 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCO Verification: Division of Input Space into COnvex polytopes for neural network verification
May 17, 2021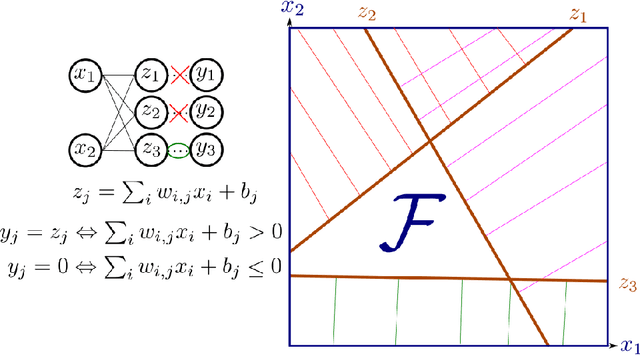

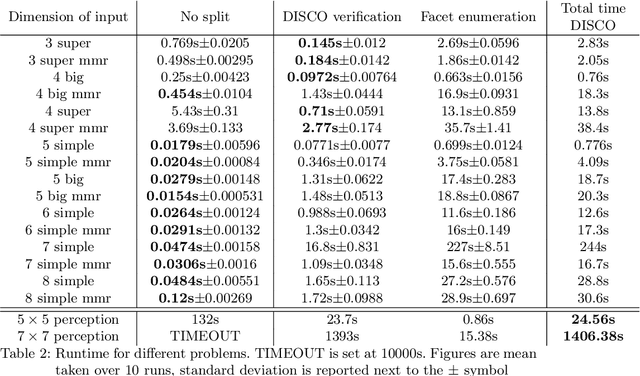
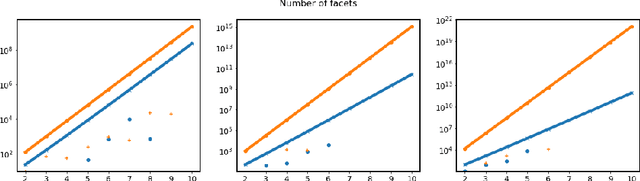
The impressive results of modern neural networks partly come from their non linear behaviour. Unfortunately, this property makes it very difficult to apply formal verification tools, even if we restrict ourselves to networks with a piecewise linear structure. However, such networks yields subregions that are linear and thus simpler to analyse independently. In this paper, we propose a method to simplify the verification problem by operating a partitionning into multiple linear subproblems. To evaluate the feasibility of such an approach, we perform an empirical analysis of neural networks to estimate the number of linear regions, and compare them to the bounds currently known. We also present the impact of a technique aiming at reducing the number of linear regions during training.
Input Similarity from the Neural Network Perspective
Feb 10, 2021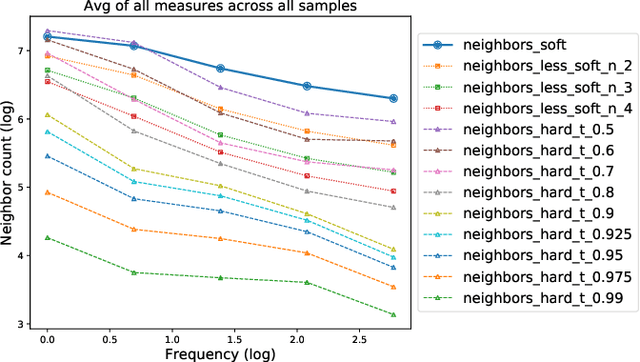
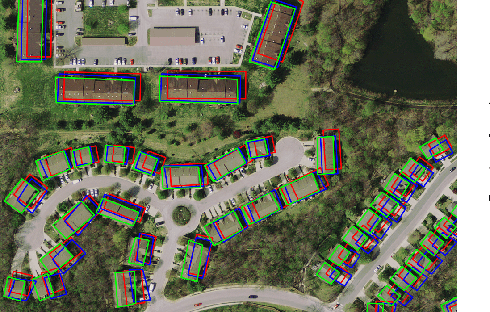
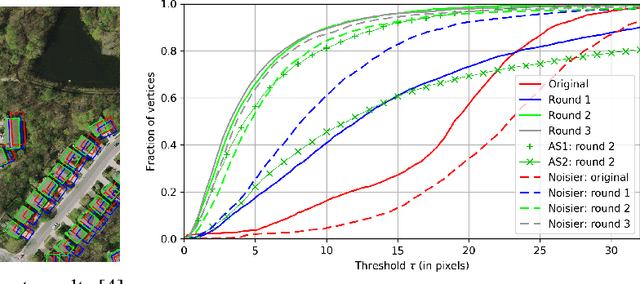

We first exhibit a multimodal image registration task, for which a neural network trained on a dataset with noisy labels reaches almost perfect accuracy, far beyond noise variance. This surprising auto-denoising phenomenon can be explained as a noise averaging effect over the labels of similar input examples. This effect theoretically grows with the number of similar examples; the question is then to define and estimate the similarity of examples. We express