 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Document Representations and Simplicial Curves
Jun 27, 2012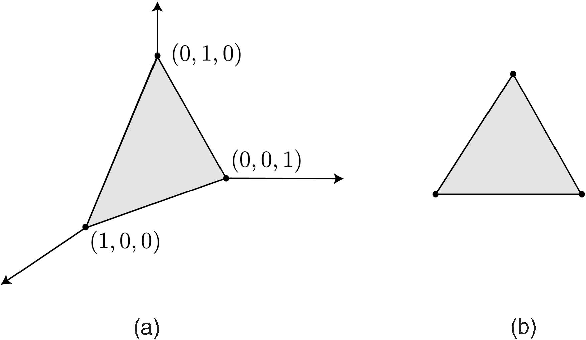
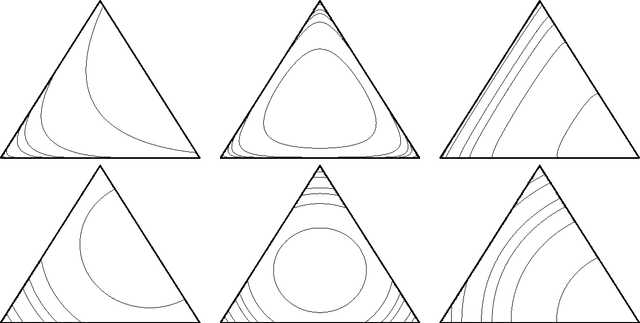
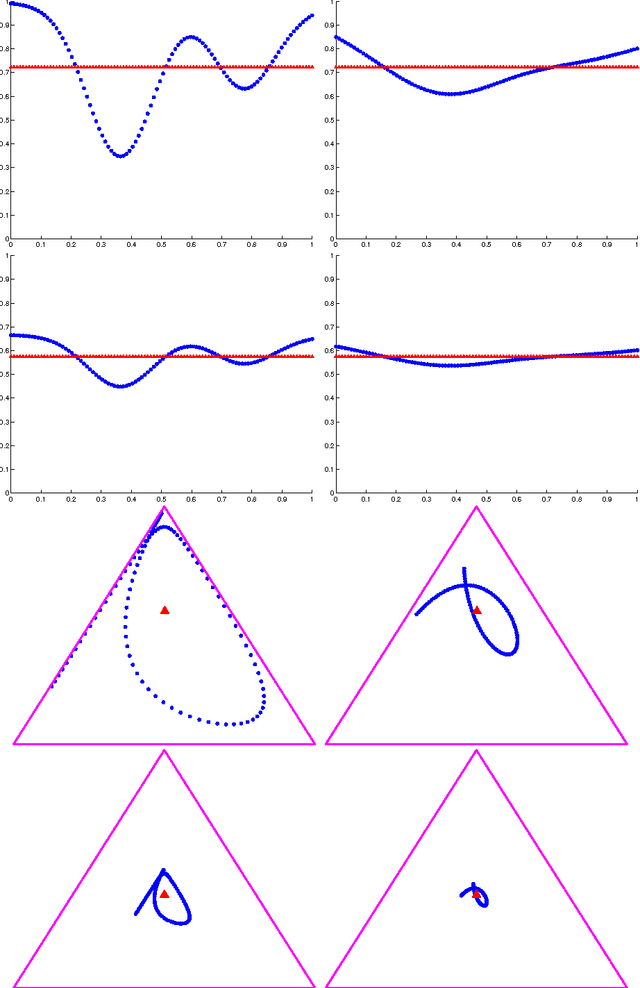
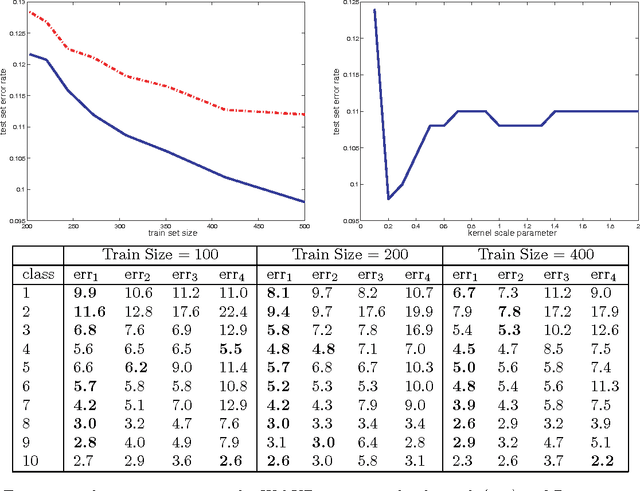
The popular bag of words assumption represents a document as a histogram of word occurrences. While computationally efficient, such a representation is unable to maintain any sequential information. We present a continuous and differentiable sequential document representation that goes beyond the bag of words assumption, and yet is efficient and effective. This representation employs smooth curves in the multinomial simplex to account for sequential information. We discuss the representation and its geometric properties and demonstrate its applicability for the task of text classification.
