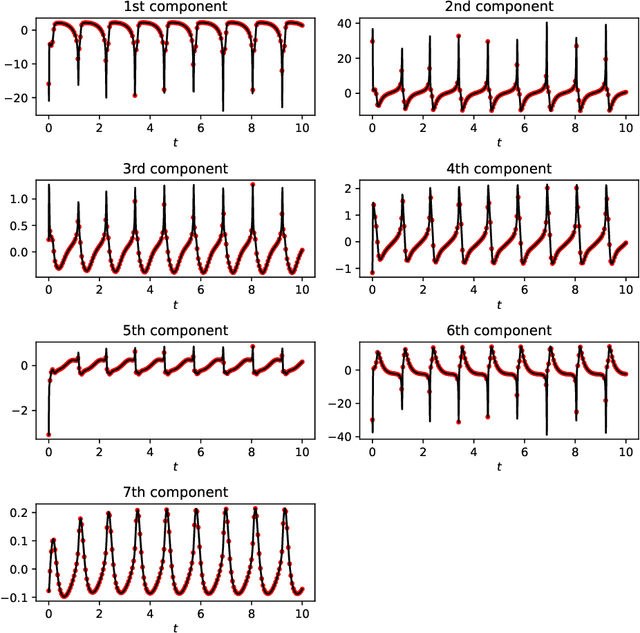
Identifying hidden dynamics from observed data is a significant and challenging task in a wide range of applications. Recently, the combination of linear multistep methods (LMMs) and deep learning has been successfully employed to discover dynamics, whereas a complete convergence analysis of this approach is still under development. In this work, we consider the deep network-based LMMs for the discovery of dynamics. We put forward error estimates for these methods using the approximation property of deep networks. It indicates, for certain families of LMMs, that the $\ell^2$ grid error is bounded by the sum of $O(h^p)$ and the network approximation error, where $h$ is the time step size and $p$ is the local truncation error order. Numerical results of several physically relevant examples are provided to demonstrate our theory.
Optimal Approximation Rate of ReLU Networks in terms of Width and Depth
Feb 28, 2021
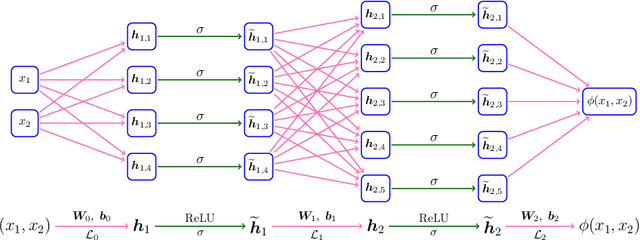
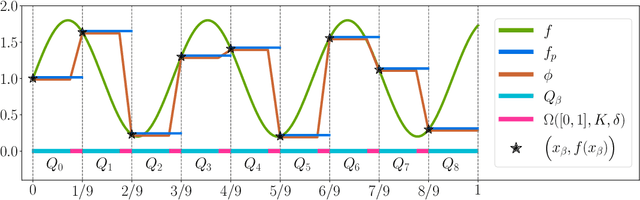
This paper concentrates on the approximation power of deep feed-forward neural networks in terms of width and depth. It is proved by construction that ReLU networks with width $\mathcal{O}\big(\max\{d\lfloor N^{1/d}\rfloor,\, N+2\}\big)$ and depth $\mathcal{O}(L)$ can approximate a H\"older continuous function on $[0,1]^d$ with an approximation rate $\mathcal{O}\big(\lambda\sqrt{d} (N^2L^2\ln N)^{-\alpha/d}\big)$, where $\alpha\in (0,1]$ and $\lambda>0$ are H\"older order and constant, respectively. Such a rate is optimal up to a constant in terms of width and depth separately, while existing results are only nearly optimal without the logarithmic factor in the approximation rate. More generally, for an arbitrary continuous function $f$ on $[0,1]^d$, the approximation rate becomes $\mathcal{O}\big(\,\sqrt{d}\,\omega_f\big( (N^2L^2\ln N)^{-1/d}\big)\,\big)$, where $\omega_f(\cdot)$ is the modulus of continuity. We also extend our analysis to any continuous function $f$ on a bounded set. Particularly, if ReLU networks with depth $31$ and width $\mathcal{O}(N)$ are used to approximate one-dimensional Lipschitz continuous functions on $[0,1]$ with a Lipschitz constant $\lambda>0$, the approximation rate in terms of the total number of parameters, $W=\mathcal{O}(N^2)$, becomes $\mathcal{O}(\tfrac{\lambda}{W\ln W})$, which has not been discovered in the literature for fixed-depth ReLU networks.