a proper definition of similarity, from the neural network perspective, i.e. we quantify how undissociable two inputs $A$ and $B$ are, taking a machine learning viewpoint: how much a parameter variation designed to change the output for $A$ would impact the output for $B$ as well? We study the mathematical properties of this similarity measure, and show how to use it on a trained network to estimate sample density, in low complexity, enabling new types of statistical analysis for neural networks. We analyze data by retrieving samples perceived as similar by the network, and are able to quantify the denoising effect without requiring true labels. We also propose, during training, to enforce that examples known to be similar should also be seen as similar by the network, and notice speed-up training effects for certain datasets.
Interpreting a Penalty as the Influence of a Bayesian Prior
Feb 01, 2020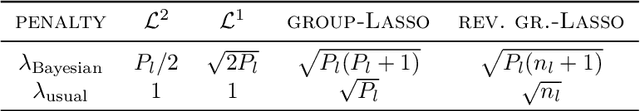
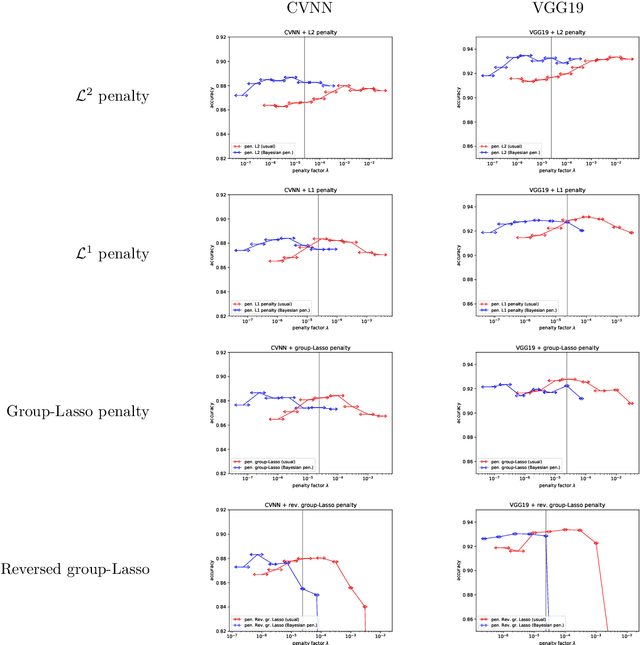

In machine learning, it is common to optimize the parameters of a probabilistic model, modulated by a somewhat ad hoc regularization term that penalizes some values of the parameters. Regularization terms appear naturally in Variational Inference (VI), a tractable way to approximate Bayesian posteriors: the loss to optimize contains a Kullback--Leibler divergence term between the approximate posterior and a Bayesian prior. We fully characterize which regularizers can arise this way, and provide a systematic way to compute the corresponding prior. This viewpoint also provides a prediction for useful values of the regularization factor in neural networks. We apply this framework to regularizers such as L1 or group-Lasso.
