 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-to-Sequence Neural Machine Translation
Sep 16, 2020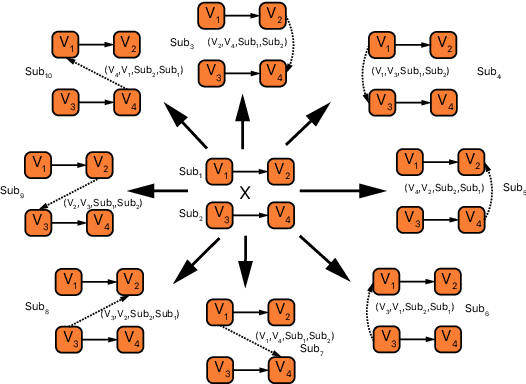
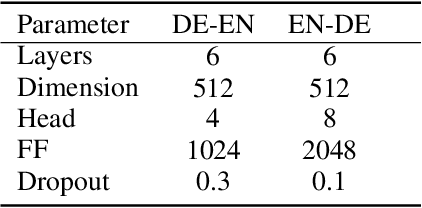
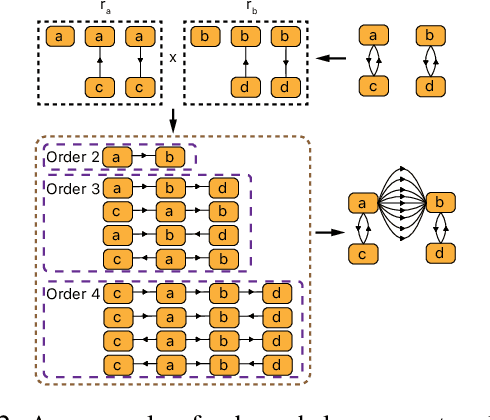
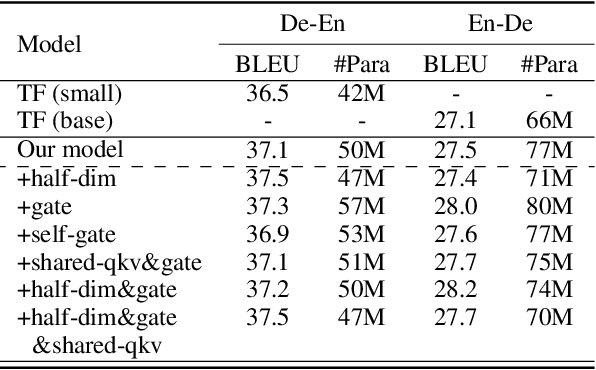
Neural machine translation (NMT) usually works in a seq2seq learning way by viewing either source or target sentence as a linear sequence of words, which can be regarded as a special case of graph, taking words in the sequence as nodes and relationships between words as edges. In the light of the current NMT models more or less capture graph information among the sequence in a latent way, we present a graph-to-sequence model facilitating explicit graph information capturing. In detail, we propose a graph-based SAN-based NMT model called Graph-Transformer by capturing information of subgraphs of different orders in every layers. Subgraphs are put into different groups according to their orders, and every group of subgraphs respectively reflect different levels of dependency between words. For fusing subgraph representations, we empirically explore three methods which weight different groups of subgraphs of different orders. Results of experiments on WMT14 English-German and IWSLT14 German-English show that our method can effectively boost the Transformer with an improvement of 1.1 BLEU points on WMT14 English-German dataset and 1.0 BLEU points on IWSLT14 German-English dataset.