Statistical Translation, Heat Kernels and Expected Distances
Jun 20, 2012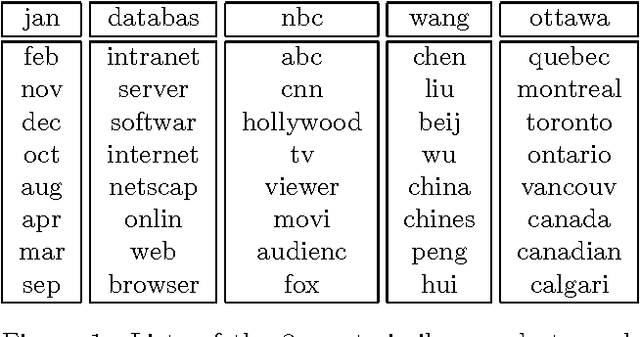

High dimensional structured data such as text and images is often poorly understood and misrepresented in statistical modeling. The standard histogram representation suffers from high variance and performs poorly in general. We explore novel connections between statistical translation, heat kernels on manifolds and graphs, and expected distances. These connections provide a new framework for unsupervised metric learning for text documents. Experiments indicate that the resulting distances are generally superior to their more standard counterparts.
A Comparative Study of Collaborative Filtering Algorithms
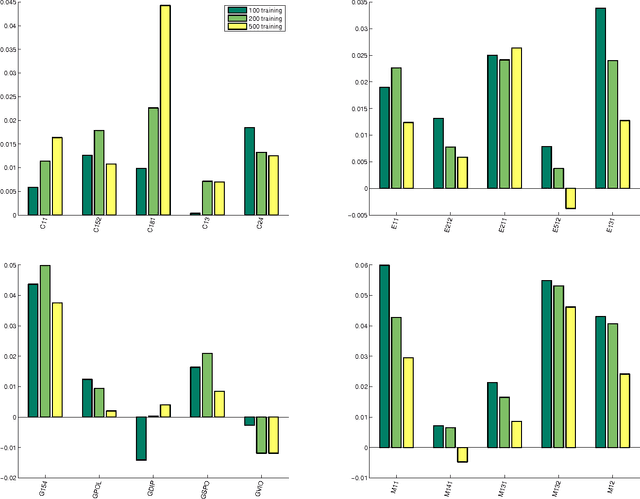
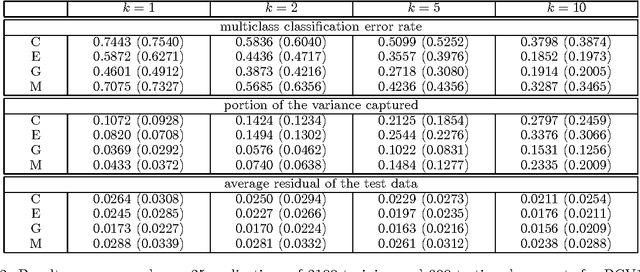
