 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIM-GIV: an effective integrity monitoring scheme for tightly-coupled GNSS/INS/Vision integration based on factor graph optimization
Oct 30, 2024Global Navigation Satellite System/Inertial Navigation System (GNSS/INS)/Vision integration based on factor graph optimization (FGO) has recently attracted extensive attention in navigation and robotics community. Integrity monitoring (IM) capability is required when FGO-based integrated navigation system is used for safety-critical applications. However, traditional researches on IM of integrated navigation system are mostly based on Kalman filter. It is urgent to develop effective IM scheme for FGO-based GNSS/INS/Vision integration. In this contribution, the position error bounding formula to ensure the integrity of the GNSS/INS/Vision integration based on FGO is designed and validated for the first time. It can be calculated by the linearized equations from the residuals of GNSS pseudo-range, IMU pre-integration and visual measurements. The specific position error bounding is given in the case of GNSS, INS and visual measurement faults. Field experiments were conducted to evaluate and validate the performance of the proposed position error bounding. Experimental results demonstrate that the proposed position error bounding for the GNSS/INS/Vision integration based on FGO can correctly fit the position error against different fault modes, and the availability of integrity in six fault modes is 100% after correct and timely fault exclusion.
Large Language Model for Causal Decision Making
Dec 29, 2023



Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to inference based on user-specified structured data and knowledge in corpus-rare concepts like causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. With three case studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers. Numerical studies also reveal that it has a remarkable ability to identify the correct causal task given a query.
Locally Aggregated Feature Attribution on Natural Language Model Understanding
Apr 26, 2022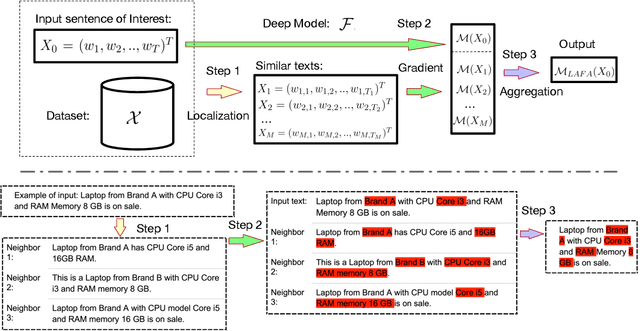
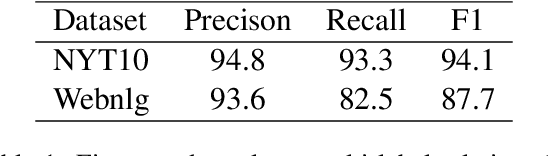
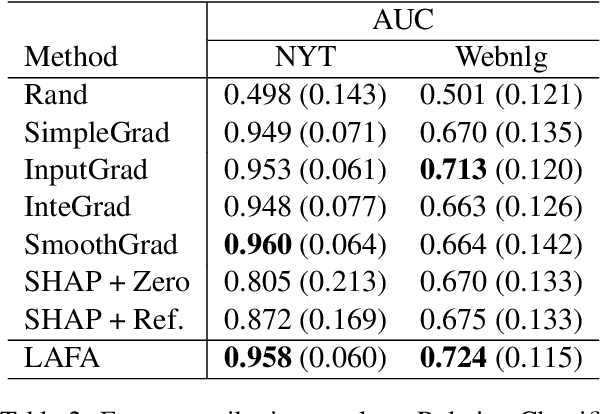
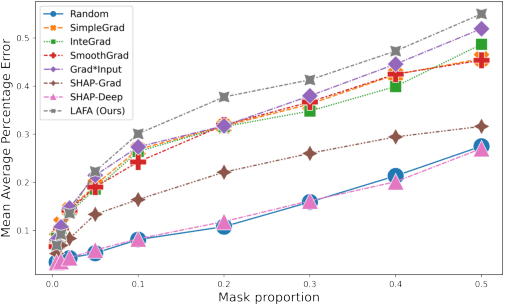
With the growing popularity of deep-learning models, model understanding becomes more important. Much effort has been devoted to demystify deep neural networks for better interpretability. Some feature attribution methods have shown promising results in computer vision, especially the gradient-based methods where effectively smoothing the gradients with reference data is key to a robust and faithful result. However, direct application of these gradient-based methods to NLP tasks is not trivial due to the fact that the input consists of discrete tokens and the "reference" tokens are not explicitly defined. In this work, we propose Locally Aggregated Feature Attribution (LAFA), a novel gradient-based feature attribution method for NLP models. Instead of relying on obscure reference tokens, it smooths gradients by aggregating similar reference texts derived from language model embeddings. For evaluation purpose, we also design experiments on different NLP tasks including Entity Recognition and Sentiment Analysis on public datasets as well as key feature detection on a constructed Amazon catalogue dataset. The superior performance of the proposed method is demonstrated through experiments.