 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual information neural estimation for unsupervised multi-modal registration of brain images
Jan 25, 2022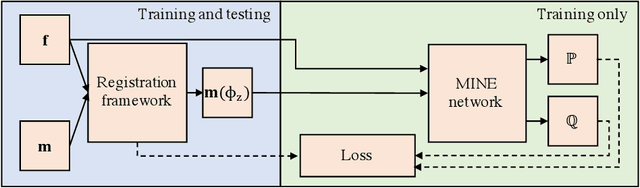
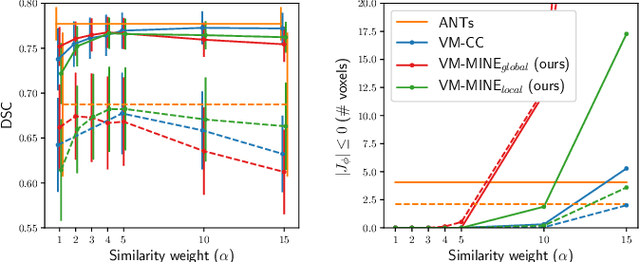
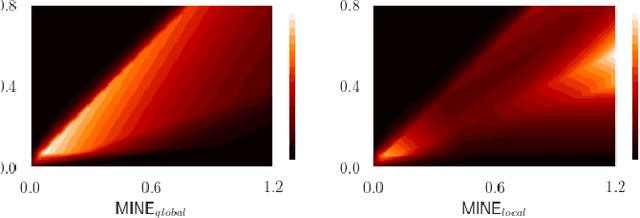
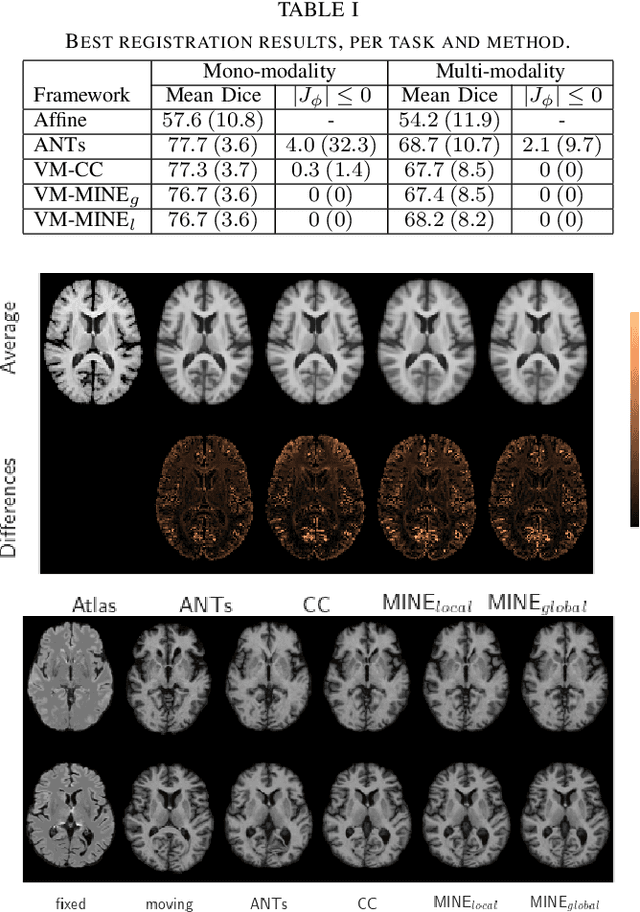
Many applications in image-guided surgery and therapy require fast and reliable non-linear, multi-modal image registration. Recently proposed unsupervised deep learning-based registration methods have demonstrated superior performance compared to iterative methods in just a fraction of the time. Most of the learning-based methods have focused on mono-modal image registration. The extension to multi-modal registration depends on the use of an appropriate similarity function, such as the mutual information (MI). We propose guiding the training of a deep learning-based registration method with MI estimation between an image-pair in an end-to-end trainable network. Our results show that a small, 2-layer network produces competitive results in both mono- and multimodal registration, with sub-second run-times. Comparisons to both iterative and deep learning-based methods show that our MI-based method produces topologically and qualitatively superior results with an extremely low rate of non-diffeomorphic transformations. Real-time clinical application will benefit from a better visual matching of anatomical structures and less registration failures/outliers.