Friedrichs Learning: Weak Solutions of Partial Differential Equations via Deep Learning
Jan 14, 2021
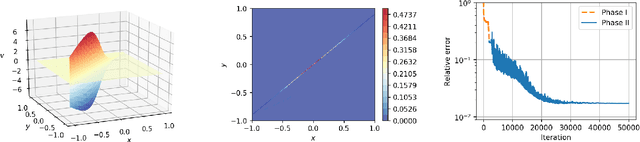

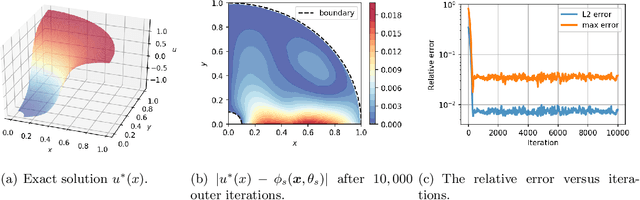
This paper proposes Friedrichs learning as a novel deep learning methodology that can learn the weak solutions of PDEs via a minmax formulation, which transforms the PDE problem into a minimax optimization problem to identify weak solutions. The name "Friedrichs learning" is for highlighting the close relationship between our learning strategy and Friedrichs theory on symmetric systems of PDEs. The weak solution and the test function in the weak formulation are parameterized as deep neural networks in a mesh-free manner, which are alternately updated to approach the optimal solution networks approximating the weak solution and the optimal test function, respectively. Extensive numerical results indicate that our mesh-free method can provide reasonably good solutions to a wide range of PDEs defined on regular and irregular domains in various dimensions, where classical numerical methods such as finite difference methods and finite element methods may be tedious or difficult to be applied.
Reproducing Activation Function for Deep Learning
Jan 13, 2021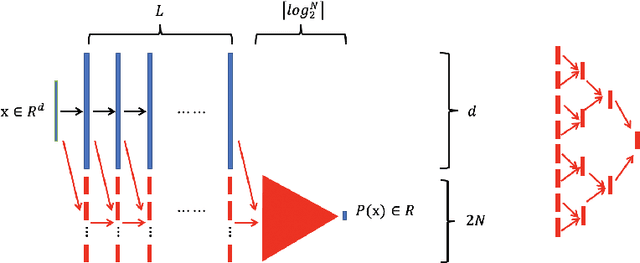
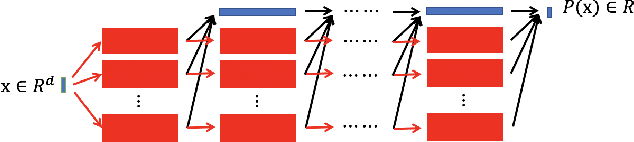

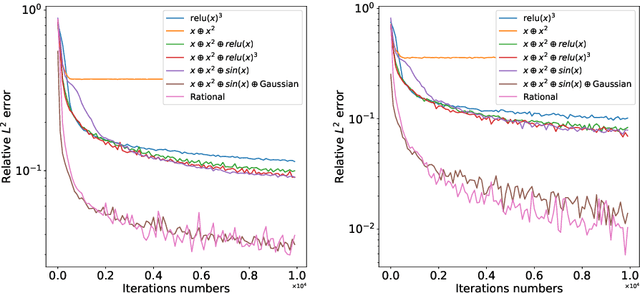
In this paper, we propose the reproducing activation function to improve deep learning accuracy for various applications ranging from computer vision problems to scientific computing problems. The idea of reproducing activation functions is to employ several basic functions and their learnable linear combination to construct neuron-wise data-driven activation functions for each neuron. Armed with such activation functions, deep neural networks can reproduce traditional approximation tools and, therefore, approximate target functions with a smaller number of parameters than traditional neural networks. In terms of training dynamics of deep learning, reproducing activation functions can generate neural tangent kernels with a better condition number than traditional activation functions lessening the spectral bias of deep learning. As demonstrated by extensive numerical tests, the proposed activation function can facilitate the convergence of deep learning optimization for a solution with higher accuracy than existing deep learning solvers for audio/image/video reconstruction, PDEs, and eigenvalue problems.
