 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfraDiffusion: zero-shot depth map restoration with diffusion models and prompted segmentation from sparse infrastructure point clouds
Sep 03, 2025



Point clouds are widely used for infrastructure monitoring by providing geometric information, where segmentation is required for downstream tasks such as defect detection. Existing research has automated semantic segmentation of structural components, while brick-level segmentation (identifying defects such as spalling and mortar loss) has been primarily conducted from RGB images. However, acquiring high-resolution images is impractical in low-light environments like masonry tunnels. Point clouds, though robust to dim lighting, are typically unstructured, sparse, and noisy, limiting fine-grained segmentation. We present InfraDiffusion, a zero-shot framework that projects masonry point clouds into depth maps using virtual cameras and restores them by adapting the Denoising Diffusion Null-space Model (DDNM). Without task-specific training, InfraDiffusion enhances visual clarity and geometric consistency of depth maps. Experiments on masonry bridge and tunnel point cloud datasets show significant improvements in brick-level segmentation using the Segment Anything Model (SAM), underscoring its potential for automated inspection of masonry assets. Our code and data is available at https://github.com/Jingyixiong/InfraDiffusion-official-implement.
Max-Pooling Dropout for Regularization of Convolutional Neural Networks
Dec 04, 2015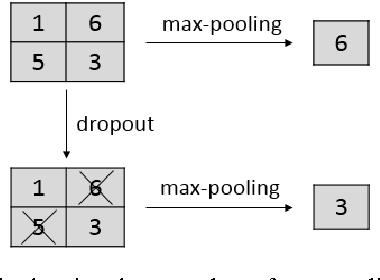
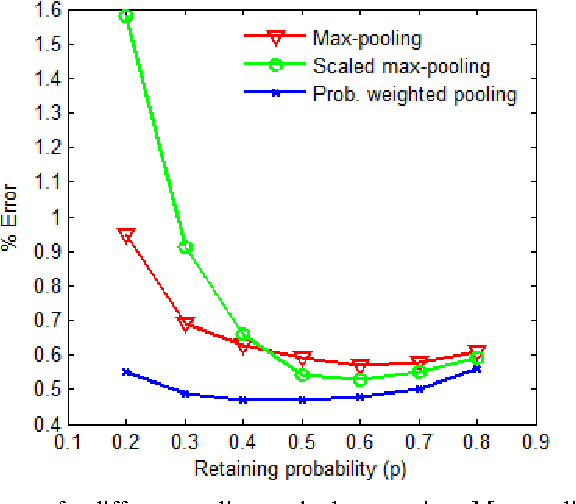
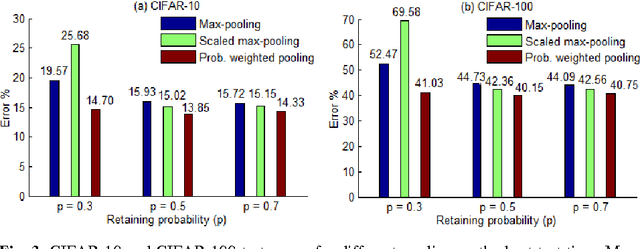
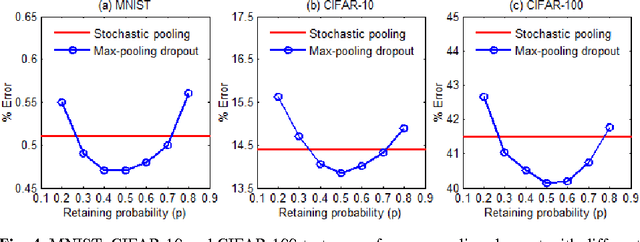
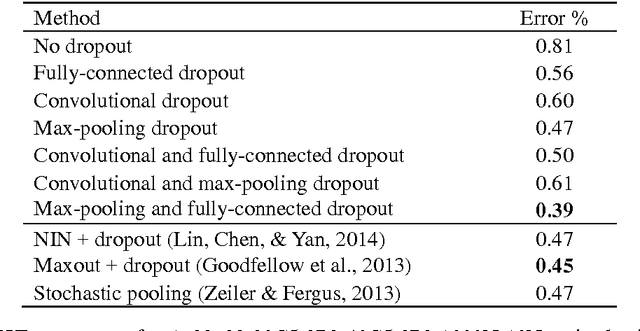
Recently, dropout has seen increasing use in deep learning. For deep convolutional neural networks, dropout is known to work well in fully-connected layers. However, its effect in pooling layers is still not clear. This paper demonstrates that max-pooling dropout is equivalent to randomly picking activation based on a multinomial distribution at training time. In light of this insight, we advocate employing our proposed probabilistic weighted pooling, instead of commonly used max-pooling, to act as model averaging at test time. Empirical evidence validates the superiority of probabilistic weighted pooling. We also compare max-pooling dropout and stochastic pooling, both of which introduce stochasticity based on multinomial distributions at pooling stage.
