 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Target Speaker Diarization and Separation via Augmented Speaker Embedding Sampling
Aug 08, 2025Traditional speech separation and speaker diarization approaches rely on prior knowledge of target speakers or a predetermined number of participants in audio signals. To address these limitations, recent advances focus on developing enrollment-free methods capable of identifying targets without explicit speaker labeling. This work introduces a new approach to train simultaneous speech separation and diarization using automatic identification of target speaker embeddings, within mixtures. Our proposed model employs a dual-stage training pipeline designed to learn robust speaker representation features that are resilient to background noise interference. Furthermore, we present an overlapping spectral loss function specifically tailored for enhancing diarization accuracy during overlapped speech frames. Experimental results show significant performance gains compared to the current SOTA baseline, achieving 71% relative improvement in DER and 69% in cpWER.
Avengers Assemble: Amalgamation of Non-Semantic Features for Depression Detection
Sep 22, 2024



In this study, we address the challenge of depression detection from speech, focusing on the potential of non-semantic features (NSFs) to capture subtle markers of depression. While prior research has leveraged various features for this task, NSFs-extracted from pre-trained models (PTMs) designed for non-semantic tasks such as paralinguistic speech processing (TRILLsson), speaker recognition (x-vector), and emotion recognition (emoHuBERT)-have shown significant promise. However, the potential of combining these diverse features has not been fully explored. In this work, we demonstrate that the amalgamation of NSFs results in complementary behavior, leading to enhanced depression detection performance. Furthermore, to our end, we introduce a simple novel framework, FuSeR, designed to effectively combine these features. Our results show that FuSeR outperforms models utilizing individual NSFs as well as baseline fusion techniques and obtains state-of-the-art (SOTA) performance in E-DAIC benchmark with RMSE of 5.51 and MAE of 4.48, establishing it as a robust approach for depression detection.
Consistency Based Unsupervised Self-training For ASR Personalisation
Jan 22, 2024



On-device Automatic Speech Recognition (ASR) models trained on speech data of a large population might underperform for individuals unseen during training. This is due to a domain shift between user data and the original training data, differed by user's speaking characteristics and environmental acoustic conditions. ASR personalisation is a solution that aims to exploit user data to improve model robustness. The majority of ASR personalisation methods assume labelled user data for supervision. Personalisation without any labelled data is challenging due to limited data size and poor quality of recorded audio samples. This work addresses unsupervised personalisation by developing a novel consistency based training method via pseudo-labelling. Our method achieves a relative Word Error Rate Reduction (WERR) of 17.3% on unlabelled training data and 8.1% on held-out data compared to a pre-trained model, and outperforms the current state-of-the art methods.
