 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependency-Aware Named Entity Recognition with Relative and Global Attentions
Sep 11, 2019
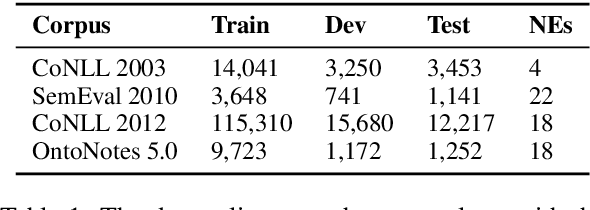
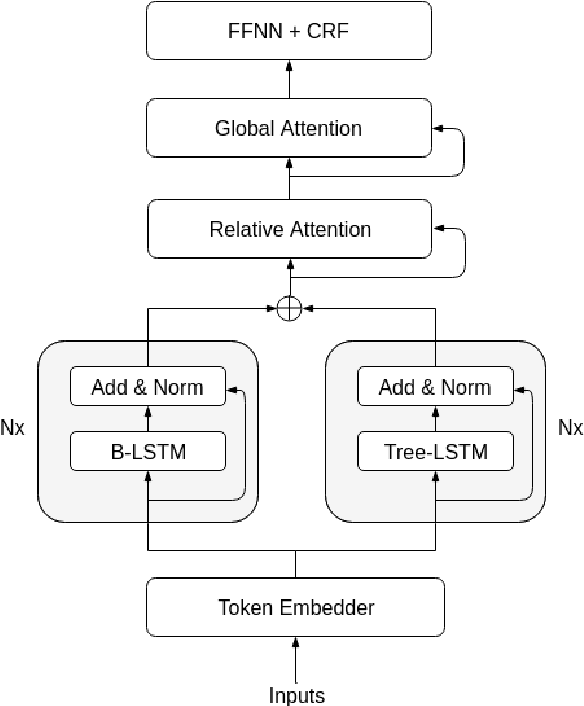
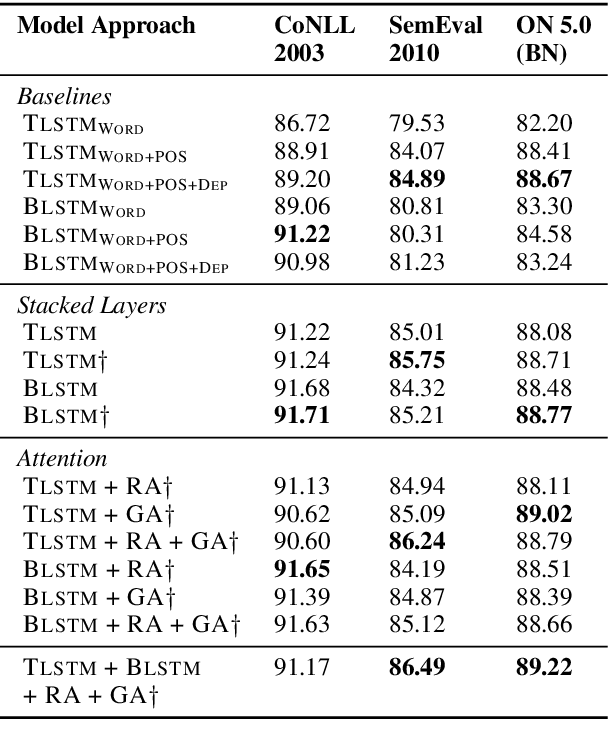
Named entity recognition is one of the core tasks in NLP. Although many improvements have been made on this task during the last years, the state-of-the-art systems do not explicitly take into account the recursive nature of language. Instead of only treating the text as a plain sequence of words, we incorporate a linguistically-inspired way to recognize entities based on syntax and tree structures. Our model exploits syntactic relationships among words using a Tree-LSTM guided by dependency trees. Then, we enhance these features by applying relative and global attention mechanisms. On the one hand, the relative attention detects the most informative words in the sentence with respect to the word being evaluated. On the other hand, the global attention spots the most relevant words in the sequence. Lastly, we linearly project the weighted vectors into the tagging space so that a conditional random field classifier predicts the entity labels. Our findings show that the model detects words that disclose the entity types based on their syntactic roles in a sentence (e.g., verbs such as speak and write are attended when the entity type is PERSON, whereas meet and travel strongly relate to LOCATION). We confirm our findings and establish a new state of the art on two datasets.