ACPL: Anti-curriculum Pseudo-labelling for Semi-supervised Medical Image Classification
Dec 19, 2021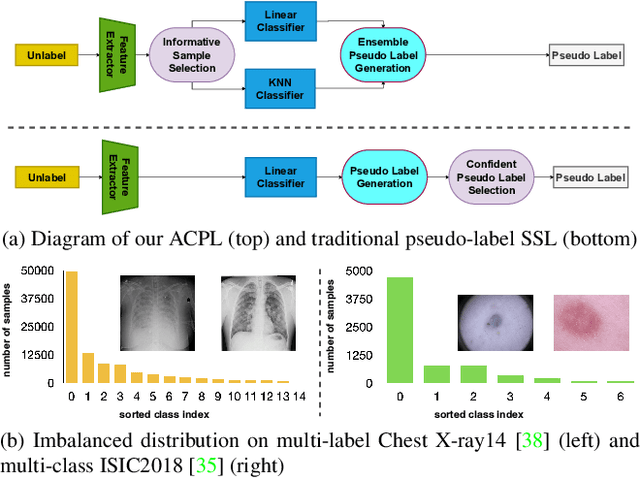
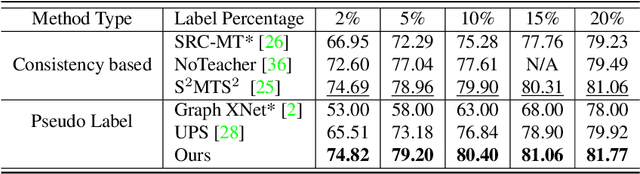
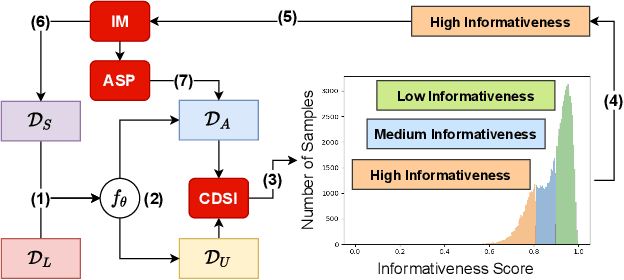
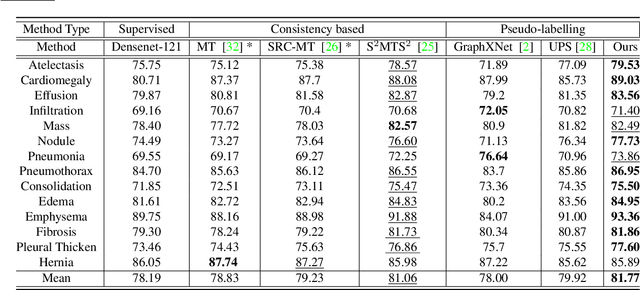
Effective semi-supervised learning (SSL) in medical im-age analysis (MIA) must address two challenges: 1) workeffectively on both multi-class (e.g., lesion classification)and multi-label (e.g., multiple-disease diagnosis) problems,and 2) handle imbalanced learning (because of the highvariance in disease prevalence). One strategy to explorein SSL MIA is based on the pseudo labelling strategy, butit has a few shortcomings. Pseudo-labelling has in generallower accuracy than consistency learning, it is not specifi-cally design for both multi-class and multi-label problems,and it can be challenged by imbalanced learning. In this paper, unlike traditional methods that select confident pseudo label by threshold, we propose a new SSL algorithm, called anti-curriculum pseudo-labelling (ACPL), which introduces novel techniques to select informative unlabelled samples, improving training balance and allowing the model to work for both multi-label and multi-class problems, and to estimate pseudo labels by an accurate ensemble of classifiers(improving pseudo label accuracy). We run extensive experiments to evaluate ACPL on two public medical image classification benchmarks: Chest X-Ray14 for thorax disease multi-label classification and ISIC2018 for skin lesion multi-class classification. Our method outperforms previous SOTA SSL methods on both datasets.