CAMUS: A Framework to Build Formal Specifications for Deep Perception Systems Using Simulators
Nov 25, 2019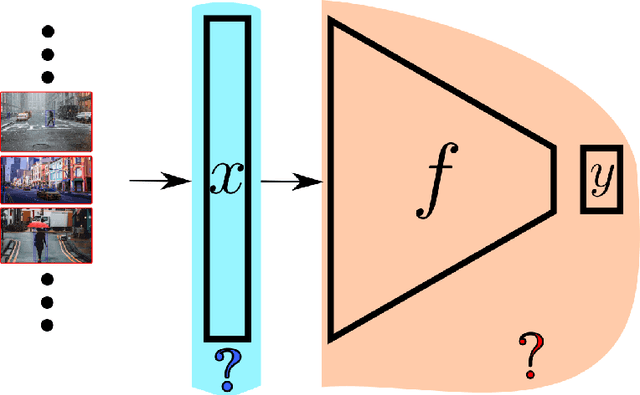
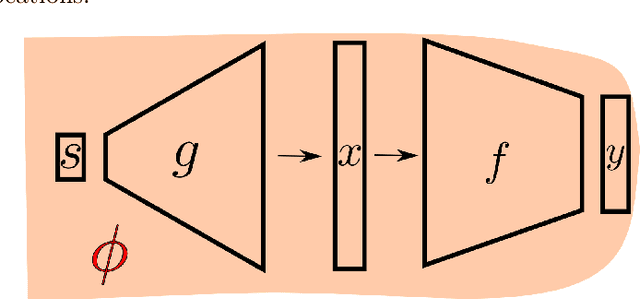
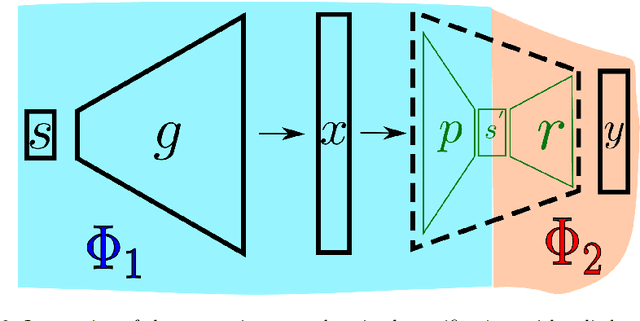

The topic of provable deep neural network robustness has raised considerable interest in recent years. Most research has focused on adversarial robustness, which studies the robustness of perceptive models in the neighbourhood of particular samples. However, other works have proved global properties of smaller neural networks. Yet, formally verifying perception remains uncharted. This is due notably to the lack of relevant properties to verify, as the distribution of possible inputs cannot be formally specified. We propose to take advantage of the simulators often used either to train machine learning models or to check them with statistical tests, a growing trend in industry. Our formulation allows us to formally express and verify safety properties on perception units, covering all cases that could ever be generated by the simulator, to the difference of statistical tests which cover only seen examples. Along with this theoretical formulation , we provide a tool to translate deep learning models into standard logical formulae. As a proof of concept, we train a toy example mimicking an autonomous car perceptive unit, and we formally verify that it will never fail to capture the relevant information in the provided inputs.