May 14, 2012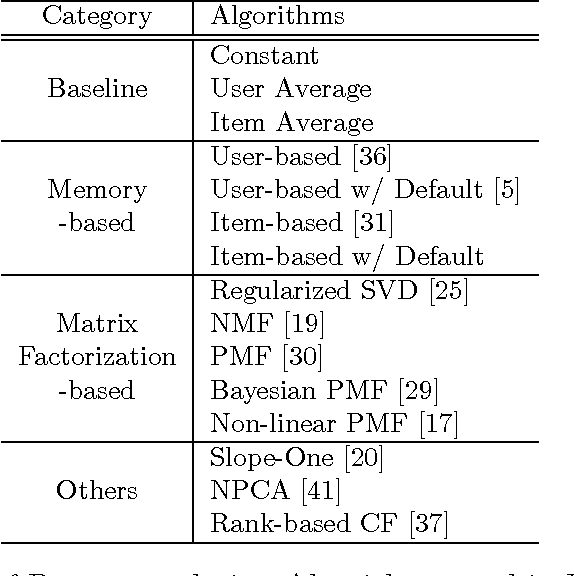

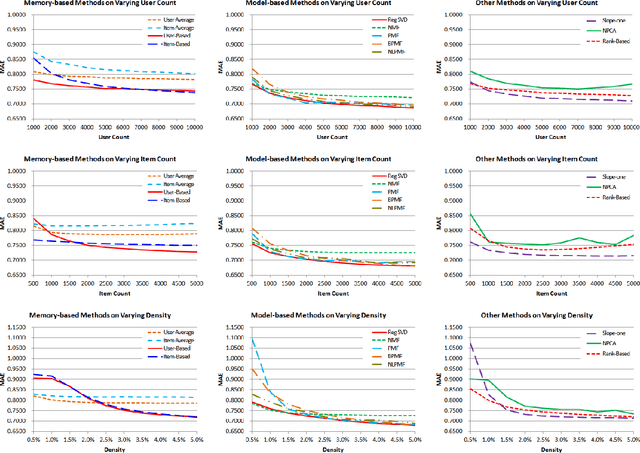
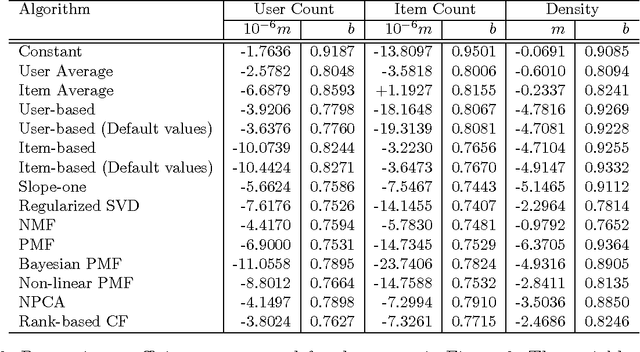
Collaborative filtering is a rapidly advancing research area. Every year several new techniques are proposed and yet it is not clear which of the techniques work best and under what conditions. In this paper we conduct a study comparing several collaborative filtering techniques -- both classic and recent state-of-the-art -- in a variety of experimental contexts. Specifically, we report conclusions controlling for number of items, number of users, sparsity level, performance criteria, and computational complexity. Our conclusions identify what algorithms work well and in what conditions, and contribute to both industrial deployment collaborative filtering algorithms and to the research community.
