 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Causal Approach to Predicting and Improving Human Perceptions of Social Navigation Robots
Mar 11, 2026As mobile robots are increasingly deployed in human environments, enabling them to predict how people perceive them is critical for socially adaptable navigation. Predicting perceptions is challenging for two main reasons: (1) HRI prediction models must learn from limited data, and (2) the obtained models must be interpretable to enable safe and effective interactions. Interpretability is particularly important when a robot is perceived as incompetent (e.g., when the robot suddenly stops or rotates away from the goal), as it allows the robot to explain its reasoning and identify controllable factors to improve performance, requiring causal rather than associative reasoning. To address these challenges, we propose a Causal Bayesian Network designed to predict how people perceive a mobile robot's competence and how they interpret its intent during navigation. Additionally, we introduce a novel method to improve perceived robot competence employing a combinatorial search, guided by the proposed causal model, to identify better navigation behaviors. Our method enhances interpretability and generates counterfactual robot motions while achieving comparable or superior predictive performance to state-of-the-art methods, reaching an F1-score of 0.78 and 0.75 for competence and intention on a binary scale. To further assess our method's ability to improve the perceived robot competence, we conducted an online evaluation in which users rated robot behaviors on a 5-point Likert scale. Our method statistically significantly increased the perceived competence of low-competent robot behavior by 83%.
A Study of Clustering Techniques and Hierarchical Matrix Formats for Kernel Ridge Regression
Mar 27, 2018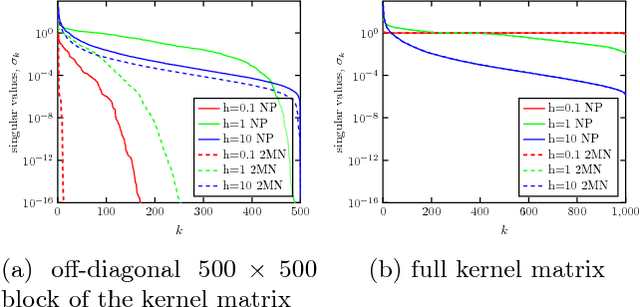

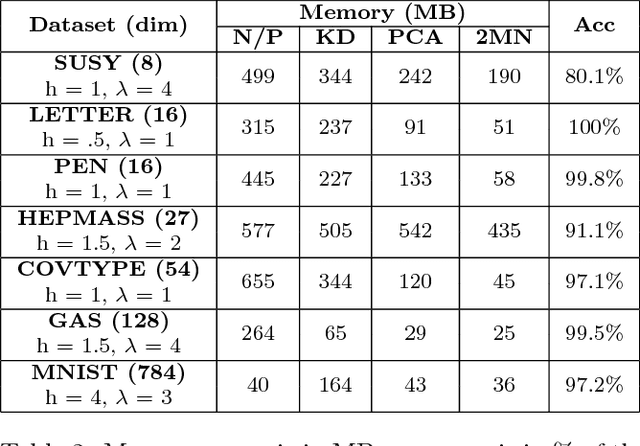
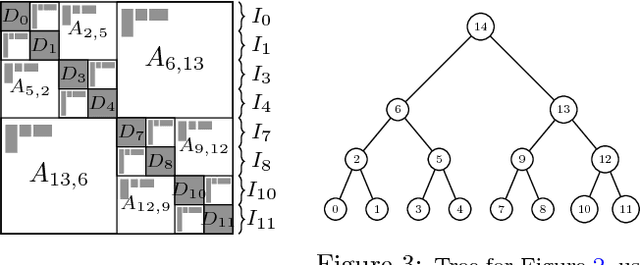
We present memory-efficient and scalable algorithms for kernel methods used in machine learning. Using hierarchical matrix approximations for the kernel matrix the memory requirements, the number of floating point operations, and the execution time are drastically reduced compared to standard dense linear algebra routines. We consider both the general $\mathcal{H}$ matrix hierarchical format as well as Hierarchically Semi-Separable (HSS) matrices. Furthermore, we investigate the impact of several preprocessing and clustering techniques on the hierarchical matrix compression. Effective clustering of the input leads to a ten-fold increase in efficiency of the compression. The algorithms are implemented using the STRUMPACK solver library. These results confirm that --- with correct tuning of the hyperparameters --- classification using kernel ridge regression with the compressed matrix does not lose prediction accuracy compared to the exact --- not compressed --- kernel matrix and that our approach can be extended to $\mathcal{O}(1M)$ datasets, for which computation with the full kernel matrix becomes prohibitively expensive. We present numerical experiments in a distributed memory environment up to 1,024 processors of the NERSC's Cori supercomputer using well-known datasets to the machine learning community that range from dimension 8 up to 784.
* 10 pages, 8 figures