Perturbed and Strict Mean Teachers for Semi-supervised Semantic Segmentation
Nov 25, 2021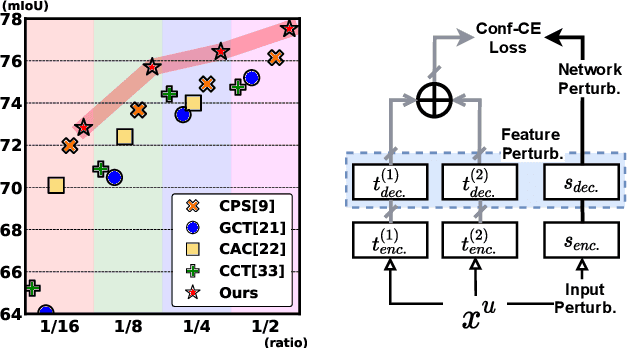
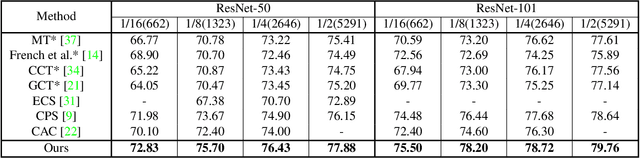
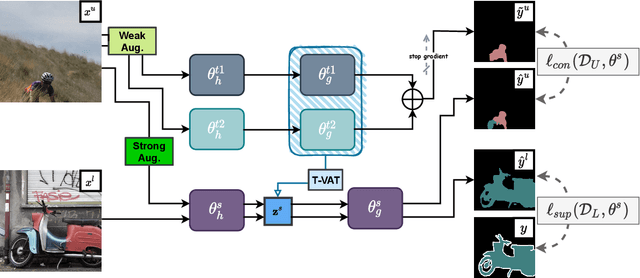
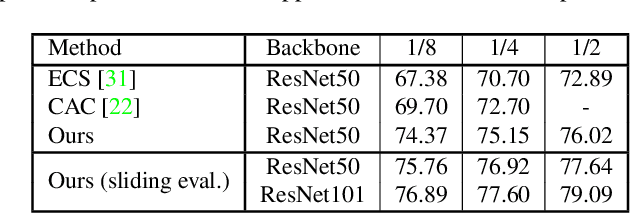
Consistency learning using input image, feature, or network perturbations has shown remarkable results in semi-supervised semantic segmentation, but this approach can be seriously affected by inaccurate predictions of unlabelled training images. There are two consequences of these inaccurate predictions: 1) the training based on the ``strict'' cross-entropy (CE) loss can easily overfit prediction mistakes, leading to confirmation bias; and 2) the perturbations applied to these inaccurate predictions will use potentially erroneous predictions as training signals, degrading consistency learning. In this paper, we address the prediction accuracy problem of consistency learning methods with novel extensions of the mean-teacher (MT) model, which include a new auxiliary teacher, and the replacement of MT's mean square error (MSE) by a stricter confidence-weighted cross-entropy (Conf-CE) loss. The accurate prediction by this model allows us to use a challenging combination of network, input data and feature perturbations to improve the consistency learning generalisation, where the feature perturbations consist of a new adversarial perturbation. Results on public benchmarks show that our approach achieves remarkable improvements over the previous SOTA methods in the field.
Pixel-wise Energy-biased Abstention Learning for Anomaly Segmentation on Complex Urban Driving Scenes
Nov 24, 2021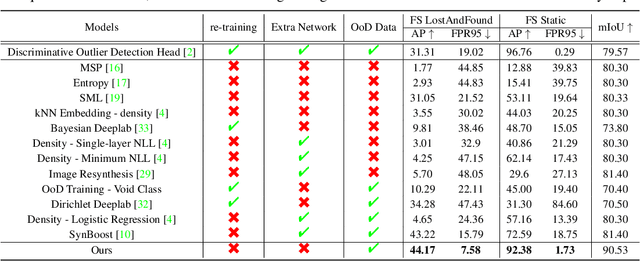
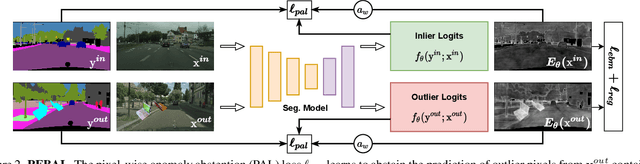
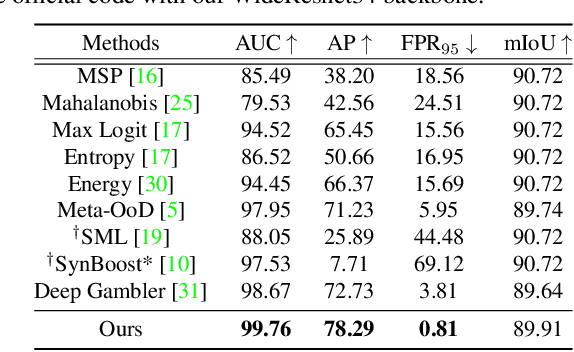
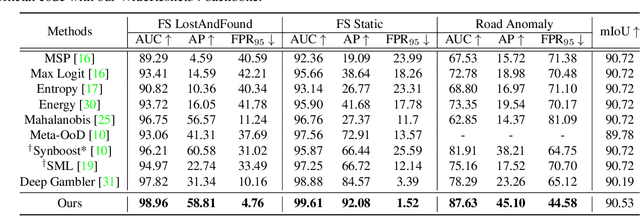
State-of-the-art (SOTA) anomaly segmentation approaches on complex urban driving scenes explore pixel-wise classification uncertainty learned from outlier exposure, or external reconstruction models. However, previous uncertainty approaches that directly associate high uncertainty to anomaly may sometimes lead to incorrect anomaly predictions, and external reconstruction models tend to be too inefficient for real-time self-driving embedded systems. In this paper, we propose a new anomaly segmentation method, named pixel-wise energy-biased abstention learning (PEBAL), that explores pixel-wise abstention learning (AL) with a model that learns an adaptive pixel-level anomaly class, and an energy-based model (EBM) that learns inlier