Multi-view Characterization of Stories from Narratives and Reviews using Multi-label Ranking
Aug 24, 2019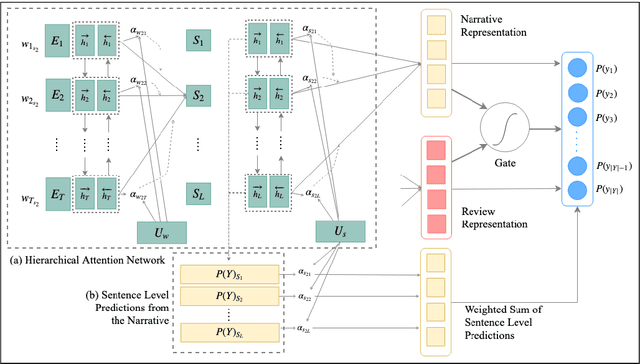
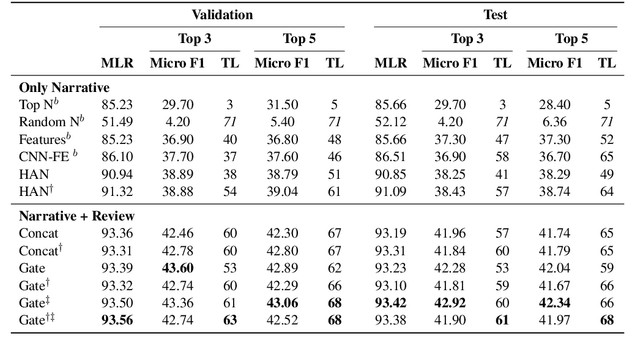
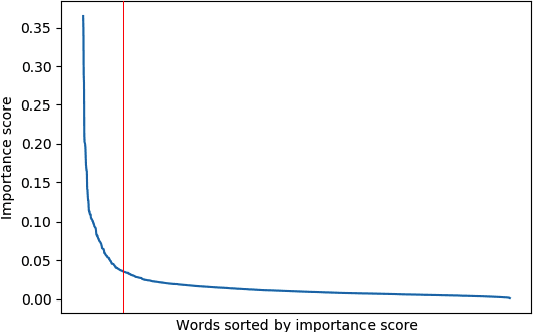
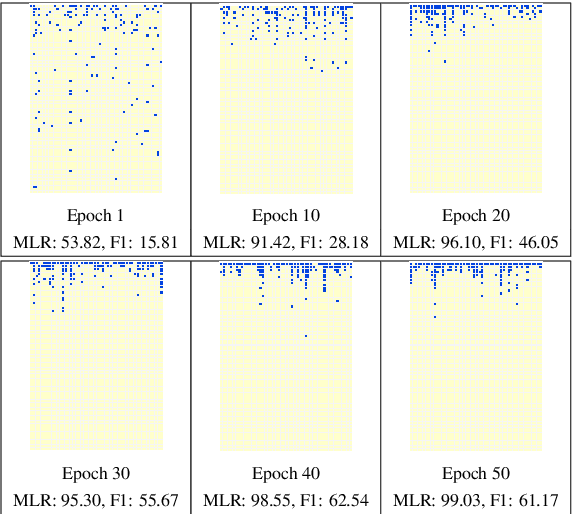
This paper considers the problem of characterizing stories by inferring attributes like theme and genre using the written narrative and user reviews. We experiment with a multi-label dataset of narratives representing the story of movies and a tagset representing various attributes of stories. To identify the story attributes, we propose a hierarchical representation of narratives that improves over the traditional feature-based machine learning methods as well as sequential representation approaches. Finally, we demonstrate a multi-view method for discovering story attributes from user opinions in reviews that are complementary to the gold standard data set.
