 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Diversity-Enhanced Knowledge Distillation Model for Practical Math Word Problem Solving
Jan 07, 2025Math Word Problem (MWP) solving is a critical task in natural language processing, has garnered significant research interest in recent years. Various recent studies heavily rely on Seq2Seq models and their extensions (e.g., Seq2Tree and Graph2Tree) to generate mathematical equations. While effective, these models struggle to generate diverse but counterpart solution equations, limiting their generalization across various math problem scenarios. In this paper, we introduce a novel Diversity-enhanced Knowledge Distillation (DivKD) model for practical MWP solving. Our approach proposes an adaptive diversity distillation method, in which a student model learns diverse equations by selectively transferring high-quality knowledge from a teacher model. Additionally, we design a diversity prior-enhanced student model to better capture the diversity distribution of equations by incorporating a conditional variational auto-encoder. Extensive experiments on {four} MWP benchmark datasets demonstrate that our approach achieves higher answer accuracy than strong baselines while maintaining high efficiency for practical applications.
One Subgraph for All: Efficient Reasoning on Opening Subgraphs for Inductive Knowledge Graph Completion
Apr 24, 2024Knowledge Graph Completion (KGC) has garnered massive research interest recently, and most existing methods are designed following a transductive setting where all entities are observed during training. Despite the great progress on the transductive KGC, these methods struggle to conduct reasoning on emerging KGs involving unseen entities. Thus, inductive KGC, which aims to deduce missing links among unseen entities, has become a new trend. Many existing studies transform inductive KGC as a graph classification problem by extracting enclosing subgraphs surrounding each candidate triple. Unfortunately, they still face certain challenges, such as the expensive time consumption caused by the repeat extraction of enclosing subgraphs, and the deficiency of entity-independent feature learning. To address these issues, we propose a global-local anchor representation (GLAR) learning method for inductive KGC. Unlike previous methods that utilize enclosing subgraphs, we extract a shared opening subgraph for all candidates and perform reasoning on it, enabling the model to perform reasoning more efficiently. Moreover, we design some transferable global and local anchors to learn rich entity-independent features for emerging entities. Finally, a global-local graph reasoning model is applied on the opening subgraph to rank all candidates. Extensive experiments show that our GLAR outperforms most existing state-of-the-art methods.
Stack-VS: Stacked Visual-Semantic Attention for Image Caption Generation
Sep 05, 2019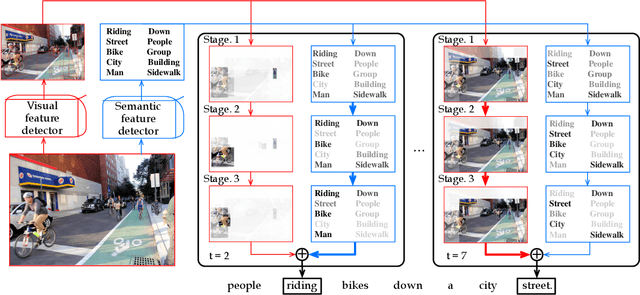
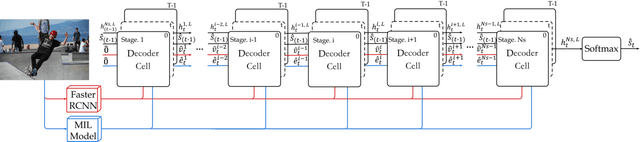
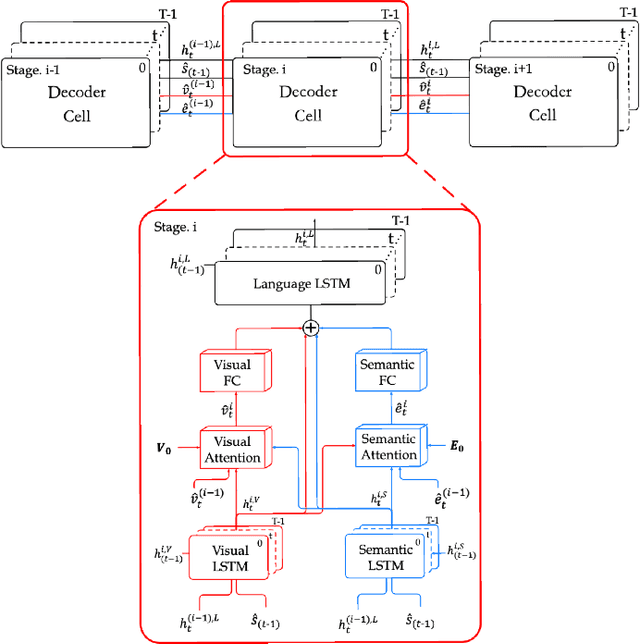
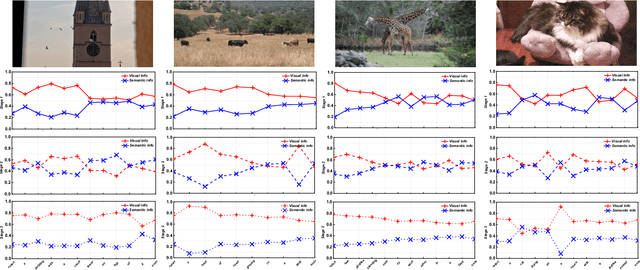
Recently, automatic image caption generation has been an important focus of the work on multimodal translation task. Existing approaches can be roughly categorized into two classes, i.e., top-down and bottom-up, the former transfers the image information (called as visual-level feature) directly into a caption, and the later uses the extracted words (called as semanticlevel attribute) to generate a description. However, previous methods either are typically based one-stage decoder or partially utilize part of visual-level or semantic-level information for image caption generation. In this paper, we address the problem and propose an innovative multi-stage architecture (called as Stack-VS) for rich fine-gained image caption generation, via combining bottom-up and top-down attention models to effectively handle both visual-level and semantic-level information of an input image. Specifically, we also propose a novel well-designed stack decoder model, which is constituted by a sequence of decoder cells, each of which contains two LSTM-layers work interactively to re-optimize attention weights on both visual-level feature vectors and semantic-level attribute embeddings for generating a fine-gained image caption. Extensive experiments on the popular benchmark dataset MSCOCO show the significant improvements on different evaluation metrics, i.e., the improvements on BLEU-4/CIDEr/SPICE scores are 0.372, 1.226 and 0.216, respectively, as compared to the state-of-the-arts.