Multi-span Style Extraction for Generative Reading Comprehension
Sep 15, 2020
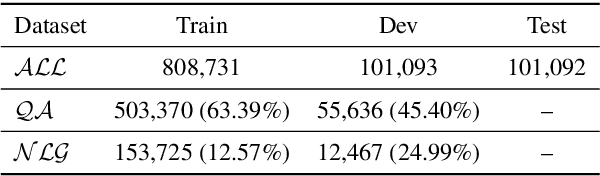
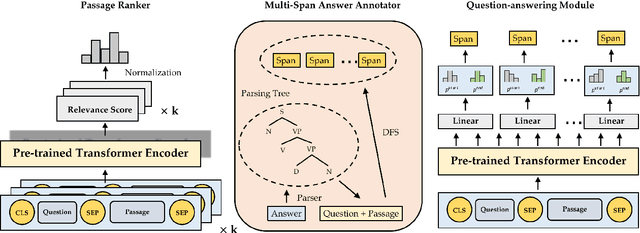
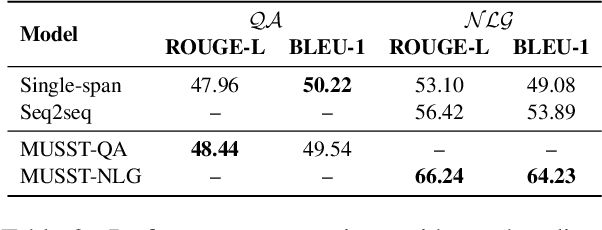
Generative machine reading comprehension (MRC) requires a model to generate well-formed answers. For this type of MRC, answer generation method is crucial to the model performance. However, generative models, which are supposed to be the right model for the task, in generally perform poorly. At the same time, single-span extraction models have been proven effective for extractive MRC, where the answer is constrained to a single span in the passage. Nevertheless, they generally suffer from generating incomplete answers or introducing redundant words when applied to the generative MRC. Thus, we extend the single-span extraction method to multi-span, proposing a new framework which enables generative MRC to be smoothly solved as multi-span extraction. Thorough experiments demonstrate that this novel approach can alleviate the dilemma between generative models and single-span models and produce answers with better-formed syntax and semantics. We will open-source our code for the research community.
Filling the Gap of Utterance-aware and Speaker-aware Representation for Multi-turn Dialogue
Sep 14, 2020
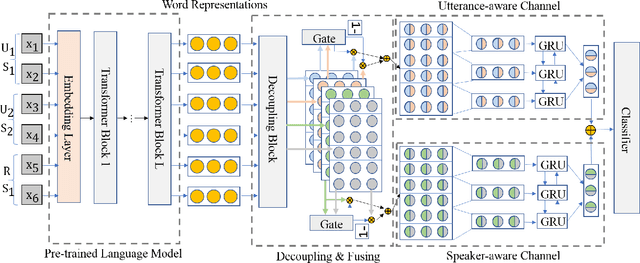
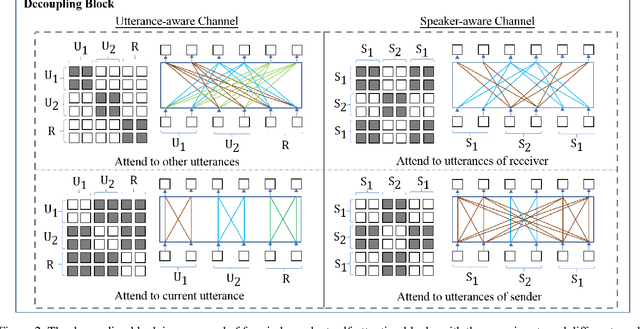
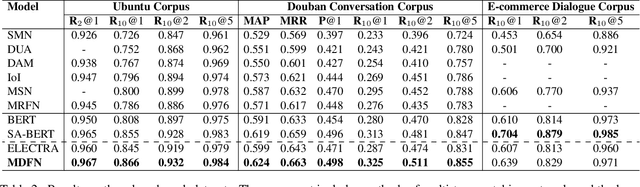
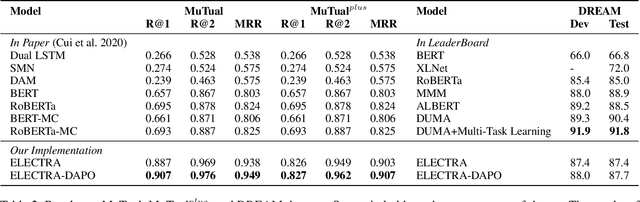
A multi-turn dialogue is composed of multiple utterances from two or more different speaker roles. Thus utterance- and speaker-aware clues are supposed to be well captured in models. However, in the existing retrieval-based multi-turn dialogue modeling, the pre-trained language models (PrLMs) as encoder represent the dialogues coarsely by taking the pairwise dialogue history and candidate response as a whole, the hierarchical information on either utterance interrelation or speaker roles coupled in such representations is not well addressed. In this work, we propose a novel model to fill such a gap by modeling the effective utterance-aware and speaker-aware representations entailed in a dialogue history. In detail, we decouple the contextualized word representations by masking mechanisms in Transformer-based PrLM, making each word only focus on the words in current utterance, other utterances, two speaker roles (i.e., utterances of sender and utterances of receiver), respectively. Experimental results show that our method boosts the strong ELECTRA baseline substantially in four public benchmark datasets, and achieves various new state-of-the-art performance over previous methods. A series of ablation studies are conducted to demonstrate the effectiveness of our method.
