 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpisodic Memory Deep Q-Networks
May 19, 2018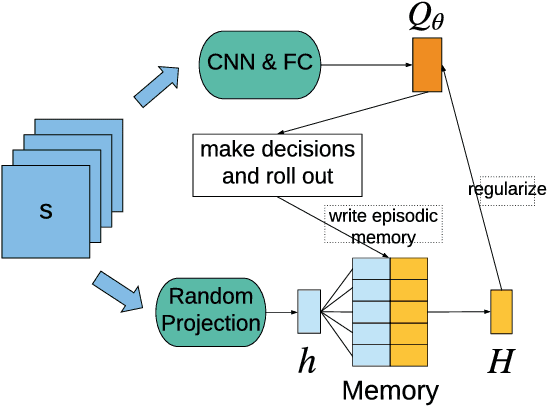
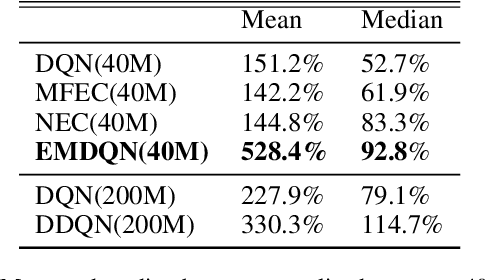
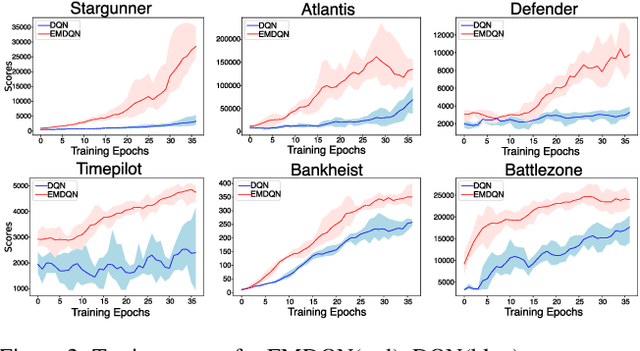
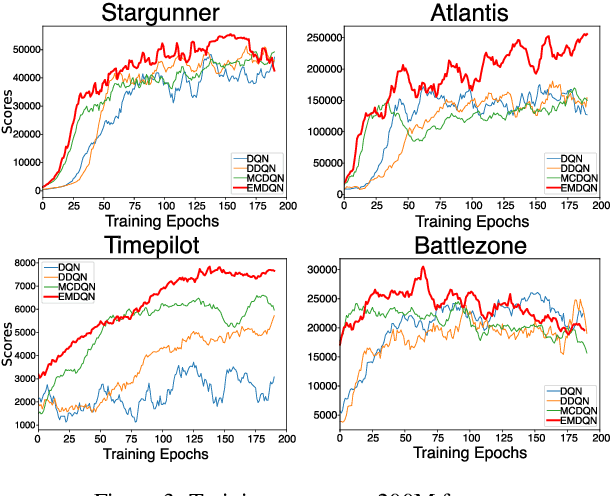
Reinforcement learning (RL) algorithms have made huge progress in recent years by leveraging the power of deep neural networks (DNN). Despite the success, deep RL algorithms are known to be sample inefficient, often requiring many rounds of interaction with the environments to obtain satisfactory performance. Recently, episodic memory based RL has attracted attention due to its ability to latch on good actions quickly. In this paper, we present a simple yet effective biologically inspired RL algorithm called Episodic Memory Deep Q-Networks (EMDQN), which leverages episodic memory to supervise an agent during training. Experiments show that our proposed method can lead to better sample efficiency and is more likely to find good policies. It only requires 1/5 of the interactions of DQN to achieve many state-of-the-art performances on Atari games, significantly outperforming regular DQN and other episodic memory based RL algorithms.
Cavs: A Vertex-centric Programming Interface for Dynamic Neural Networks
Dec 11, 2017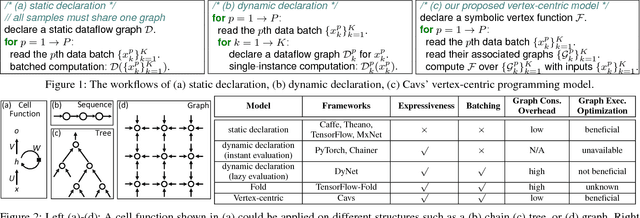
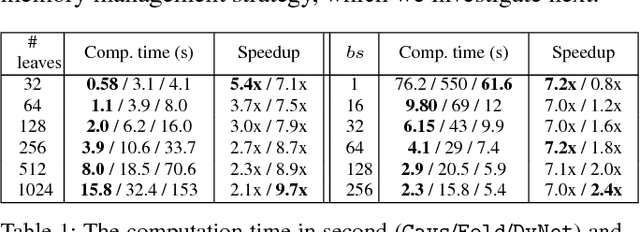
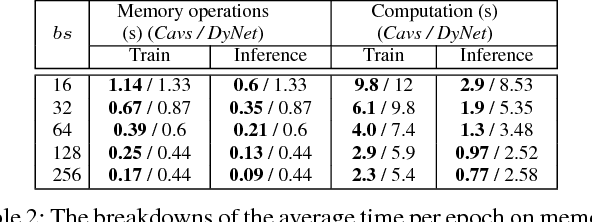
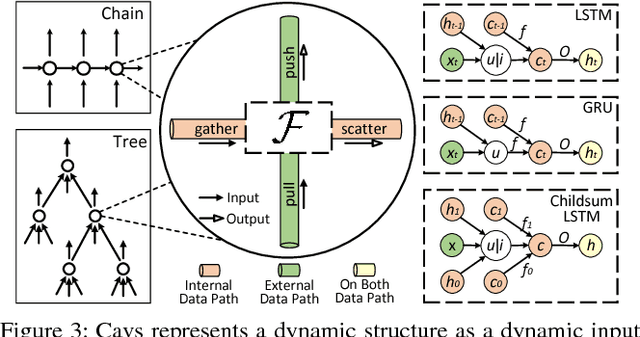
Recent deep learning (DL) models have moved beyond static network architectures to dynamic ones, handling data where the network structure changes every example, such as sequences of variable lengths, trees, and graphs. Existing dataflow-based programming models for DL---both static and dynamic declaration---either cannot readily express these dynamic models, or are inefficient due to repeated dataflow graph construction and processing, and difficulties in batched execution. We present Cavs, a vertex-centric programming interface and optimized system implementation for dynamic DL models. Cavs represents dynamic network structure as a static vertex function $\mathcal{F}$ and a dynamic instance-specific graph $\mathcal{G}$, and performs backpropagation by scheduling the execution of $\mathcal{F}$ following the dependencies in $\mathcal{G}$. Cavs bypasses expensive graph construction and preprocessing overhead, allows for the use of static graph optimization techniques on pre-defined operations in $\mathcal{F}$, and naturally exposes batched execution opportunities over different graphs. Experiments comparing Cavs to two state-of-the-art frameworks for dynamic NNs (TensorFlow Fold and DyNet) demonstrate the efficacy of this approach: Cavs achieves a near one order of magnitude speedup on training of various dynamic NN architectures, and ablations demonstrate the contribution of our proposed batching and memory management strategies.