Is Cross-Attention Preferable to Self-Attention for Multi-Modal Emotion Recognition?
Feb 18, 2022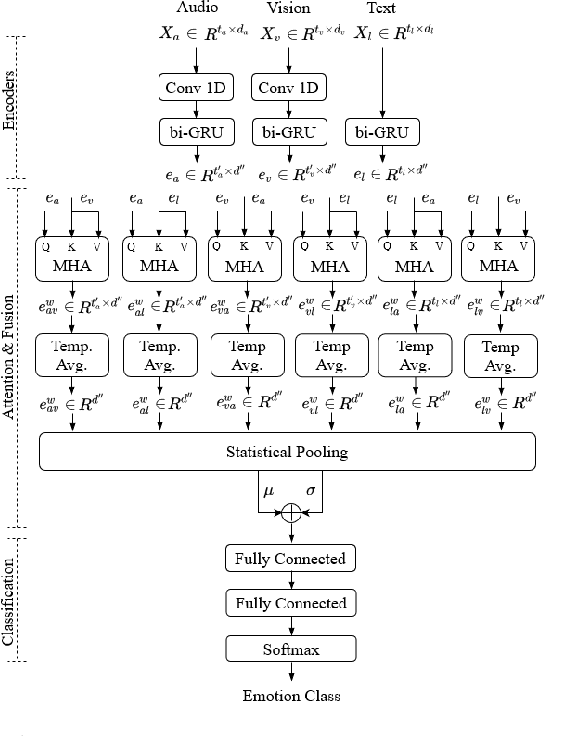
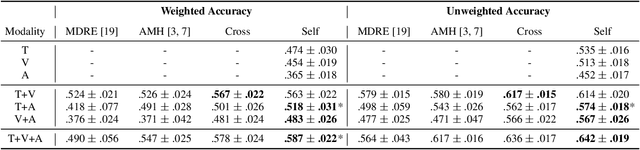


Humans express their emotions via facial expressions, voice intonation and word choices. To infer the nature of the underlying emotion, recognition models may use a single modality, such as vision, audio, and text, or a combination of modalities. Generally, models that fuse complementary information from multiple modalities outperform their uni-modal counterparts. However, a successful model that fuses modalities requires components that can effectively aggregate task-relevant information from each modality. As cross-modal attention is seen as an effective mechanism for multi-modal fusion, in this paper we quantify the gain that such a mechanism brings compared to the corresponding self-attention mechanism. To this end, we implement and compare a cross-attention and a self-attention model. In addition to attention, each model uses convolutional layers for local feature extraction and recurrent layers for global sequential modelling. We compare the models using different modality combinations for a 7-class emotion classification task using the IEMOCAP dataset. Experimental results indicate that albeit both models improve upon the state-of-the-art in terms of weighted and unweighted accuracy for tri- and bi-modal configurations, their performance is generally statistically comparable. The code to replicate the experiments is available at https://github.com/smartcameras/SelfCrossAttn
Cross-Modal Knowledge Transfer via Inter-Modal Translation and Alignment for Affect Recognition
Aug 02, 2021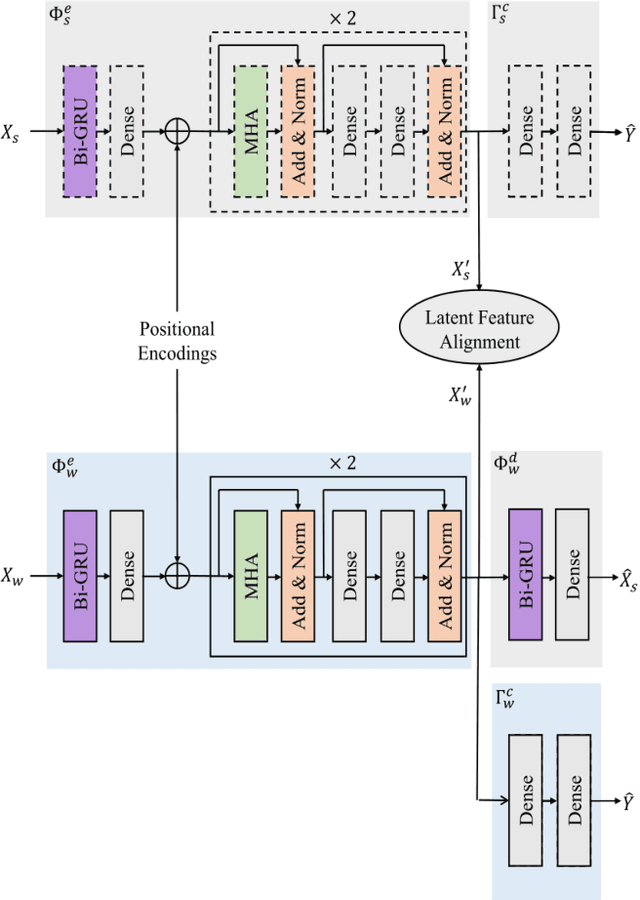
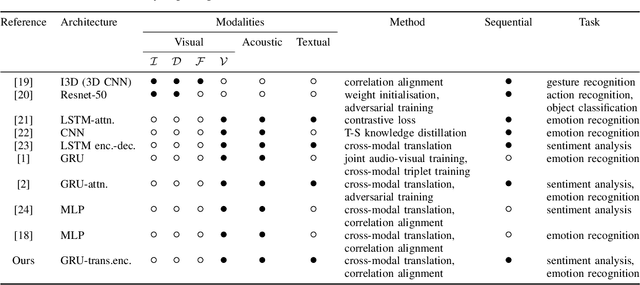
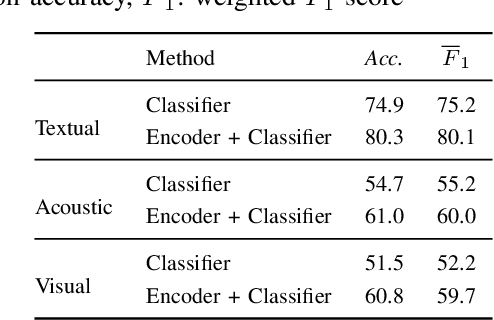
Multi-modal affect recognition models leverage complementary information in different modalities to outperform their uni-modal counterparts. However, due to the unavailability of modality-specific sensors or data, multi-modal models may not be always employable. For this reason, we aim to improve the performance of uni-modal affect recognition models by transferring knowledge from a better-performing (or stronger) modality to a weaker modality during training. Our proposed multi-modal training framework for cross-modal knowledge transfer relies on two main steps. First, an encoder-classifier model creates task-specific representations for the stronger modality. Then, cross-modal translation generates multi-modal intermediate representations, which are also aligned in the latent space with the stronger modality representations. To exploit the contextual information in temporal sequential affect data, we use Bi-GRU and transformer encoder. We validate our approach on two multi-modal affect datasets, namely CMU-MOSI for binary sentiment classification and RECOLA for dimensional emotion regression. The results show that the proposed approach consistently improves the uni-modal test-time performance of the weaker modalities.