Efficient Attention Network: Accelerate Attention by Searching Where to Plug
Nov 28, 2020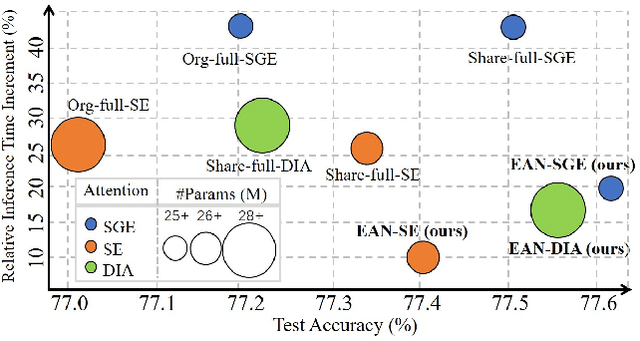
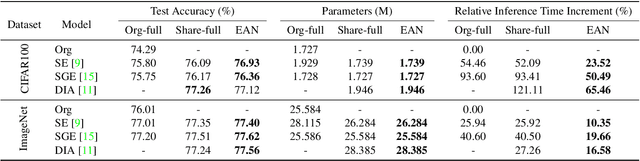
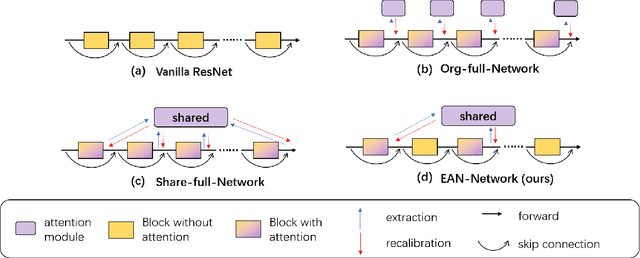
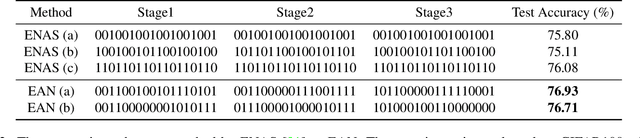
Recently, many plug-and-play self-attention modules are proposed to enhance the model generalization by exploiting the internal information of deep convolutional neural networks (CNNs). Previous works lay an emphasis on the design of attention module for specific functionality, e.g., light-weighted or task-oriented attention. However, they ignore the importance of where to plug in the attention module since they connect the modules individually with each block of the entire CNN backbone for granted, leading to incremental computational cost and number of parameters with the growth of network depth. Thus, we propose a framework called Efficient Attention Network (EAN) to improve the efficiency for the existing attention modules. In EAN, we leverage the sharing mechanism (Huang et al. 2020) to share the attention module within the backbone and search where to connect the shared attention module via reinforcement learning. Finally, we obtain the attention network with sparse connections between the backbone and modules, while (1) maintaining accuracy (2) reducing extra parameter increment and (3) accelerating inference. Extensive experiments on widely-used benchmarks and popular attention networks show the effectiveness of EAN. Furthermore, we empirically illustrate that our EAN has the capacity of transferring to other tasks and capturing the informative features. The code is available at https://github.com/gbup-group/EAN-efficient-attention-network
Neural Network Approximation: Three Hidden Layers Are Enough
Oct 25, 2020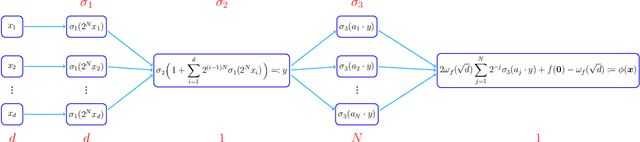

A three-hidden-layer neural network with super approximation power is introduced. This network is built with the Floor function ($\lfloor x\rfloor$), the exponential function ($2^x$), the step function ($\one_{x\geq 0}$), or their compositions as activation functions in each neuron and hence we call such networks as Floor-Exponential-Step (FLES) networks. For any width hyper-parameter $N\in\mathbb{N}^+$, it is shown that FLES networks with a width $\max\{d,\, N\}$ and three hidden layers can uniformly approximate a H{\"o}lder function $f$ on $[0,1]^d$ with an exponential approximation rate $3\lambda d^{\alpha/2}2^{-\alpha N}$, where $\alpha \in(0,1]$ and $\lambda$ are the H{\"o}lder order and constant, respectively. More generally for an arbitrary continuous function $f$ on $[0,1]^d$ with a modulus of continuity $\omega_f(\cdot)$, the constructive approximation rate is $\omega_f(\sqrt{d}\,2^{-N})+2\omega_f(\sqrt{d}){2^{-N}}$. As a consequence, this new {class of networks} overcomes the curse of dimensionality in approximation power when the variation of $\omega_f(r)$ as $r\rightarrow 0$ is moderate (e.g., $\omega_f(r){\lesssim} r^\alpha$ for H{\"o}lder continuous functions), since the major term to be concerned in our approximation rate is essentially $\sqrt{d}$ times a function of $N$ independent of $d$ within the modulus of continuity.