Multimodal and Multi-view Models for Emotion Recognition
Jun 24, 2019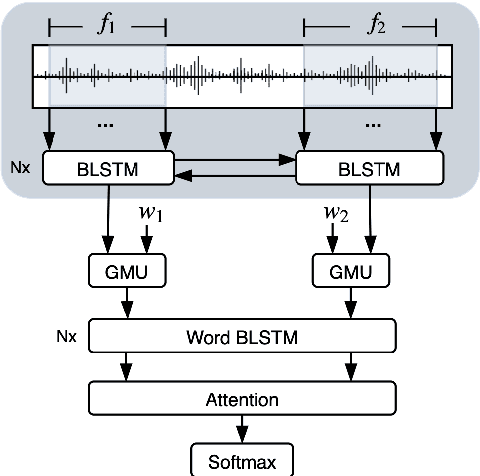
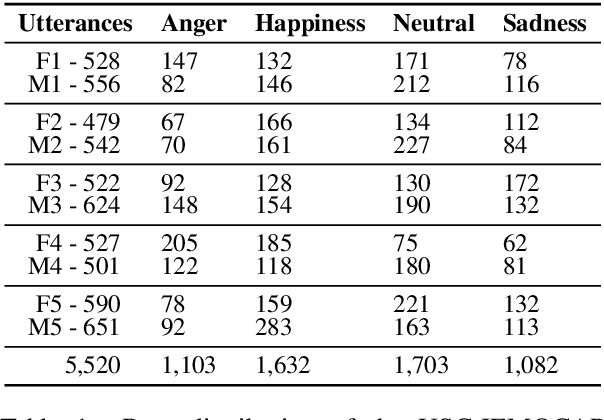
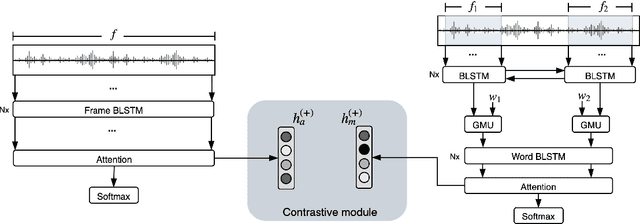
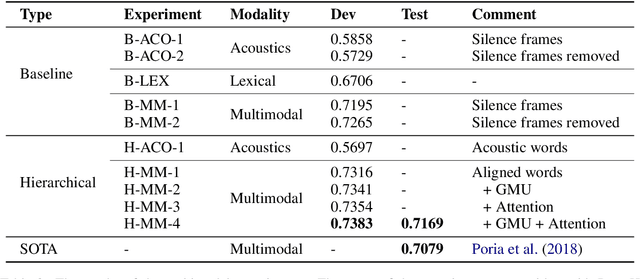
Studies on emotion recognition (ER) show that combining lexical and acoustic information results in more robust and accurate models. The majority of the studies focus on settings where both modalities are available in training and evaluation. However, in practice, this is not always the case; getting ASR output may represent a bottleneck in a deployment pipeline due to computational complexity or privacy-related constraints. To address this challenge, we study the problem of efficiently combining acoustic and lexical modalities during training while still providing a deployable acoustic model that does not require lexical inputs. We first experiment with multimodal models and two attention mechanisms to assess the extent of the benefits that lexical information can provide. Then, we frame the task as a multi-view learning problem to induce semantic information from a multimodal model into our acoustic-only network using a contrastive loss function. Our multimodal model outperforms the previous state of the art on the USC-IEMOCAP dataset reported on lexical and acoustic information. Additionally, our multi-view-trained acoustic network significantly surpasses models that have been exclusively trained with acoustic features.