Composing Answer from Multi-spans for Reading Comprehension
Sep 14, 2020

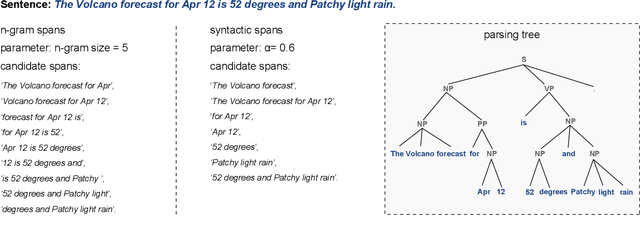
This paper presents a novel method to generate answers for non-extraction machine reading comprehension (MRC) tasks whose answers cannot be simply extracted as one span from the given passages. Using a pointer network-style extractive decoder for such type of MRC may result in unsatisfactory performance when the ground-truth answers are given by human annotators or highly re-paraphrased from parts of the passages. On the other hand, using generative decoder cannot well guarantee the resulted answers with well-formed syntax and semantics when encountering long sentences. Therefore, to alleviate the obvious drawbacks of both sides, we propose an answer making-up method from extracted multi-spans that are learned by our model as highly confident $n$-gram candidates in the given passage. That is, the returned answers are composed of discontinuous multi-spans but not just one consecutive span in the given passages anymore. The proposed method is simple but effective: empirical experiments on MS MARCO show that the proposed method has a better performance on accurately generating long answers, and substantially outperforms two competitive typical one-span and Seq2Seq baseline decoders.
Syntax Role for Neural Semantic Role Labeling
Sep 12, 2020
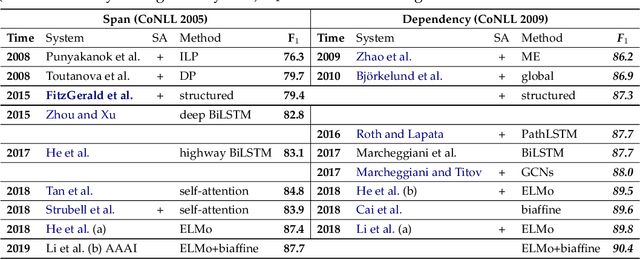
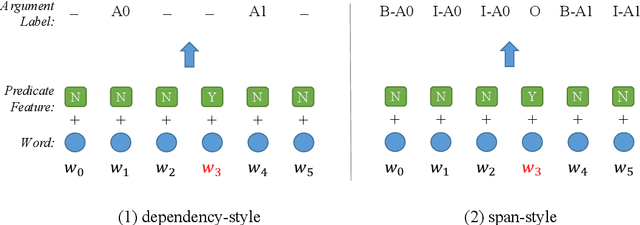
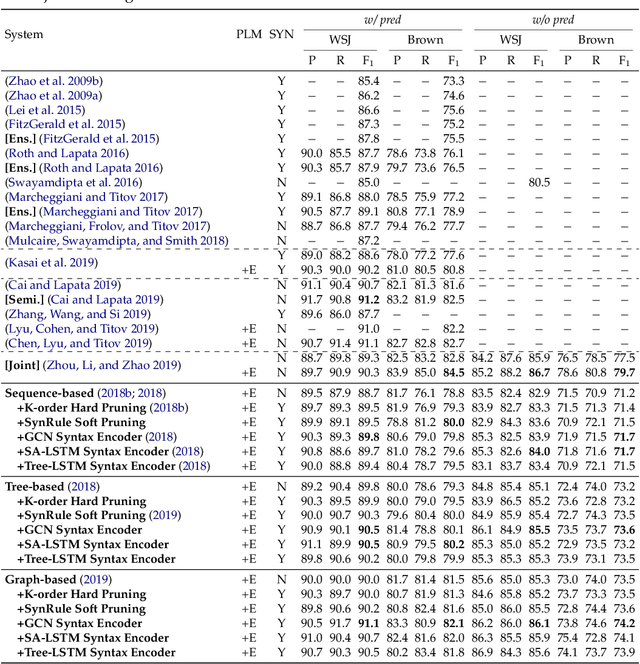
Semantic role labeling (SRL) is dedicated to recognizing the semantic predicate-argument structure of a sentence. Previous studies in terms of traditional models have shown syntactic information can make remarkable contributions to SRL performance; however, the necessity of syntactic information was challenged by a few recent neural SRL studies that demonstrate impressive performance without syntactic backbones and suggest that syntax information becomes much less important for neural semantic role labeling, especially when paired with recent deep neural network and large-scale pre-trained language models. Despite this notion, the neural SRL field still lacks a systematic and full investigation on the relevance of syntactic information in SRL, for both dependency and both monolingual