Domain Knowledge Uncertainty and Probabilistic Parameter Constraints
May 09, 2012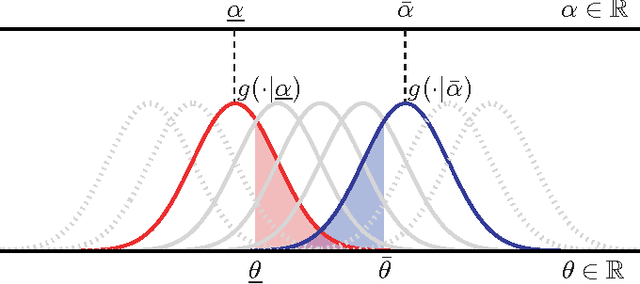
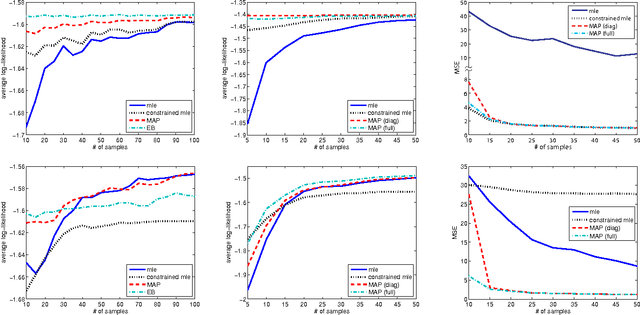
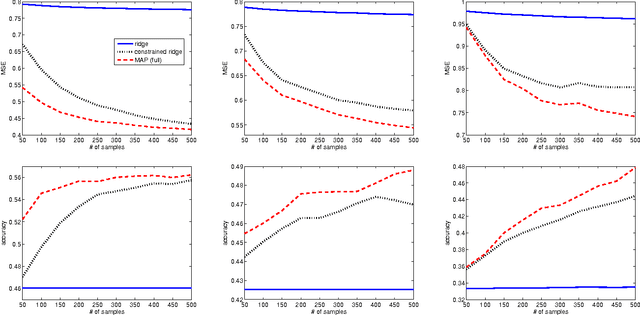
Incorporating domain knowledge into the modeling process is an effective way to improve learning accuracy. However, as it is provided by humans, domain knowledge can only be specified with some degree of uncertainty. We propose to explicitly model such uncertainty through probabilistic constraints over the parameter space. In contrast to hard parameter constraints, our approach is effective also when the domain knowledge is inaccurate and generally results in superior modeling accuracy. We focus on generative and conditional modeling where the parameters are assigned a Dirichlet or Gaussian prior and demonstrate the framework with experiments on both synthetic and real-world data.
Estimating Probabilities in Recommendation Systems
Dec 02, 2010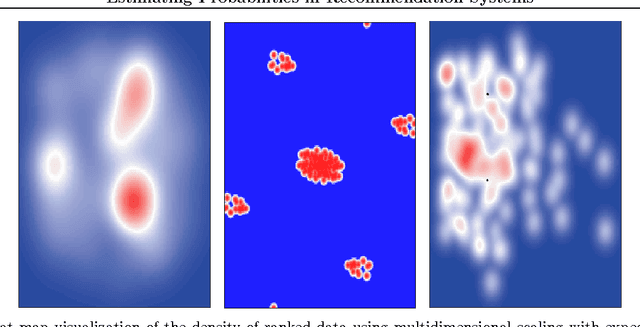
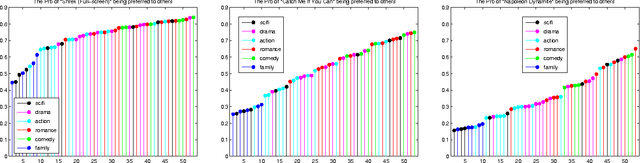
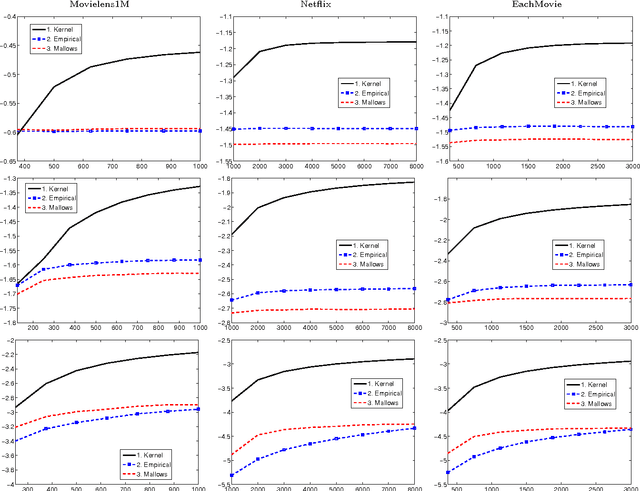
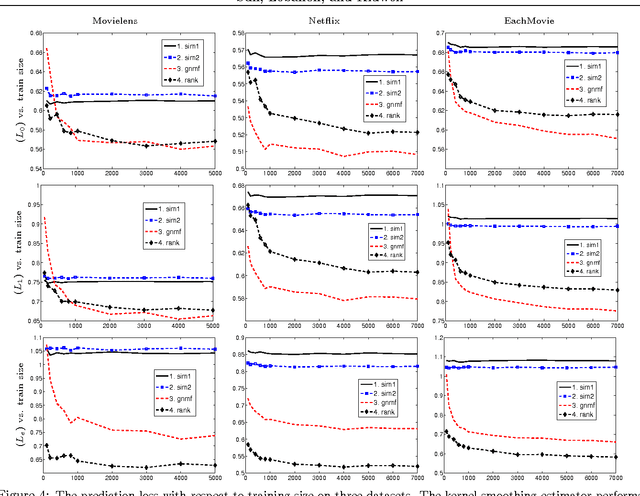
