 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Editing in Masked Diffusion Language Models
Jun 02, 2026Knowledge editing aims to update or correct factual knowledge in a language model. A widely used approach, locate-then-edit, does this in two steps: it first localizes a fact within the model, then edits the weights there. To date, such methods have been developed exclusively on autoregressive models (ARMs). Whether their underlying assumptions hold for masked diffusion models (MDMs), which model text bidirectionally and generate by iterative denoising rather than next-token prediction, remains an open question. We address it by transferring locate-then-edit to MDMs and comparing two MDMs (LLaDA, Dream) with two ARMs (LLaMA, Qwen) at matched scale. Our central finding has two parts. First, where an edit is applied transfers across paradigms: causal tracing highlights the same early-to-mid-layer MLP at the last subject token in both, and editing is most effective there. Second, this shared location does not guarantee a shared outcome. Single-token edits succeed in both, but as targets grow longer, editing degrades systematically in the MDMs but not the ARMs. The failure stems from how the edited fact is generated: producing a multi-token target requires passing through partially unmasked intermediate states for which the edit was never optimized. Guided by this diagnosis, we introduce a simple correction that optimizes the edit for these states, substantially restoring multi-token performance.
Context Robust Knowledge Editing for Language Models
May 29, 2025Knowledge editing (KE) methods offer an efficient way to modify knowledge in large language models. Current KE evaluations typically assess editing success by considering only the edited knowledge without any preceding contexts. In real-world applications, however, preceding contexts often trigger the retrieval of the original knowledge and undermine the intended edit. To address this issue, we develop CHED -- a benchmark designed to evaluate the context robustness of KE methods. Evaluations on CHED show that they often fail when preceding contexts are present. To mitigate this shortcoming, we introduce CoRE, a KE method designed to strengthen context robustness by minimizing context-sensitive variance in hidden states of the model for edited knowledge. This method not only improves the editing success rate in situations where a preceding context is present but also preserves the overall capabilities of the model. We provide an in-depth analysis of the differing impacts of preceding contexts when introduced as user utterances versus assistant responses, and we dissect attention-score patterns to assess how specific tokens influence editing success.
PC-LoRA: Low-Rank Adaptation for Progressive Model Compression with Knowledge Distillation
Jun 13, 2024Low-rank adaption (LoRA) is a prominent method that adds a small number of learnable parameters to the frozen pre-trained weights for parameter-efficient fine-tuning. Prompted by the question, ``Can we make its representation enough with LoRA weights solely at the final phase of finetuning without the pre-trained weights?'' In this work, we introduce Progressive Compression LoRA~(PC-LoRA), which utilizes low-rank adaptation (LoRA) to simultaneously perform model compression and fine-tuning. The PC-LoRA method gradually removes the pre-trained weights during the training process, eventually leaving only the low-rank adapters in the end. Thus, these low-rank adapters replace the whole pre-trained weights, achieving the goals of compression and fine-tuning at the same time. Empirical analysis across various models demonstrates that PC-LoRA achieves parameter and FLOPs compression rates of 94.36%/89.1% for vision models, e.g., ViT-B, and 93.42%/84.2% parameters and FLOPs compressions for language models, e.g., BERT.
WALK-VIO: Walking-motion-Adaptive Leg Kinematic Constraint Visual-Inertial Odometry for Quadruped Robots
Nov 30, 2021
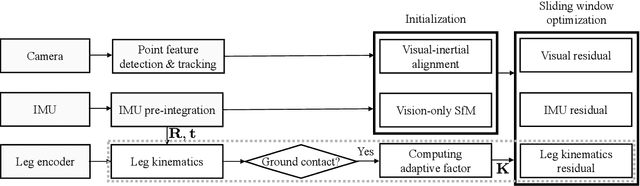
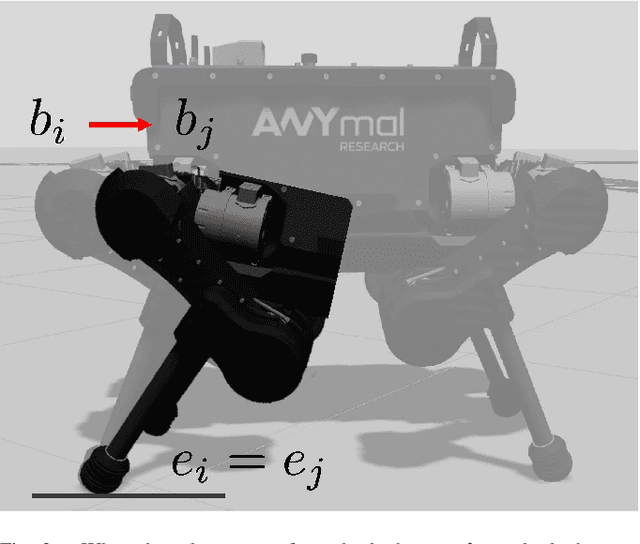
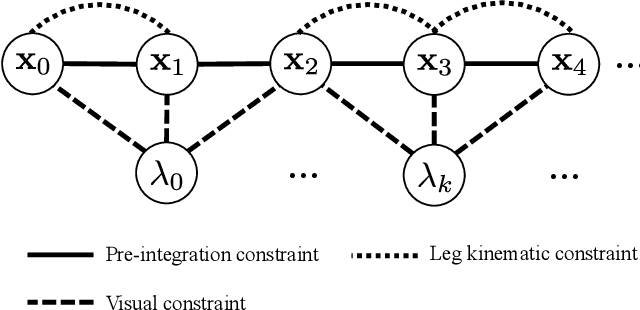
In this paper, WALK-VIO, a novel visual-inertial odometry (VIO) with walking-motion-adaptive leg kinematic constraints that change with body motion for localization of quadruped robots, is proposed. Quadruped robots primarily use VIO because they require fast localization for control and path planning. However, since quadruped robots are mainly used outdoors, extraneous features extracted from the sky or ground cause tracking failures. In addition, the quadruped robots' walking motion cause wobbling, which lowers the localization accuracy due to the camera and inertial measurement unit (IMU). To overcome these limitations, many researchers use VIO with leg kinematic constraints. However, since the quadruped robot's walking motion varies according to the controller, gait, quadruped robots' velocity, and so on, these factors should be considered in the process of adding leg kinematic constraints. We propose VIO that can be used regardless of walking motion by adjusting the leg kinematic constraint factor. In order to evaluate WALK-VIO, we create and publish datasets of quadruped robots that move with various types of walking motion in a simulation environment. In addition, we verified the validity of WALK-VIO through comparison with current state-of-the-art algorithms.