 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasar: Quantized Self-Speculative Acceleration for Rapid Inference via Memory-Efficient Verification
Mar 02, 2026Speculative Decoding (SD) has emerged as a premier technique for accelerating Large Language Model (LLM) inference by decoupling token generation into rapid drafting and parallel verification. While recent advancements in self-speculation and lookahead decoding have successfully minimized drafting overhead, they have shifted the primary performance bottleneck to the verification phase. Since verification requires a full forward pass of the target model, it remains strictly memory-bandwidth bound, fundamentally limiting the maximum achievable speedup.In this paper, we introduce \textbf{Quasar} (\textbf{Qua}ntized \textbf{S}elf-speculative \textbf{A}cceleration for \textbf{R}apid Inference), a novel, training-free framework designed to overcome this "memory wall" by employing low-bit quantization specifically for the verification stage. Our empirical analysis reveals that while aggressive structural pruning significantly degrades verification accuracy, quantization-based verification preserves the logit distribution with high fidelity while effectively halving memory traffic. Extensive experiments on state-of-the-art models (e.g., OpenPangu and Qwen3) demonstrate that Quasar maintains a speculative acceptance length comparable to full-precision methods while achieving a $1.28\times$ improvement in end-to-end throughput. Being orthogonal to existing drafting strategies, Quasar offers a generic and efficient pathway to accelerate the verification leg of speculative execution. Code is available at https://github.com/Tom-HG/Quasar.
S$^4$C: Speculative Sampling with Syntactic and Semantic Coherence for Efficient Inference of Large Language Models
Jun 17, 2025Large language models (LLMs) exhibit remarkable reasoning capabilities across diverse downstream tasks. However, their autoregressive nature leads to substantial inference latency, posing challenges for real-time applications. Speculative sampling mitigates this issue by introducing a drafting phase followed by a parallel validation phase, enabling faster token generation and verification. Existing approaches, however, overlook the inherent coherence in text generation, limiting their efficiency. To address this gap, we propose a Speculative Sampling with Syntactic and Semantic Coherence (S$^4$C) framework, which extends speculative sampling by leveraging multi-head drafting for rapid token generation and a continuous verification tree for efficient candidate validation and feature reuse. Experimental results demonstrate that S$^4$C surpasses baseline methods across mainstream tasks, offering enhanced efficiency, parallelism, and the ability to generate more valid tokens with fewer computational resources. On Spec-bench benchmarks, S$^4$C achieves an acceleration ratio of 2.26x-2.60x, outperforming state-of-the-art methods.
Successive Convex Approximation Based Off-Policy Optimization for Constrained Reinforcement Learning
May 26, 2021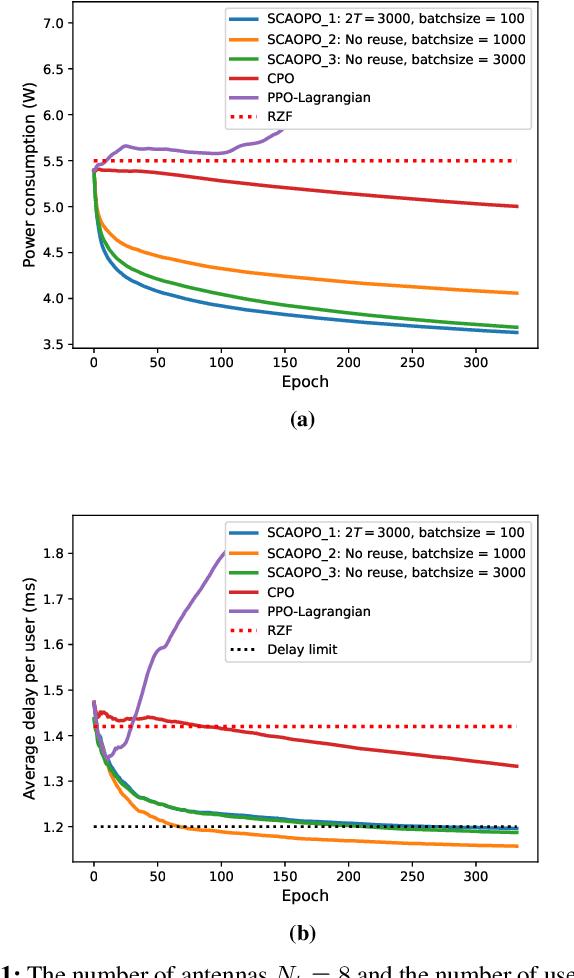
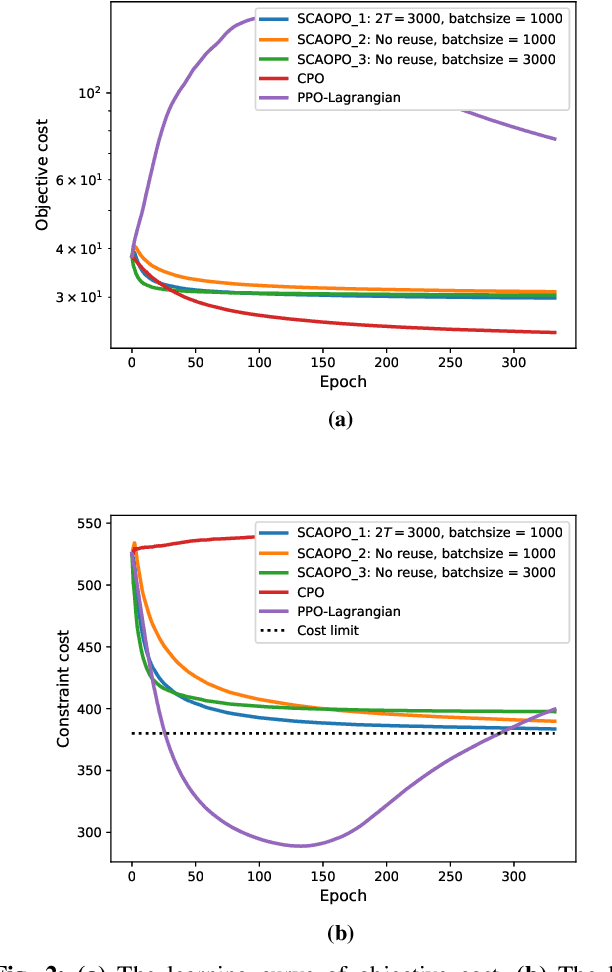
We propose a successive convex approximation based off-policy optimization (SCAOPO) algorithm to solve the general constrained reinforcement learning problem, which is formulated as a constrained Markov decision process (CMDP) in the context of average cost. The SCAOPO is based on solving a sequence of convex objective/feasibility optimization problems obtained by replacing the objective and constraint functions in the original problems with convex surrogate functions. At each iteration, the convex surrogate problem can be efficiently solved by Lagrange dual method even the policy is parameterized by a high-dimensional function. Moreover, the SCAOPO enables to reuse old experiences from previous updates, thereby significantly reducing the implementation cost when deployed in the real-world engineering systems that need to online learn the environment. In spite of the time-varying state distribution and the stochastic bias incurred by the off-policy learning, the SCAOPO with a feasible initial point can still provably converge to a Karush-Kuhn-Tucker (KKT) point of the original problem almost surely.