pixel distribution. More specifically, PEBAL is based on a non-trivial joint training of EBM and AL, where EBM is trained to output high-energy for anomaly pixels (from outlier exposure) and AL is trained such that these high-energy pixels receive adaptive low penalty for being included to the anomaly class. We extensively evaluate PEBAL against the SOTA and show that it achieves the best performance across four benchmarks. Code is available at https://github.com/tianyu0207/PEBAL.
A Hierarchical Multi-Task Approach to Gastrointestinal Image Analysis
Nov 16, 2021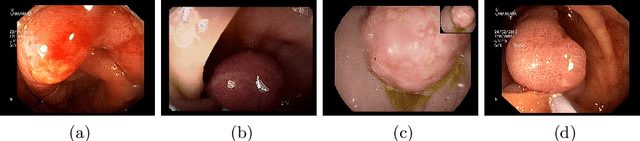
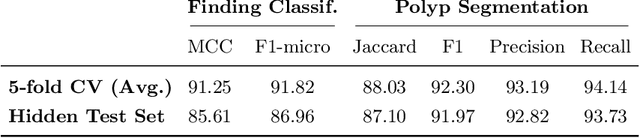
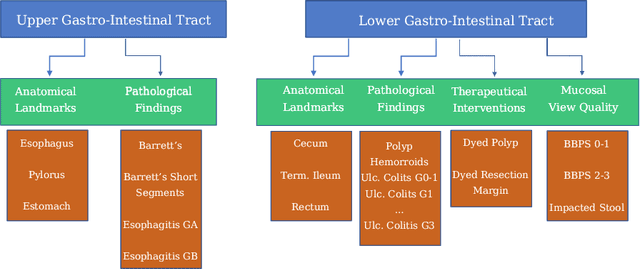
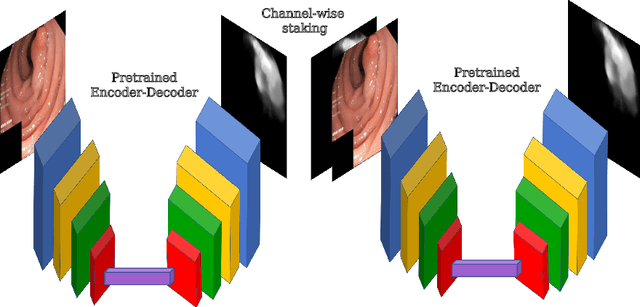
A large number of different lesions and pathologies can affect the human digestive system, resulting in life-threatening situations. Early detection plays a relevant role in the successful treatment and the increase of current survival rates to, e.g., colorectal cancer. The standard procedure enabling detection, endoscopic video analysis, generates large quantities of visual data that need to be carefully analyzed by an specialist. Due to the wide range of color, shape, and general visual appearance of pathologies, as well as highly varying image quality, such process is greatly dependent on the human operator experience and skill. In this work, we detail our solution to the task of multi-category classification of images from the gastrointestinal (GI) human tract within the 2020 Endotect Challenge. Our approach is based on a Convolutional Neural Network minimizing a hierarchical error function that takes into account not only the finding category, but also its location within the GI tract (lower/upper tract), and the type of finding (pathological finding/therapeutic intervention/anatomical landmark/mucosal views' quality). We also describe in this paper our solution for the challenge task of polyp segmentation in colonoscopies, which was addressed with a pretrained double encoder-decoder network. Our internal cross-validation results show an average performance of 91.25 Mathews Correlation Coefficient (MCC) and 91.82 Micro-F1 score for the classification task, and a 92.30 F1 score for the polyp segmentation task. The organization provided feedback on the performance in a hidden test set for both tasks, which resulted in 85.61 MCC and 86.96 F1 score for classification, and 91.97 F1 score for polyp segmentation. At the time of writing no public ranking for this challenge had been released.