Recommendation systems are emerging as an important business application with significant economic impact. Currently popular systems include Amazon's book recommendations, Netflix's movie recommendations, and Pandora's music recommendations. In this paper we address the problem of estimating probabilities associated with recommendation system data using non-parametric kernel smoothing. In our estimation we interpret missing items as randomly censored observations and obtain efficient computation schemes using combinatorial properties of generating functions. We demonstrate our approach with several case studies involving real world movie recommendation data. The results are comparable with state-of-the-art techniques while also providing probabilistic preference estimates outside the scope of traditional recommender systems.
Unsupervised Supervised Learning II: Training Margin Based Classifiers without Labels
Jul 21, 2010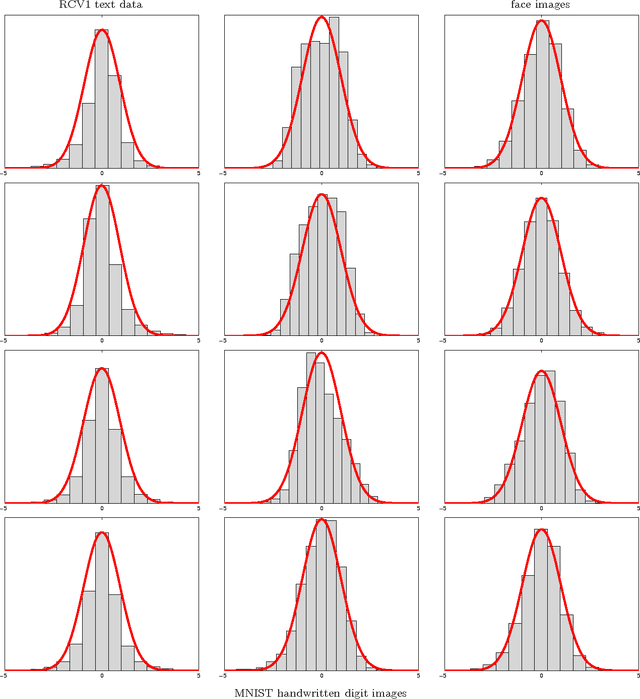
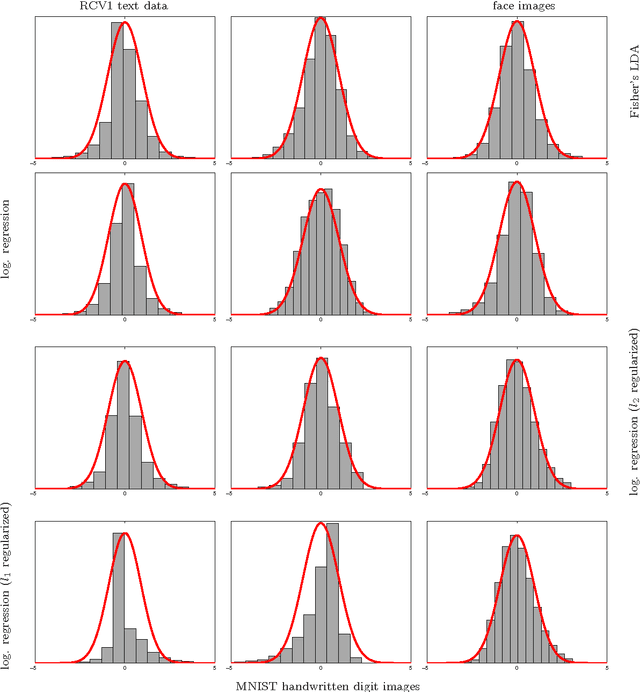
Many popular linear classifiers, such as logistic regression, boosting, or SVM, are trained by optimizing a margin-based risk function. Traditionally, these risk functions are computed based on a labeled dataset. We develop a novel technique for estimating such risks using only unlabeled data and the marginal label distribution. We prove that the proposed risk estimator is consistent on high-dimensional datasets