Towards Dropout Training for Convolutional Neural Networks
Dec 01, 2015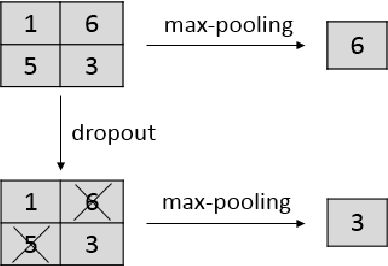

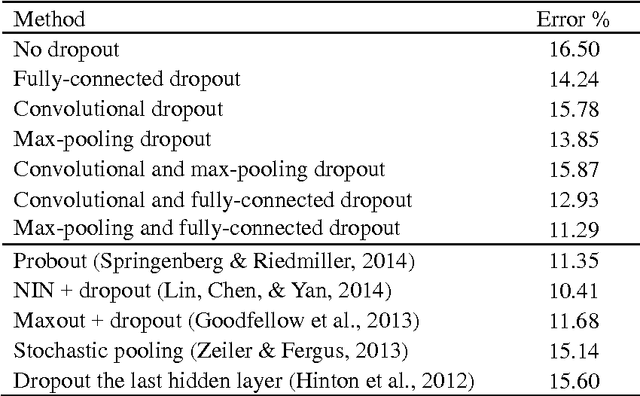
Recently, dropout has seen increasing use in deep learning. For deep convolutional neural networks, dropout is known to work well in fully-connected layers. However, its effect in convolutional and pooling layers is still not clear. This paper demonstrates that max-pooling dropout is equivalent to randomly picking activation based on a multinomial distribution at training time. In light of this insight, we advocate employing our proposed probabilistic weighted pooling, instead of commonly used max-pooling, to act as model averaging at test time. Empirical evidence validates the superiority of probabilistic weighted pooling. We also empirically show that the effect of convolutional dropout is not trivial, despite the dramatically reduced possibility of over-fitting due to the convolutional architecture. Elaborately designing dropout training simultaneously in max-pooling and fully-connected layers, we achieve state-of-the-art performance on MNIST, and very competitive results on CIFAR-10 and CIFAR-100, relative to other approaches without data augmentation. Finally, we compare max-pooling dropout and stochastic pooling, both of which introduce stochasticity based on multinomial distributions at pooling stage.
* This paper has been published in Neural Networks, http://www.sciencedirect.com/science/article/pii/S0893608015001446
Aspect-based Opinion Summarization with Convolutional Neural Networks
Nov 30, 2015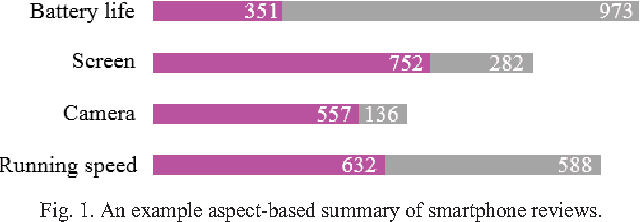
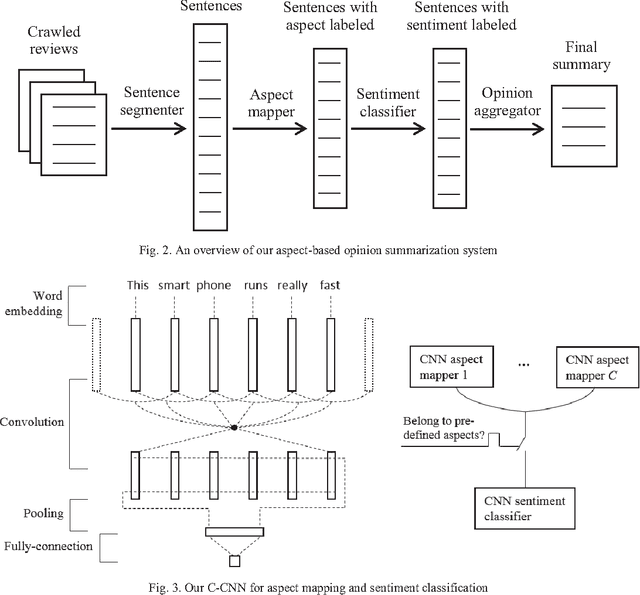
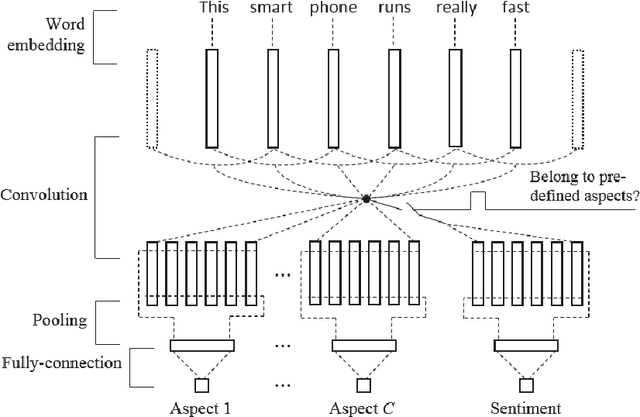
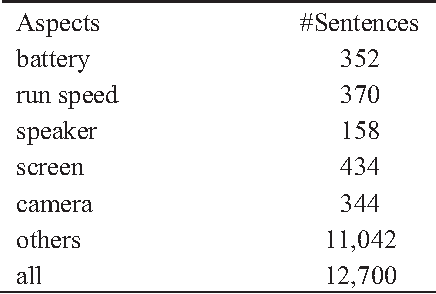
This paper considers Aspect-based Opinion Summarization (AOS) of reviews on particular products. To enable real applications, an AOS system needs to address two core subtasks, aspect extraction and sentiment classification. Most existing approaches to aspect extraction, which use linguistic analysis or topic modeling, are general across different products but not precise enough or suitable for particular products. Instead we take a less general but more precise scheme, directly mapping each review sentence into pre-defined aspects. To tackle aspect mapping and sentiment classification, we propose two Convolutional Neural Network (CNN) based methods, cascaded CNN and multitask CNN. Cascaded CNN contains two levels of convolutional networks. Multiple CNNs at level 1 deal with aspect mapping task, and a single CNN at level 2 deals with sentiment classification. Multitask CNN also contains multiple aspect CNNs and a sentiment CNN, but different networks share the same word embeddings. Experimental results indicate that both cascaded and multitask CNNs outperform SVM-based methods by large margins. Multitask CNN generally performs better than cascaded CNN.