Convolutional Nets Versus Vision Transformers for Diabetic Foot Ulcer Classification
Nov 12, 2021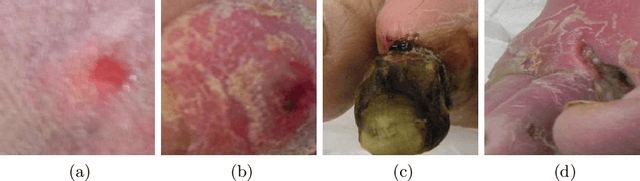
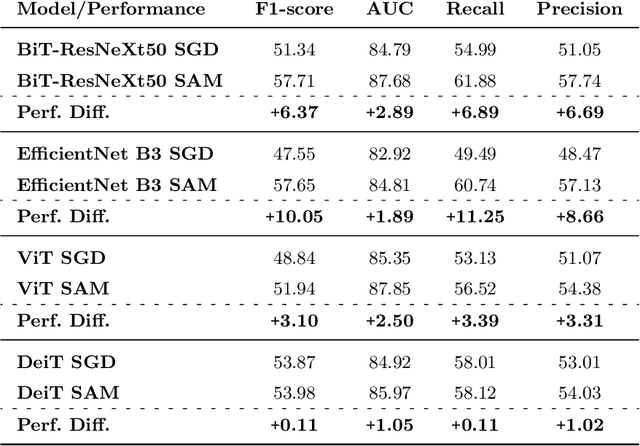
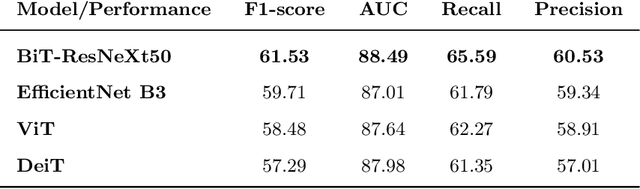
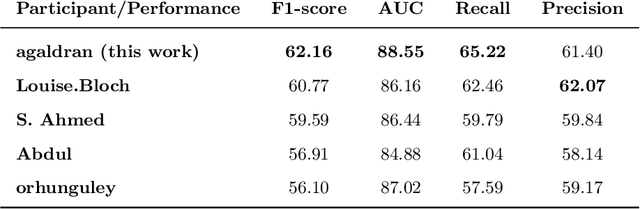
This paper compares well-established Convolutional Neural Networks (CNNs) to recently introduced Vision Transformers for the task of Diabetic Foot Ulcer Classification, in the context of the DFUC 2021 Grand-Challenge, in which this work attained the first position. Comprehensive experiments demonstrate that modern CNNs are still capable of outperforming Transformers in a low-data regime, likely owing to their ability for better exploiting spatial correlations. In addition, we empirically demonstrate that the recent Sharpness-Aware Minimization (SAM) optimization algorithm considerably improves the generalization capability of both kinds of models. Our results demonstrate that for this task, the combination of CNNs and the SAM optimization process results in superior performance than any other of the considered approaches.