and demonstrate it on synthetic and real-world data. In particular, we show how the estimate is used for evaluating classifiers in transfer learning, and for training classifiers with no labeled data whatsoever.
Statistical and Computational Tradeoffs in Stochastic Composite Likelihood
Mar 02, 2010
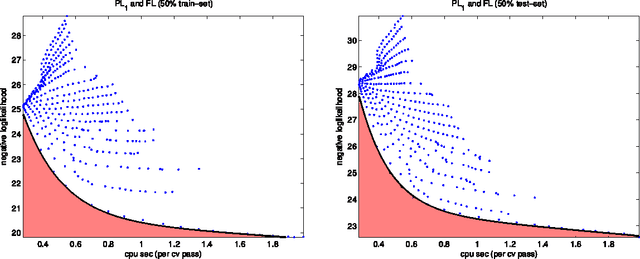
Maximum likelihood estimators are often of limited practical use due to the intensive computation they require. We propose a family of alternative estimators that maximize a stochastic variation of the composite likelihood function. Each of the estimators resolve the computation-accuracy tradeoff differently, and taken together they span a continuous spectrum of computation-accuracy tradeoff resolutions. We prove the consistency of the estimators, provide formulas for their asymptotic variance, statistical robustness, and computational complexity. We discuss experimental results in the context of Boltzmann machines and conditional random fields. The theoretical and experimental studies demonstrate the effectiveness of the estimators when the computational resources are insufficient. They also demonstrate that in some cases reduced computational complexity is associated with robustness thereby increasing statistical accuracy.