Tropical Cyclone Track Forecasting using Fused Deep Learning from Aligned Reanalysis Data
Oct 23, 2019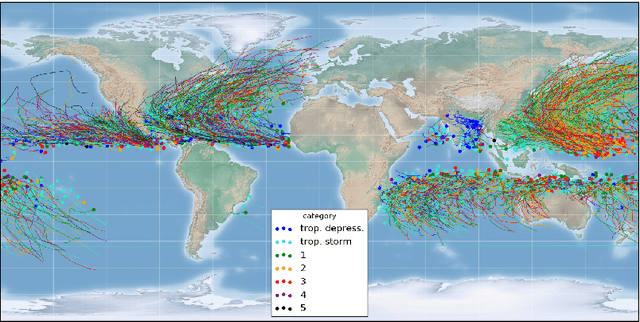
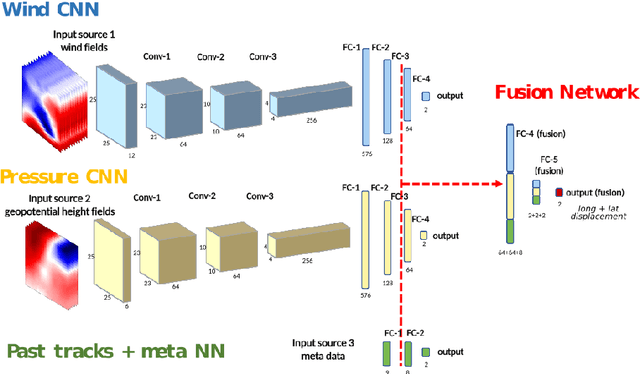

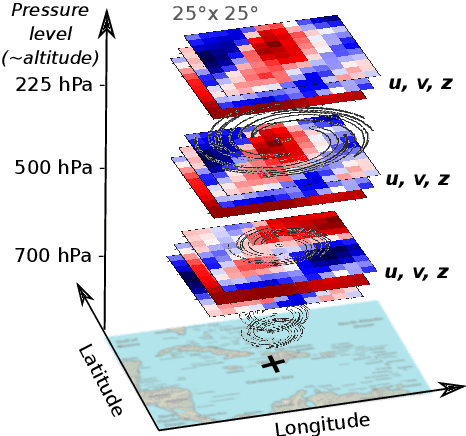
The forecast of tropical cyclone trajectories is crucial for the protection of people and property. Although forecast dynamical models can provide high-precision short-term forecasts, they are computationally demanding, and current statistical forecasting models have much room for improvement given that the database of past hurricanes is constantly growing. Machine learning methods, that can capture non-linearities and complex relations, have only been scarcely tested for this application. We propose a neural network model fusing past trajectory data and reanalysis atmospheric images (wind and pressure 3D fields). We use a moving frame of reference that follows the storm center for the 24h tracking forecast. The network is trained to estimate the longitude and latitude displacement of tropical cyclones and depressions from a large database from both hemispheres (more than 3000 storms since 1979, sampled at a 6 hour frequency). The advantage of the fused network is demonstrated and a comparison with current forecast models shows that deep learning methods could provide a valuable and complementary prediction. Moreover, our method can give a forecast for a new storm in a few seconds, which is an important asset for real-time forecasts compared to traditional forecasts.
Noisy Supervision for Correcting Misaligned Cadaster Maps Without Perfect Ground Truth Data
Mar 12, 2019