Robust Latent Representations via Cross-Modal Translation and Alignment
Nov 03, 2020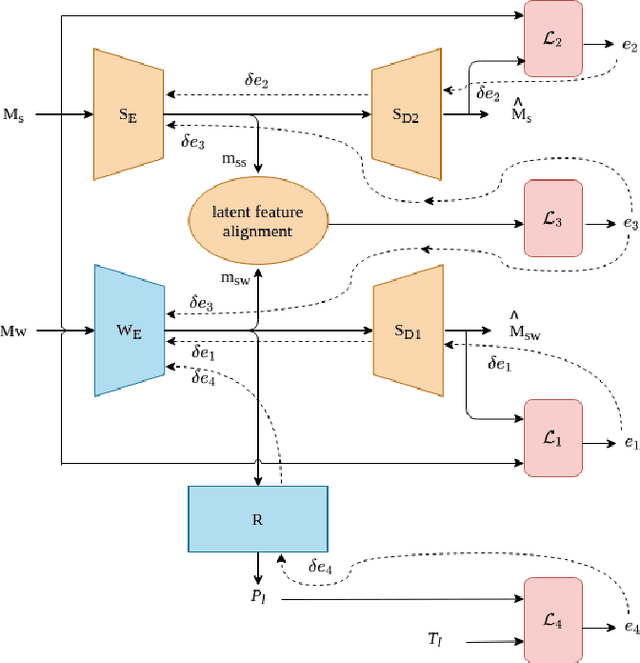
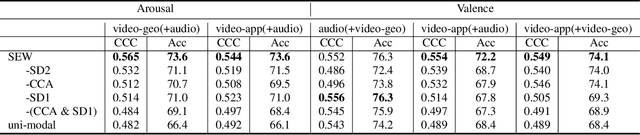
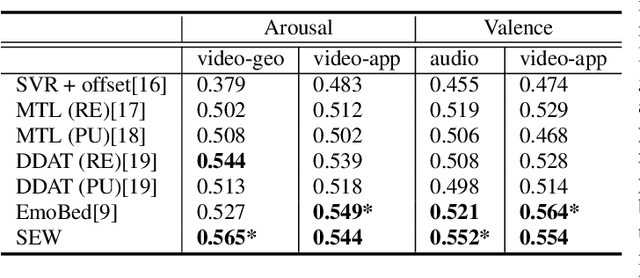
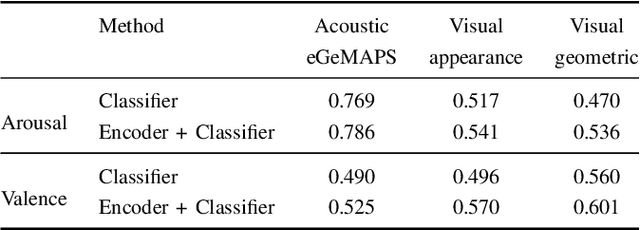
Multi-modal learning relates information across observation modalities of the same physical phenomenon to leverage complementary information. Most multi-modal machine learning methods require that all the modalities used for training are also available for testing. This is a limitation when the signals from some modalities are unavailable or are severely degraded by noise. To address this limitation, we aim to improve the testing performance of uni-modal systems using multiple modalities during training only. The proposed multi-modal training framework uses cross-modal translation and correlation-based latent space alignment to improve the representations of the weaker modalities. The translation from the weaker to the stronger modality generates a multi-modal intermediate encoding that is representative of both modalities. This encoding is then correlated with the stronger modality representations in a shared latent space. We validate the proposed approach on the AVEC 2016 dataset for continuous emotion recognition and show the effectiveness of the approach that achieves state-of-the-art (uni-modal) performance for weaker modalities.