and multilingual settings. This paper intends to quantify the importance of syntactic information for neural SRL in the deep learning framework. We introduce three typical SRL frameworks (baselines), sequence-based, tree-based, and graph-based, which are accompanied by two categories of exploiting syntactic information: syntax pruning-based and syntax feature-based. Experiments are conducted on the CoNLL-2005, 2009, and 2012 benchmarks for all languages available, and results show that neural SRL models can still benefit from syntactic information under certain conditions. Furthermore, we show the quantitative significance of syntax to neural SRL models together with a thorough empirical survey using existing models.
Task-specific Objectives of Pre-trained Language Models for Dialogue Adaptation
Sep 10, 2020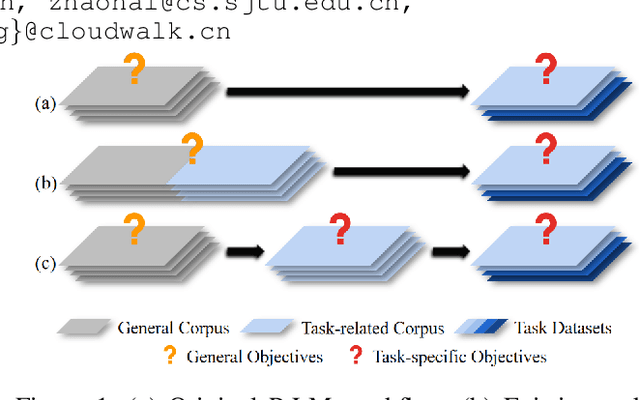

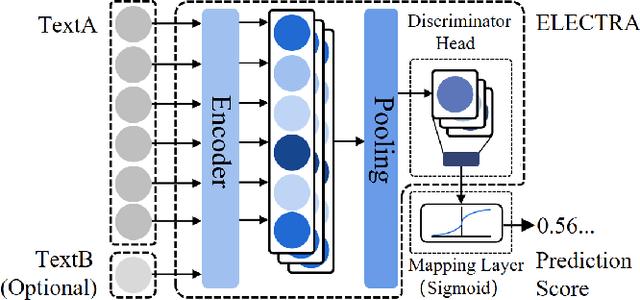
Pre-trained Language Models (PrLMs) have been widely used as backbones in lots of Natural Language Processing (NLP) tasks. The common process of utilizing PrLMs is first pre-training on large-scale general corpora with task-independent LM training objectives, then fine-tuning on task datasets with task-specific training objectives. Pre-training in a task-independent way enables the models to learn language representations, which is universal to some extent, but fails to capture crucial task-specific features in the meantime. This will lead to an incompatibility between pre-training and fine-tuning. To address this issue, we introduce task-specific pre-training on in-domain task-related corpora with task-specific objectives. This procedure is placed between the original two stages to enhance the model understanding capacity of specific tasks. In this work, we focus on Dialogue-related Natural Language Processing (DrNLP) tasks and design a Dialogue-Adaptive Pre-training Objective (DAPO) based on some important qualities for assessing dialogues which are usually ignored by general LM pre-training objectives. PrLMs with DAPO on a large in-domain dialogue corpus are then fine-tuned for downstream DrNLP tasks. Experimental results show that models with DAPO surpass those with general LM pre-training objectives and other strong baselines on downstream DrNLP tasks.