Enhancing Neural Sequence Labeling with Position-Aware Self-Attention
Aug 24, 2019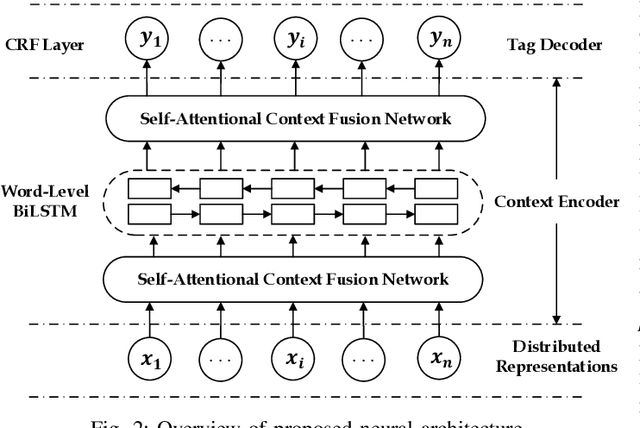
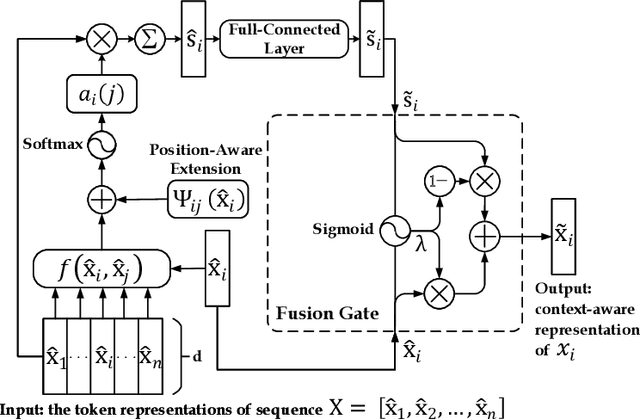
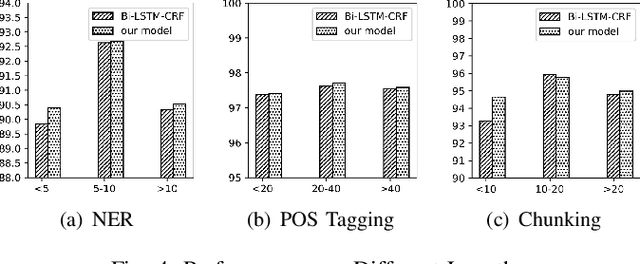
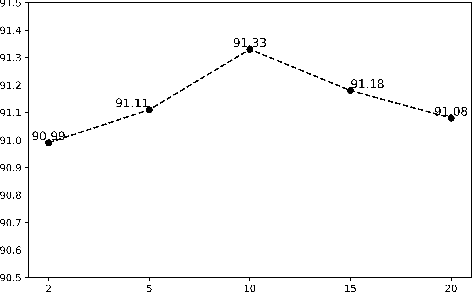
Sequence labeling is a fundamental task in natural language processing and has been widely studied. Recently, RNN-based sequence labeling models have increasingly gained attentions. Despite superior performance achieved by learning the long short-term (i.e., successive) dependencies, the way of sequentially processing inputs might limit the ability to capture the non-continuous relations over tokens within a sentence. To tackle the problem, we focus on how to effectively model successive and discrete dependencies of each token for enhancing the sequence labeling performance. Specifically, we propose an innovative and well-designed attention-based model (called position-aware self-attention, i.e., PSA) within a neural network architecture, to explore the positional information of an input sequence for capturing the latent relations among tokens. Extensive experiments on three classical tasks in sequence labeling domain, i.e., part-of-speech (POS) tagging, named entity recognition (NER) and phrase chunking, demonstrate our proposed model outperforms the state-of-the-arts without any external knowledge, in terms of various metrics.