 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Deduction through Search over Statement Compositions
Jan 16, 2022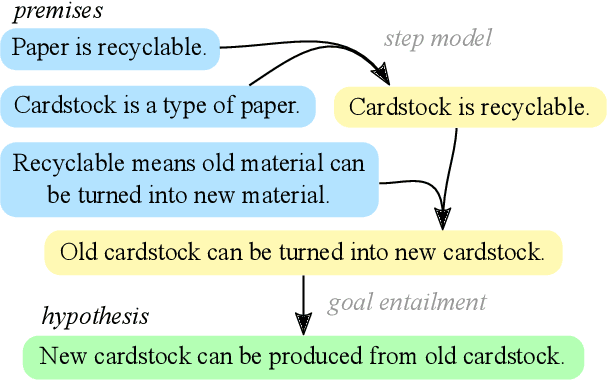

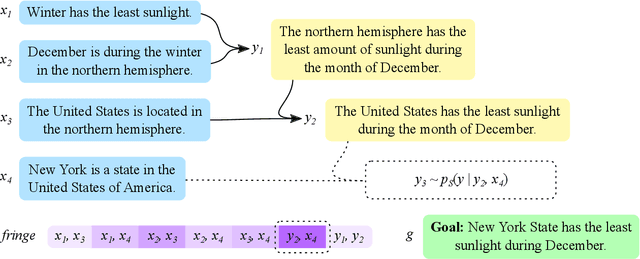
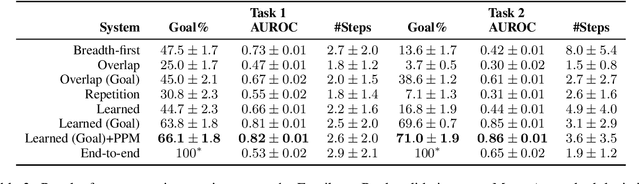
In settings from fact-checking to question answering, we frequently want to know whether a collection of evidence entails a hypothesis. Existing methods primarily focus on end-to-end discriminative versions of this task, but less work has treated the generative version in which a model searches over the space of entailed statements to derive the hypothesis. We propose a system for natural language deduction that decomposes the task into separate steps coordinated by best-first search, producing a tree of intermediate conclusions that faithfully reflects the system's reasoning process. Our experiments demonstrate that the proposed system can better distinguish verifiable hypotheses from unverifiable ones and produce natural language explanations that are more internally consistent than those produced by an end-to-end T5 model.
Massive-scale Decoding for Text Generation using Lattices
Dec 14, 2021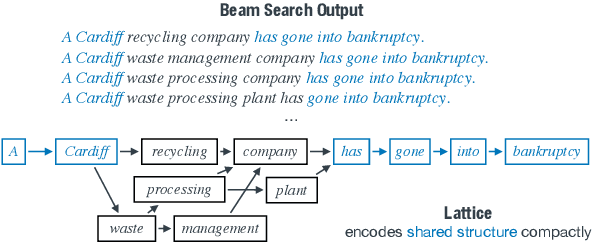
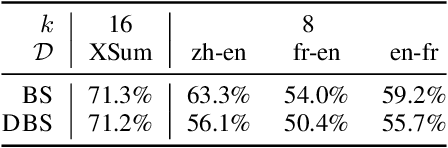
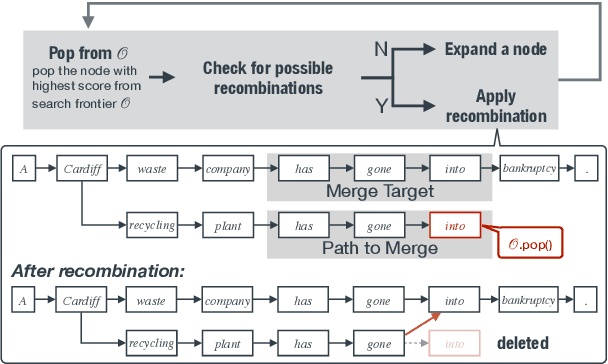
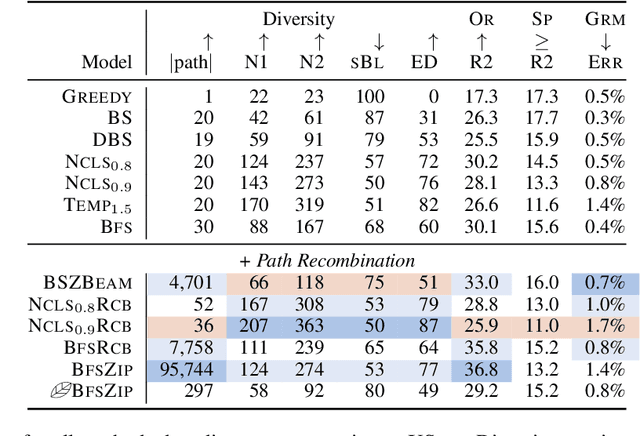
Neural text generation models like those used for summarization and translation generate high-quality outputs, but often concentrate around a mode when what we really want is a diverse set of options. We present a search algorithm to construct lattices encoding a massive number of generation options. First, we restructure decoding as a best-first search, which explores the space differently than beam search and improves efficiency by avoiding pruning paths. Second, we revisit the idea of hypothesis recombination: we can identify pairs of similar generation candidates during search and merge them as an approximation. On both document summarization and machine translation, we show that our algorithm encodes hundreds to thousands of diverse options that remain grammatical and high-quality into one linear-sized lattice. This algorithm provides a foundation for building downstream generation applications on top of massive-scale diverse outputs.