Learning Universal Representations from Word to Sentence
Sep 10, 2020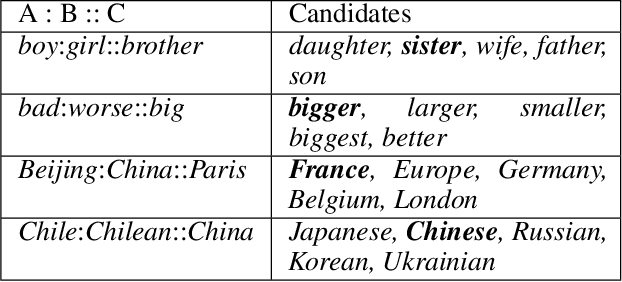
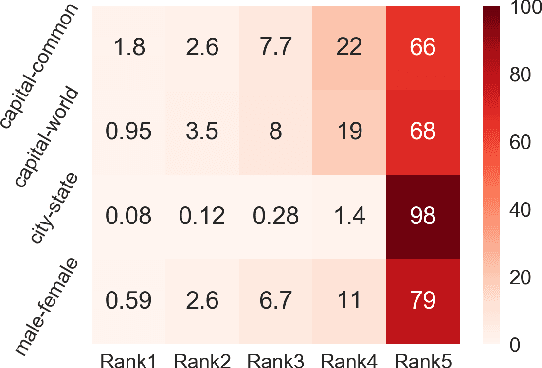

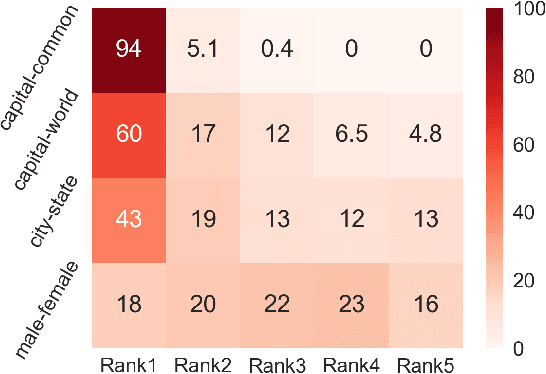
Despite the well-developed cut-edge representation learning for language, most language representation models usually focus on specific level of linguistic unit, which cause great inconvenience when being confronted with handling multiple layers of linguistic objects in a unified way. Thus this work introduces and explores the universal representation learning, i.e., embeddings of different levels of linguistic unit in a uniform vector space through a task-independent evaluation. We present our approach of constructing analogy datasets in terms of words, phrases and sentences and experiment with multiple representation models to examine geometric properties of the learned vector space. Then we empirically verify that well pre-trained Transformer models incorporated with appropriate training settings may effectively yield universal representation. Especially, our implementation of fine-tuning ALBERT on NLI and PPDB datasets achieves the highest accuracy on analogy tasks in different language levels. Further experiments on the insurance FAQ task show effectiveness of universal representation models in real-world applications.