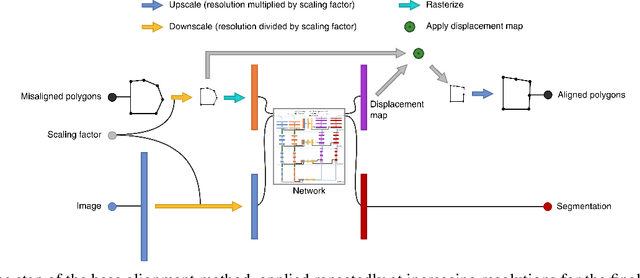
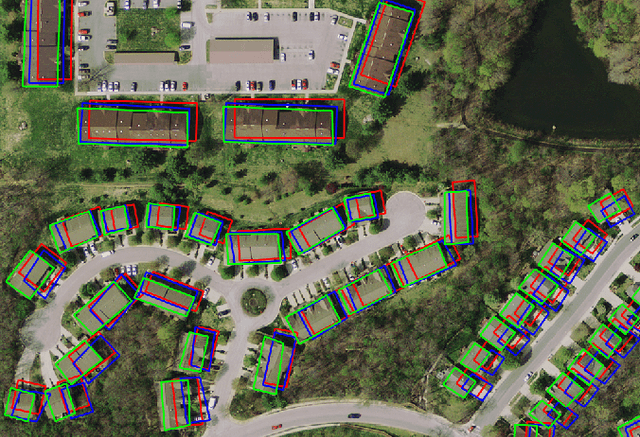
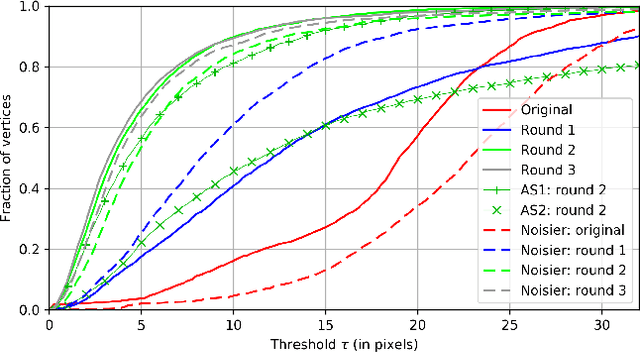
In machine learning the best performance on a certain task is achieved by fully supervised methods when perfect ground truth labels are available. However, labels are often noisy, especially in remote sensing where manually curated public datasets are rare. We study the multi-modal cadaster map alignment problem for which available annotations are mis-aligned polygons, resulting in noisy supervision. We subsequently set up a multiple-rounds training scheme which corrects the ground truth annotations at each round to better train the model at the next round. We show that it is possible to reduce the noise of the dataset by iteratively training a better alignment model to correct the annotation alignment.
Optimizing deep video representation to match brain activity
Sep 07, 2018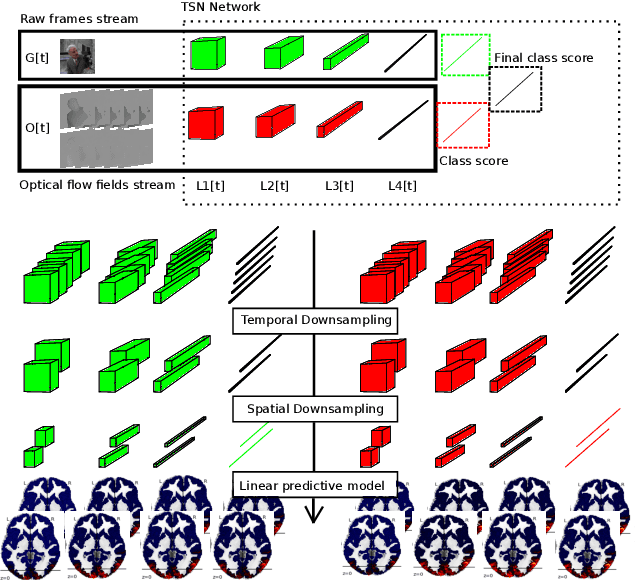
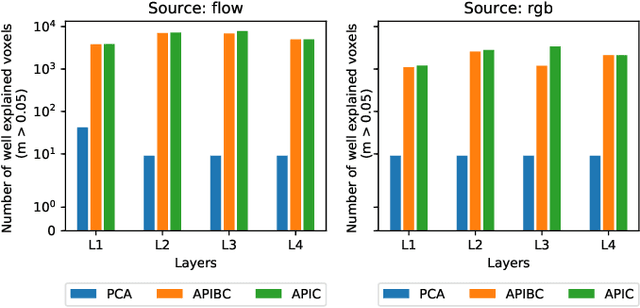
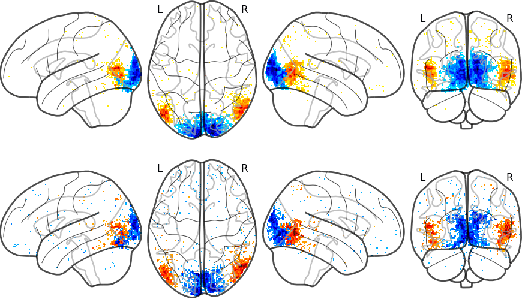
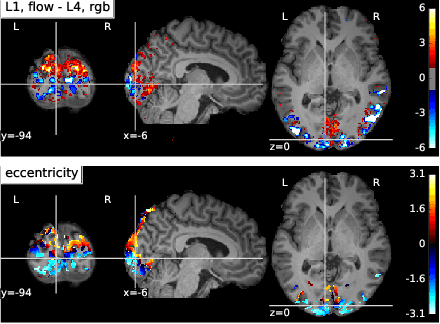
The comparison of observed brain activity with the statistics generated by artificial intelligence systems is useful to probe brain functional organization under ecological conditions. Here we study fMRI activity in ten subjects watching color natural movies and compute deep representations of these movies with an architecture that relies on optical flow and image content. The association of activity in visual areas with the different layers of the deep architecture displays complexity-related contrasts across visual areas and reveals a striking foveal/peripheral dichotomy.