Linguistic Geometries for Unsupervised Dimensionality Reduction
Mar 02, 2010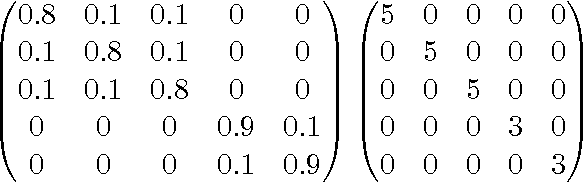
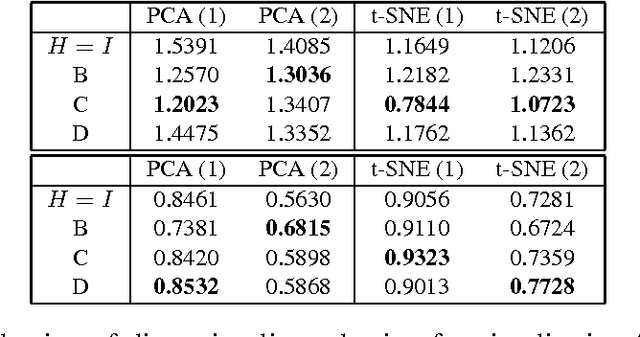
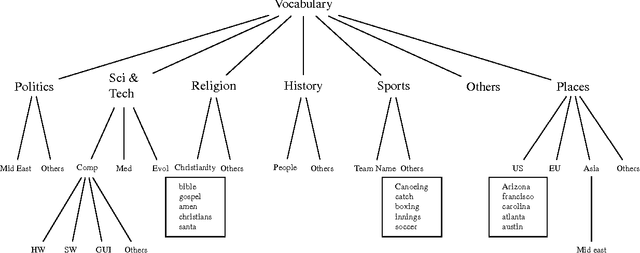
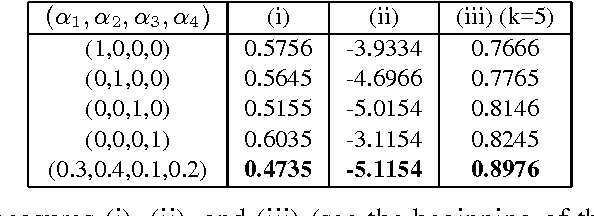
Text documents are complex high dimensional objects. To effectively visualize such data it is important to reduce its dimensionality and visualize the low dimensional embedding as a 2-D or 3-D scatter plot. In this paper we explore dimensionality reduction methods that draw upon domain knowledge in order to achieve a better low dimensional embedding and visualization of documents. We consider the use of geometries specified manually by an expert, geometries derived automatically from corpus statistics, and geometries computed from linguistic resources.
Asymptotic Analysis of Generative Semi-Supervised Learning
Feb 26, 2010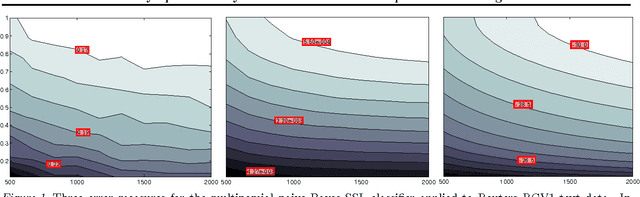
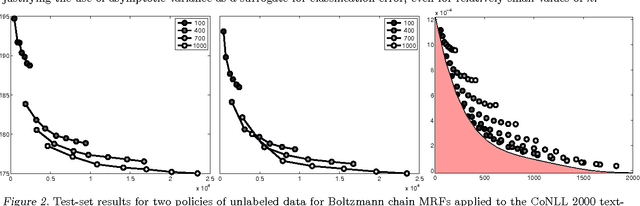
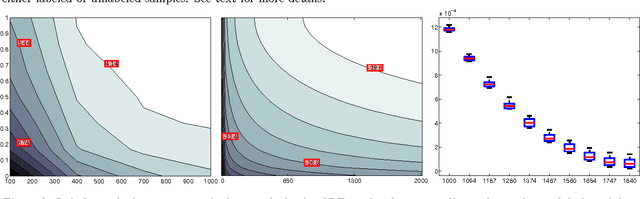
Semisupervised learning has emerged as a popular framework for improving modeling accuracy while controlling labeling cost. Based on an extension of stochastic composite likelihood we quantify the asymptotic accuracy of generative semi-supervised learning. In doing so, we complement distribution-free analysis by providing an alternative framework to measure the value associated with different labeling policies and resolve the fundamental question of how much data to label and in what manner. We demonstrate our approach with both simulation studies and real world experiments using naive Bayes for text classification and MRFs and CRFs for structured prediction in NLP.