Machine Reading Comprehension: The Role of Contextualized Language Models and Beyond
May 13, 2020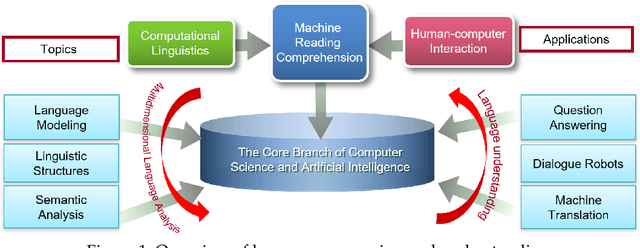

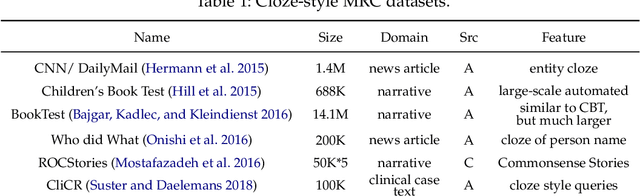
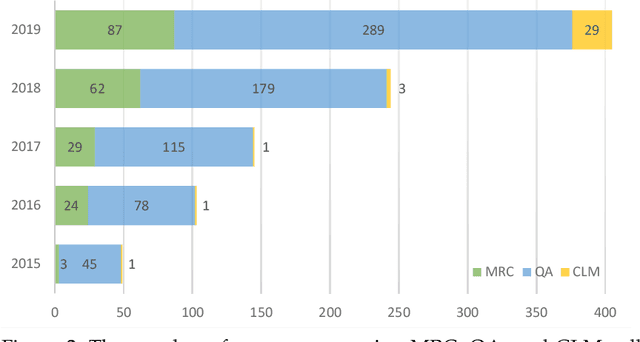
Machine reading comprehension (MRC) aims to teach machines to read and comprehend human languages, which is a long-standing goal of natural language processing (NLP). With the burst of deep neural networks and the evolution of contextualized language models (CLMs), the research of MRC has experienced two significant breakthroughs. MRC and CLM, as a phenomenon, have a great impact on the NLP community. In this survey, we provide a comprehensive and comparative review on MRC covering overall research topics about 1) the origin and development of MRC and CLM, with a particular focus on the role of CLMs; 2) the impact of MRC and CLM to the NLP community; 3) the definition, datasets, and evaluation of MRC; 4) general MRC architecture and technical methods in the view of two-stage Encoder-Decoder solving architecture from the insights of the cognitive process of humans; 5) previous highlights, emerging topics, and our empirical analysis, among which we especially focus on what works in different periods of MRC researches. We propose a full-view categorization and new taxonomies on these topics. The primary views we have arrived at are that 1) MRC boosts the progress from language processing to understanding; 2) the rapid improvement of MRC systems greatly benefits from the development of CLMs; 3) the theme of MRC is gradually moving from shallow text matching to cognitive reasoning.
Bipartite Flat-Graph Network for Nested Named Entity Recognition
May 01, 2020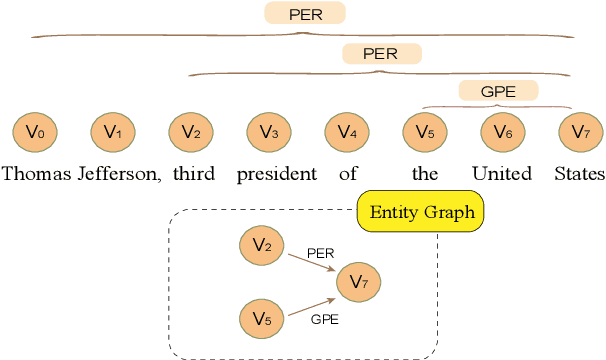
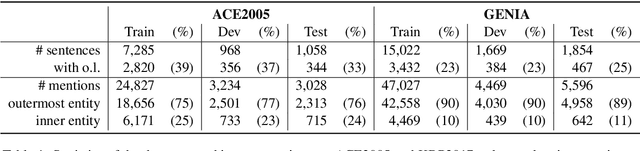
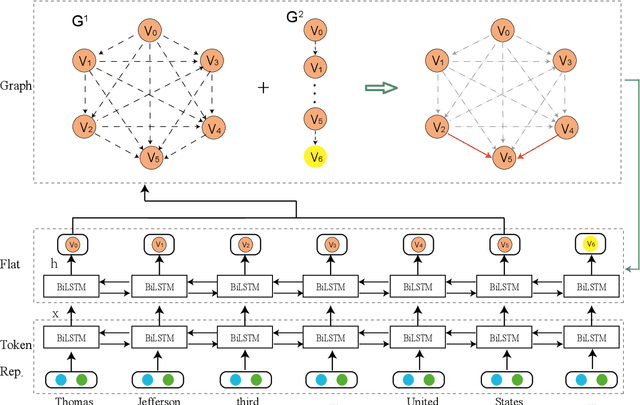
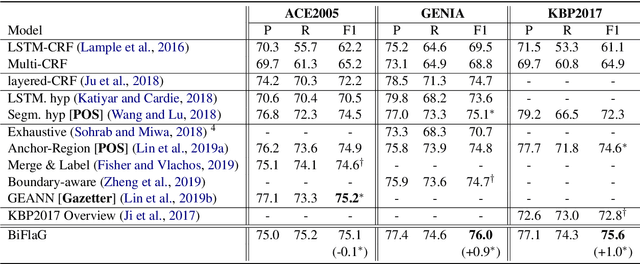