Two-Layer Neural Networks for Partial Differential Equations: Optimization and Generalization Theory
Jun 28, 2020Deep learning has significantly revolutionized the design of numerical algorithms for solving high-dimensional partial differential equations (PDEs). Yet the empirical successes of such approaches remains mysterious in theory. In deep learning-based PDE solvers, solving the original PDE is formulated into an expectation minimization problem with a PDE solution space discretized via deep neural networks. A global minimizer corresponds to a deep neural network that solves the given PDE. Typically, gradient descent-based methods are applied to minimize the expectation. This paper shows that gradient descent can identify a global minimizer of the optimization problem with a well-controlled generalization error in the case of two-layer neural networks in the over-parameterization regime (i.e., the network width is sufficiently large). The generalization error of the gradient descent solution does not suffer from the curse of dimensonality if the solution is in a Barron-type space. The theories developed here could form a theoretical foundation of deep learning-based PDE solvers.
Deep Network Approximation with Discrepancy Being Reciprocal of Width to Power of Depth
Jun 22, 2020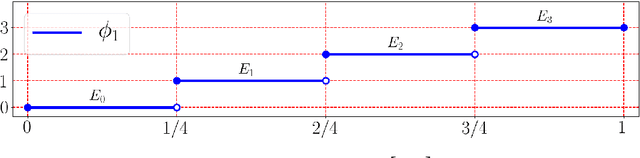
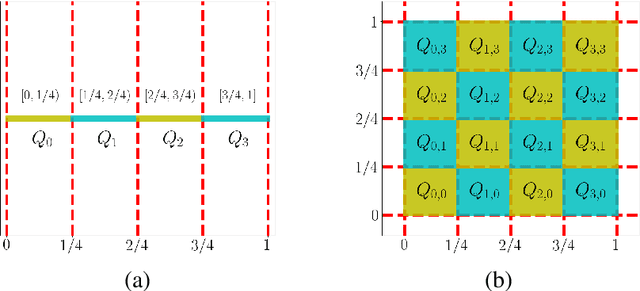
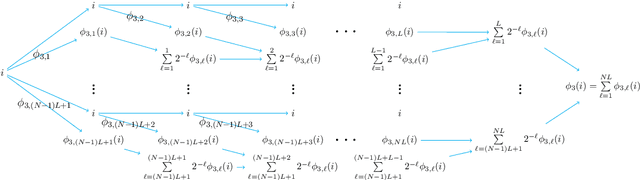
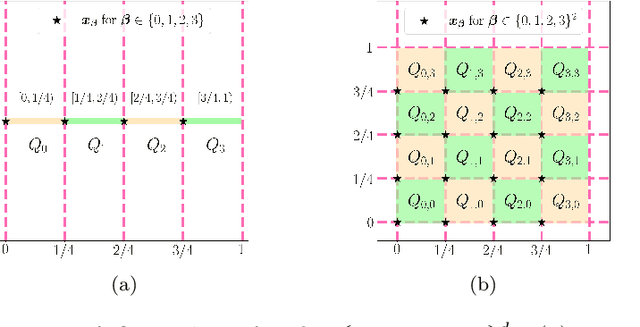
A new network with super approximation power is introduced. This network is built with Floor ($\lfloor x\rfloor$) and ReLU ($\max\{0,x\}$) activation functions and hence we call such networks as Floor-ReLU networks. It is shown by construction that Floor-ReLU networks with width $\max\{d,\, 5N+13\}$ and depth $64dL+3$ can pointwise approximate a Lipschitz continuous function $f$ on $[0,1]^d$ with an exponential approximation rate $3\mu\sqrt{d}\,N^{-\sqrt{L}}$, where $\mu$ is the Lipschitz constant of $f$. More generally for an arbitrary continuous function $f$ on $[0,1]^d$ with a modulus of continuity $\omega_f(\cdot)$, the constructive approximation rate is $\omega_f(\sqrt{d}\,N^{-\sqrt{L}})+2\omega_f(\sqrt{d}){N^{-\sqrt{L}}}$. As a consequence, this new network overcomes the curse of dimensionality in approximation power since this approximation order is essentially $\sqrt{d}$ times a function of $N$ and $L$ independent of $d$.