Coarse to fine non-rigid registration: a chain of scale-specific neural networks for multimodal image alignment with application to remote sensing
Feb 27, 2018

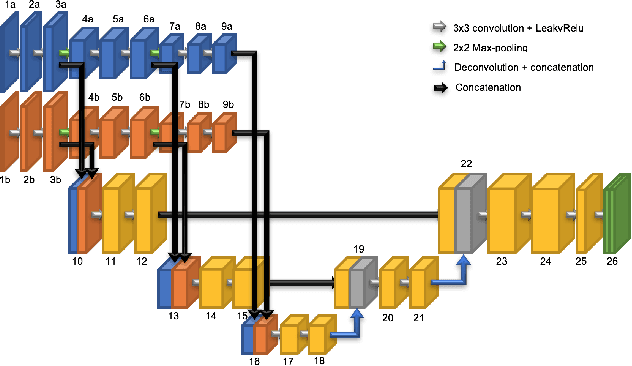
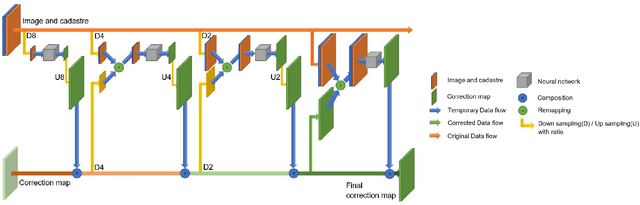
We tackle here the problem of multimodal image non-rigid registration, which is of prime importance in remote sensing and medical imaging. The difficulties encountered by classical registration approaches include feature design and slow optimization by gradient descent. By analyzing these methods, we note the significance of the notion of scale. We design easy-to-train, fully-convolutional neural networks able to learn scale-specific features. Once chained appropriately, they perform global registration in linear time, getting rid of gradient descent schemes by predicting directly the deformation.We show their performance in terms of quality and speed through various tasks of remote sensing multimodal image alignment. In particular, we are able to register correctly cadastral maps of buildings as well as road polylines onto RGB images, and outperform current keypoint matching methods.
Recurrent Neural Networks to Correct Satellite Image Classification Maps
Apr 21, 2017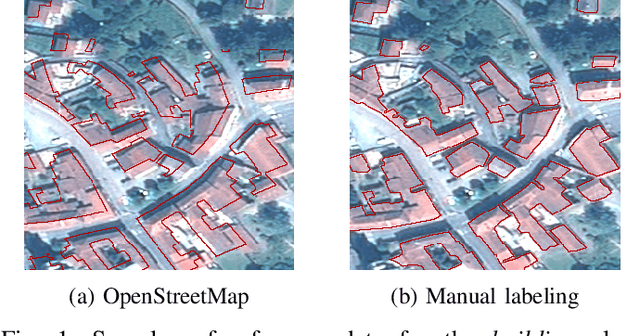

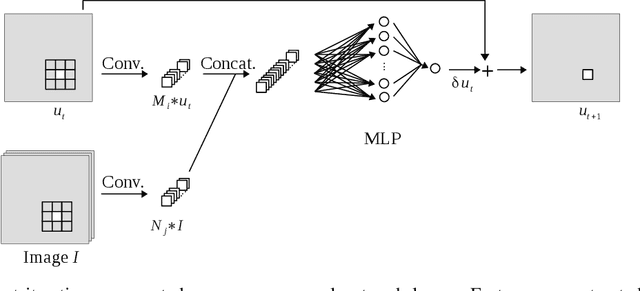

While initially devised for image categorization, convolutional neural networks (CNNs) are being increasingly used for the pixelwise semantic labeling of images. However, the proper nature of the most common CNN architectures makes them good at recognizing but poor at localizing objects precisely. This problem is magnified in the context of aerial and satellite image labeling, where a spatially fine object outlining is of paramount importance. Different iterative enhancement algorithms have been presented in the literature to progressively improve the coarse CNN outputs, seeking to sharpen object boundaries around real image edges. However, one must carefully design, choose and tune such algorithms. Instead, our goal is to directly learn the iterative process itself. For this, we formulate a generic iterative enhancement process inspired from partial differential equations, and observe that it can be expressed as a recurrent neural network (RNN). Consequently, we train such a network from manually labeled data for our enhancement task. In a series of experiments we show that our RNN effectively learns an iterative process that significantly improves the quality of satellite image classification maps.