PropMix: Hard Sample Filtering and Proportional MixUp for Learning with Noisy Labels
Oct 22, 2021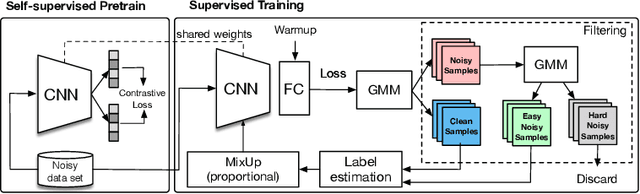
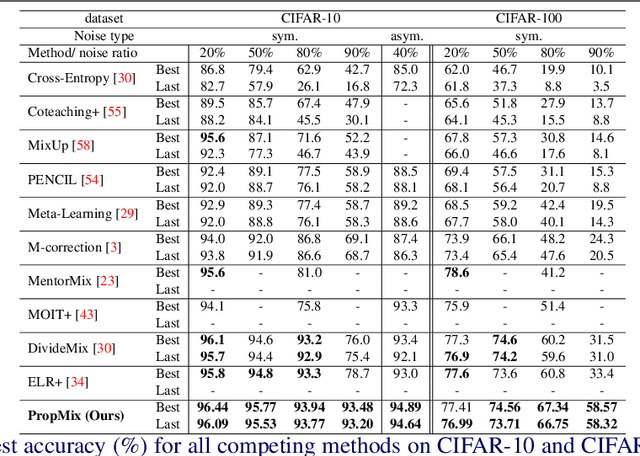
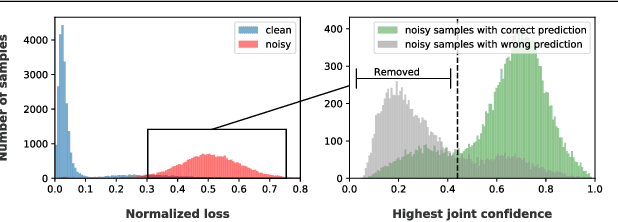
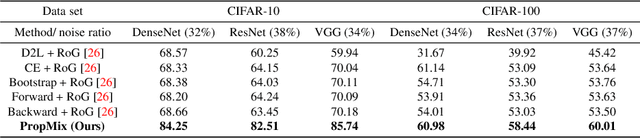
The most competitive noisy label learning methods rely on an unsupervised classification of clean and noisy samples, where samples classified as noisy are re-labelled and "MixMatched" with the clean samples. These methods have two issues in large noise rate problems: 1) the noisy set is more likely to contain hard samples that are in-correctly re-labelled, and 2) the number of samples produced by MixMatch tends to be reduced because it is constrained by the small clean set size. In this paper, we introduce the learning algorithm PropMix to handle the issues above. PropMix filters out hard noisy samples, with the goal of increasing the likelihood of correctly re-labelling the easy noisy samples. Also, PropMix places clean and re-labelled easy noisy samples in a training set that is augmented with MixUp, removing the clean set size constraint and including a large proportion of correctly re-labelled easy noisy samples. We also include self-supervised pre-training to improve robustness to high noisy label scenarios. Our experiments show that PropMix has state-of-the-art (SOTA) results on CIFAR-10/-100(with symmetric, asymmetric and semantic label noise), Red Mini-ImageNet (from the Controlled Noisy Web Labels), Clothing1M and WebVision. In severe label noise bench-marks, our results are substantially better than other methods. The code is available athttps://github.com/filipe-research/PropMix.
Double Encoder-Decoder Networks for Gastrointestinal Polyp Segmentation
Oct 05, 2021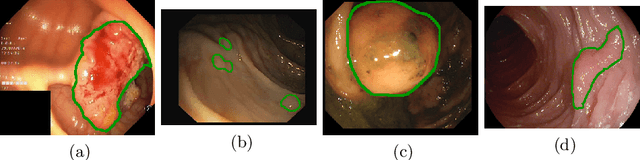

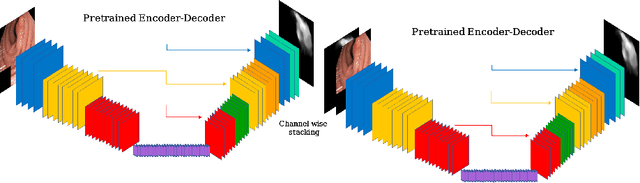
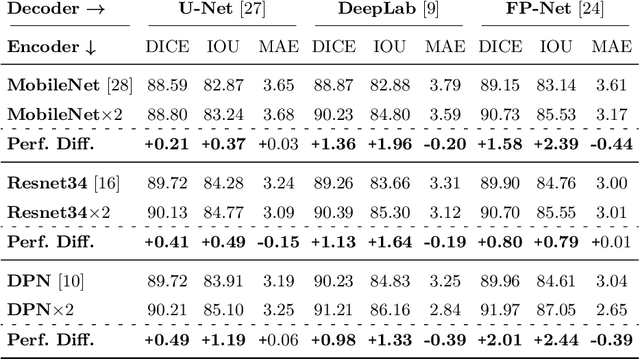
Polyps represent an early sign of the development of Colorectal Cancer. The standard procedure for their detection consists of colonoscopic examination of the gastrointestinal tract. However, the wide range of polyp shapes and visual appearances, as well as the reduced quality of this image modality, turn their automatic identification and segmentation with computational tools into a challenging computer vision task. In this work, we present a new strategy for the delineation of gastrointestinal polyps from endoscopic images based on a direct extension of common encoder-decoder networks for semantic segmentation. In our approach, two pretrained encoder-decoder networks are sequentially stacked: the second network takes as input the concatenation of the original frame and the initial prediction generated by the first network, which acts as an attention mechanism enabling the second network to focus on interesting areas within the image, thereby improving the quality of its predictions. Quantitative evaluation carried out on several polyp segmentation databases shows that double encoder-decoder networks clearly outperform their single encoder-decoder counterparts in all cases. In addition, our best double encoder-decoder combination attains excellent segmentation accuracy and reaches state-of-the-art performance results in all the considered datasets, with a remarkable boost of accuracy on images extracted from datasets not used for training.