Named Entity Recognition on Code-Switched Data: Overview of the CALCS 2018 Shared Task
Jun 10, 2019
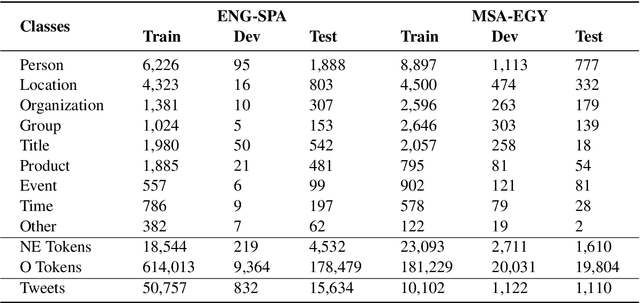
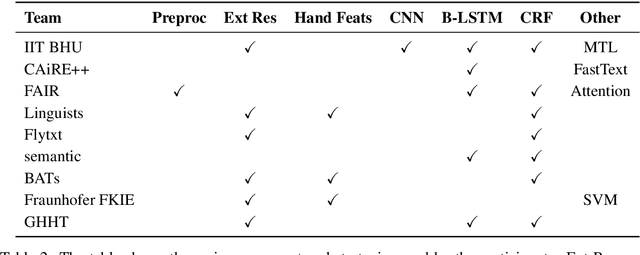
In the third shared task of the Computational Approaches to Linguistic Code-Switching (CALCS) workshop, we focus on Named Entity Recognition (NER) on code-switched social-media data. We divide the shared task into two competitions based on the English-Spanish (ENG-SPA) and Modern Standard Arabic-Egyptian (MSA-EGY) language pairs. We use Twitter data and 9 entity types to establish a new dataset for code-switched NER benchmarks. In addition to the CS phenomenon, the diversity of the entities and the social media challenges make the task considerably hard to process. As a result, the best scores of the competitions are 63.76% and 71.61% for ENG-SPA and MSA-EGY, respectively. We present the scores of 9 participants and discuss the most common challenges among submissions.
* ACL 2018 (CALCS)
A Multi-task Approach for Named Entity Recognition in Social Media Data
Jun 10, 2019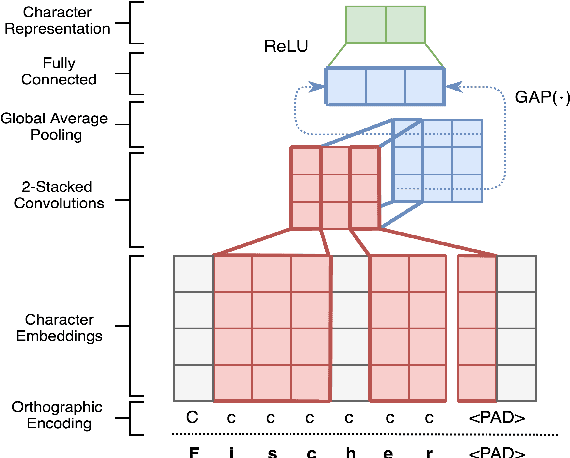
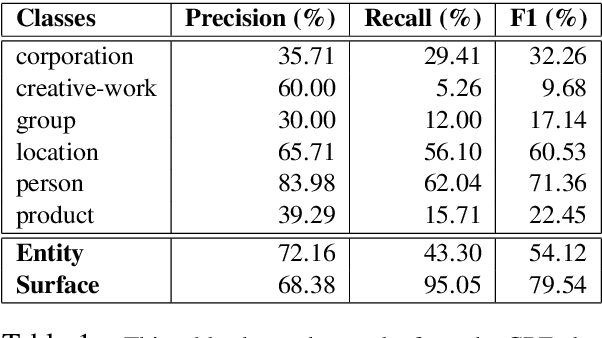
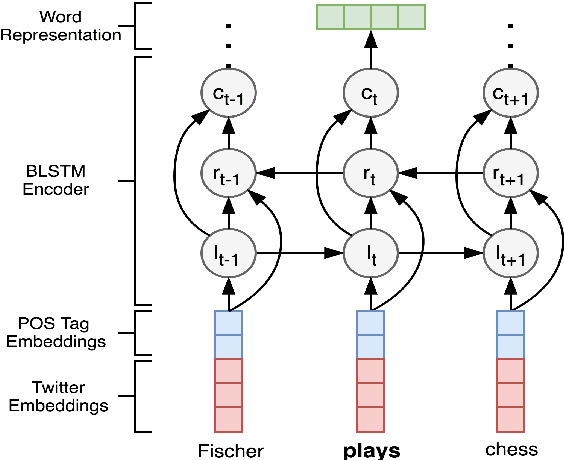
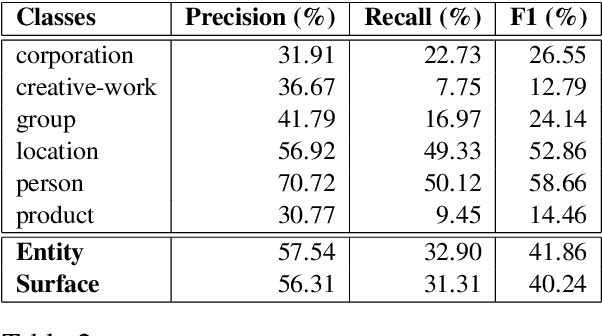
Named Entity Recognition for social media data is challenging because of its inherent noisiness. In addition to improper grammatical structures, it contains spelling inconsistencies and numerous informal abbreviations. We propose a novel multi-task approach by employing a more general secondary task of Named Entity (NE) segmentation together with the primary task of fine-grained NE categorization. The multi-task