High-Resolution Semantic Labeling with Convolutional Neural Networks
Nov 07, 2016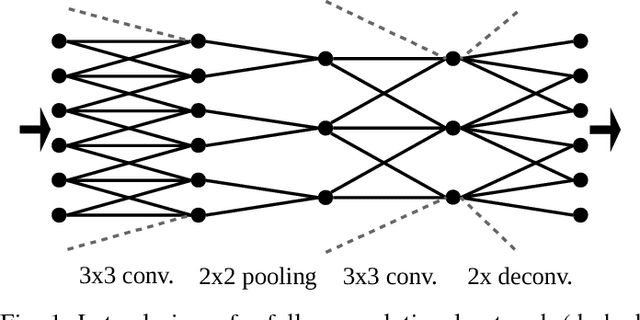

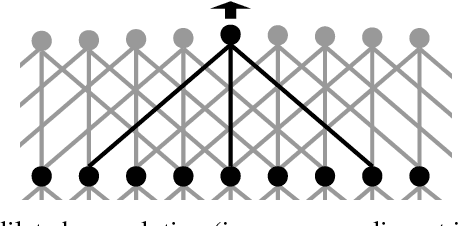
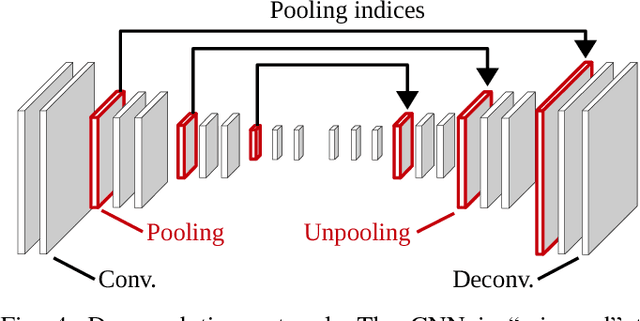
Convolutional neural networks (CNNs) have received increasing attention over the last few years. They were initially conceived for image categorization, i.e., the problem of assigning a semantic label to an entire input image. In this paper we address the problem of dense semantic labeling, which consists in assigning a semantic label to every pixel in an image. Since this requires a high spatial accuracy to determine where labels are assigned, categorization CNNs, intended to be highly robust to local deformations, are not directly applicable. By adapting categorization networks, many semantic labeling CNNs have been recently proposed. Our first contribution is an in-depth analysis of these architectures. We establish the desired properties of an ideal semantic labeling CNN, and assess how those methods stand with regard to these properties. We observe that even though they provide competitive results, these CNNs often underexploit properties of semantic labeling that could lead to more effective and efficient architectures. Out of these observations, we then derive a CNN framework specifically adapted to the semantic labeling problem. In addition to learning features at different resolutions, it learns how to combine these features. By integrating local and global information in an efficient and flexible manner, it outperforms previous techniques. We evaluate the proposed framework and compare it with state-of-the-art architectures on public benchmarks of high-resolution aerial image labeling.