Balanced-MixUp for Highly Imbalanced Medical Image Classification
Sep 20, 2021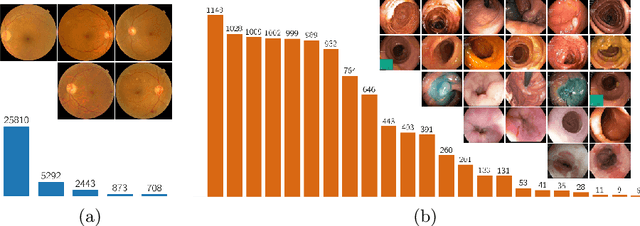
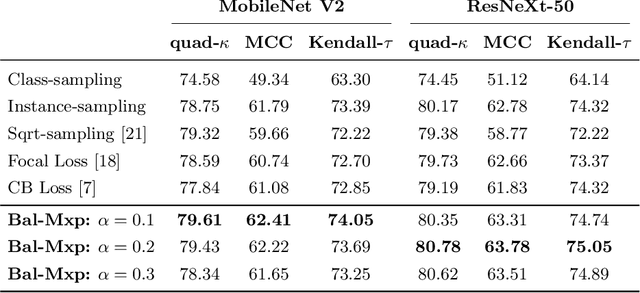

Highly imbalanced datasets are ubiquitous in medical image classification problems. In such problems, it is often the case that rare classes associated to less prevalent diseases are severely under-represented in labeled databases, typically resulting in poor performance of machine learning algorithms due to overfitting in the learning process. In this paper, we propose a novel mechanism for sampling training data based on the popular MixUp regularization technique, which we refer to as Balanced-MixUp. In short, Balanced-MixUp simultaneously performs regular (i.e., instance-based) and balanced (i.e., class-based) sampling of the training data. The resulting two sets of samples are then mixed-up to create a more balanced training distribution from which a neural network can effectively learn without incurring in heavily under-fitting the minority classes. We experiment with a highly imbalanced dataset of retinal images (55K samples, 5 classes) and a long-tail dataset of gastro-intestinal video frames (10K images, 23 classes), using two CNNs of varying representation capabilities. Experimental results demonstrate that applying Balanced-MixUp outperforms other conventional sampling schemes and loss functions specifically designed to deal with imbalanced data. Code is released at https://github.com/agaldran/balanced_mixup .