neural network architecture learns higher order feature representations from word and character sequences along with basic Part-of-Speech tags and gazetteer information. This neural network acts as a feature extractor to feed a Conditional Random Fields classifier. We were able to obtain the first position in the 3rd Workshop on Noisy User-generated Text (WNUT-2017) with a 41.86% entity F1-score and a 40.24% surface F1-score.
* EMNLP 2017 (W-NUT)
Modeling Noisiness to Recognize Named Entities using Multitask Neural Networks on Social Media
Jun 10, 2019


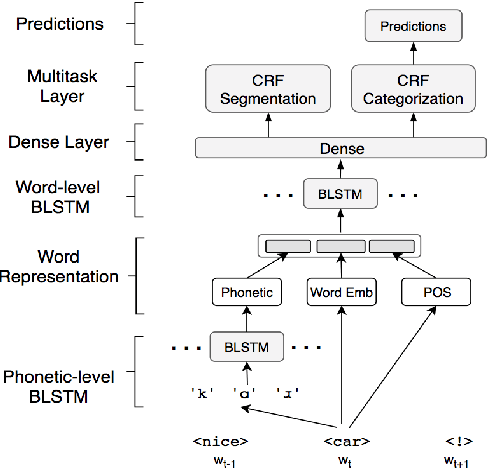
Recognizing named entities in a document is a key task in many NLP applications. Although current state-of-the-art approaches to this task reach a high performance on clean text (e.g. newswire genres), those algorithms dramatically degrade when they are moved to noisy environments such as social media domains. We present two systems that address the challenges of processing social media data using character-level phonetics and phonology, word embeddings, and Part-of-Speech tags as features. The first model is a multitask end-to-end Bidirectional Long Short-Term Memory (BLSTM)-Conditional Random Field (CRF) network whose output layer contains two CRF classifiers. The second model uses a multitask BLSTM network as feature extractor that transfers the learning to a CRF classifier for the final prediction. Our systems outperform the current F1 scores of the state of the art on the Workshop on Noisy User-generated Text 2017 dataset by 2.45% and 3.69%, establishing a more suitable approach for social media environments.
* NAACL 2018