In this paper, we propose a novel bipartite flat-graph network (BiFlaG) for nested named entity recognition (NER), which contains two subgraph modules: a flat NER module for outermost entities and a graph module for all the entities located in inner layers. Bidirectional LSTM (BiLSTM) and graph convolutional network (GCN) are adopted to jointly learn flat entities and their inner dependencies. Different from previous models, which only consider the unidirectional delivery of information from innermost layers to outer ones (or outside-to-inside), our model effectively captures the bidirectional interaction between them. We first use the entities recognized by the flat NER module to construct an entity graph, which is fed to the next graph module. The richer representation learned from graph module carries the dependencies of inner entities and can be exploited to improve outermost entity predictions. Experimental results on three standard nested NER datasets demonstrate that our BiFlaG outperforms previous state-of-the-art models.
Capsule-Transformer for Neural Machine Translation
Apr 30, 2020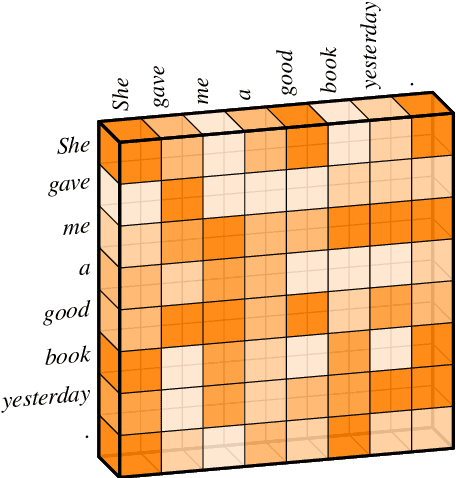

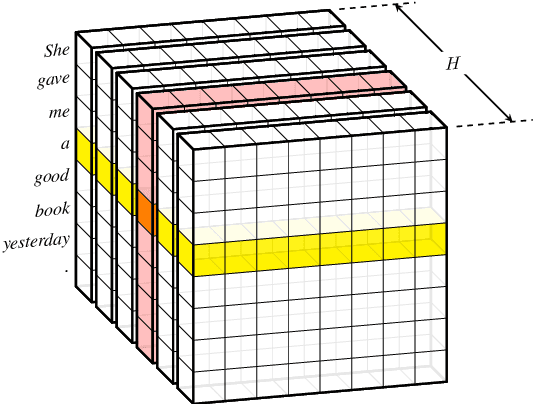
Transformer hugely benefits from its key design of the multi-head self-attention network (SAN), which extracts information from various perspectives through transforming the given input into different subspaces. However, its simple linear transformation aggregation strategy may still potentially fail to fully capture deeper contextualized information. In this paper, we thus propose the capsule-Transformer, which extends the linear transformation into a more general capsule routing algorithm by taking SAN as a special case of capsule network. So that the resulted capsule-Transformer is capable of obtaining a better attention distribution representation of the input sequence via information aggregation among different heads and words. Specifically, we see groups of attention weights in SAN as low layer capsules. By applying the iterative capsule routing algorithm they can be further aggregated into high layer capsules which contain deeper contextualized information. Experimental results on the widely-used machine translation datasets show our proposed capsule-Transformer outperforms strong Transformer baseline significantly.