Multi-centred Strong Augmentation via Contrastive Learning for Unsupervised Lesion Detection and Segmentation
Sep 03, 2021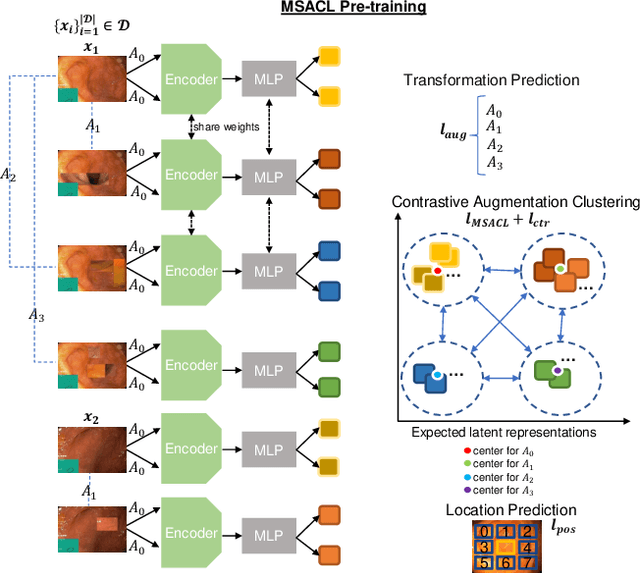
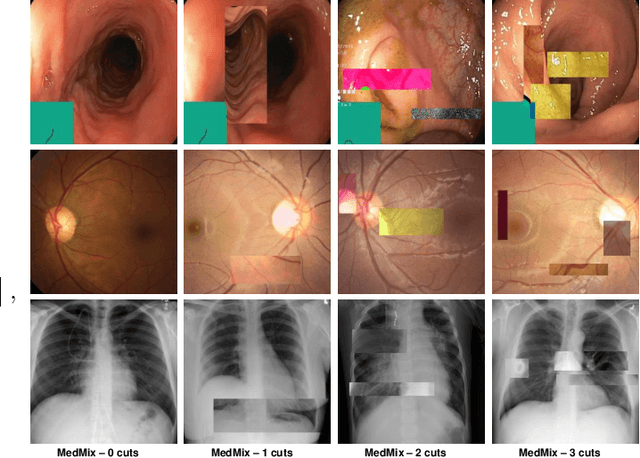
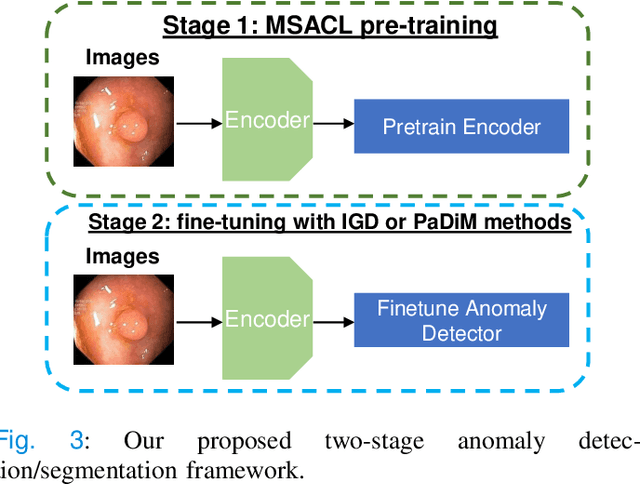
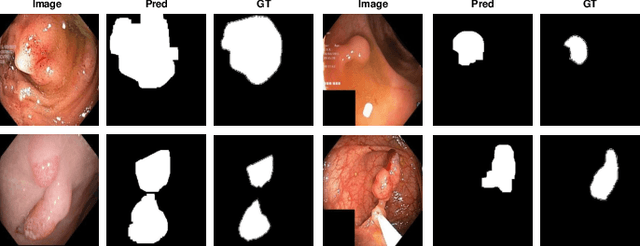
The scarcity of high quality medical image annotations hinders the implementation of accurate clinical applications for detecting and segmenting abnormal lesions. To mitigate this issue, the scientific community is working on the development of unsupervised anomaly detection (UAD) systems that learn from a training set containing only normal (i.e., healthy) images, where abnormal samples (i.e., unhealthy) are detected and segmented based on how much they deviate from the learned distribution of normal samples. One significant challenge faced by UAD methods is how to learn effective low-dimensional image representations that are sensitive enough to detect and segment abnormal lesions of varying size, appearance and shape. To address this challenge, we propose a novel self-supervised UAD pre-training algorithm, named Multi-centred Strong Augmentation via Contrastive Learning (MSACL). MSACL learns representations by separating several types of strong and weak augmentations of normal image samples, where the weak augmentations represent normal images and strong augmentations denote synthetic abnormal images. To produce such strong augmentations, we introduce MedMix, a novel data augmentation strategy that creates new training images with realistic looking lesions (i.e., anomalies) in normal images. The pre-trained representations from MSACL are generic and can be used to improve the efficacy of different types of off-the-shelf state-of-the-art (SOTA) UAD models. Comprehensive experimental results show that the use of MSACL largely improves these SOTA UAD models on four medical imaging datasets from diverse organs, namely colonoscopy, fundus screening and covid-19 chest-ray datasets.