Discourse Comprehension: A Question Answering Framework to Represent Sentence Connections
Nov 01, 2021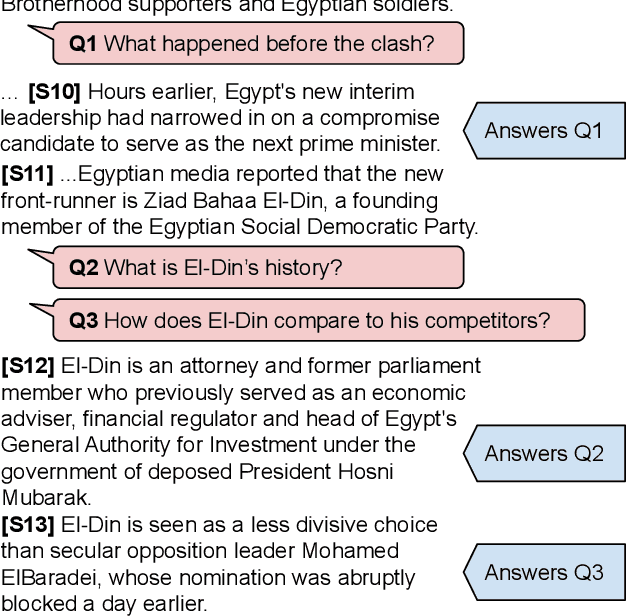


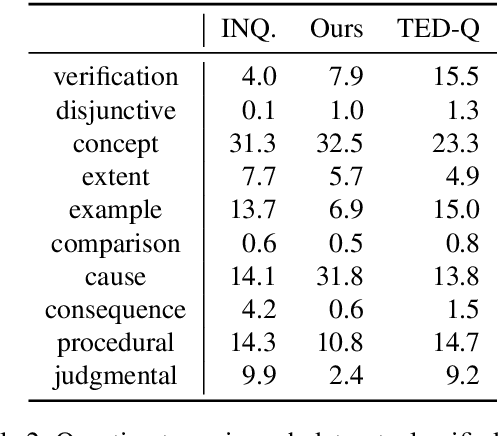
While there has been substantial progress in text comprehension through simple factoid question answering, more holistic comprehension of a discourse still presents a major challenge. Someone critically reflecting on a text as they read it will pose curiosity-driven, often open-ended questions, which reflect deep understanding of the content and require complex reasoning to answer. A key challenge in building and evaluating models for this type of discourse comprehension is the lack of annotated data, especially since finding answers to such questions (which may not be answered at all) requires high cognitive load for annotators over long documents. This paper presents a novel paradigm that enables scalable data collection targeting the comprehension of news documents, viewing these questions through the lens of discourse. The resulting corpus, DCQA (Discourse Comprehension by Question Answering), consists of 22,430 question-answer pairs across 607 English documents. DCQA captures both discourse and semantic links between sentences in the form of free-form, open-ended questions. On an evaluation set that we annotated on questions from the INQUISITIVE dataset, we show that DCQA provides valuable supervision for answering open-ended questions. We additionally design pre-training methods utilizing existing question-answering resources, and use synthetic data to accommodate unanswerable questions.
Training Dynamics for Text Summarization Models
Oct 15, 2021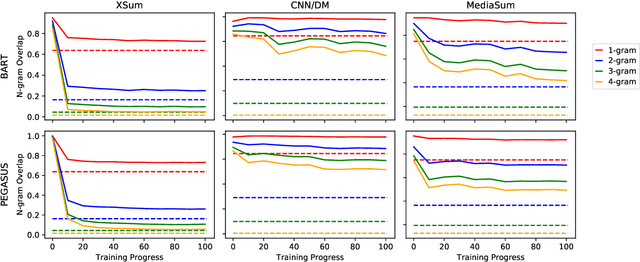
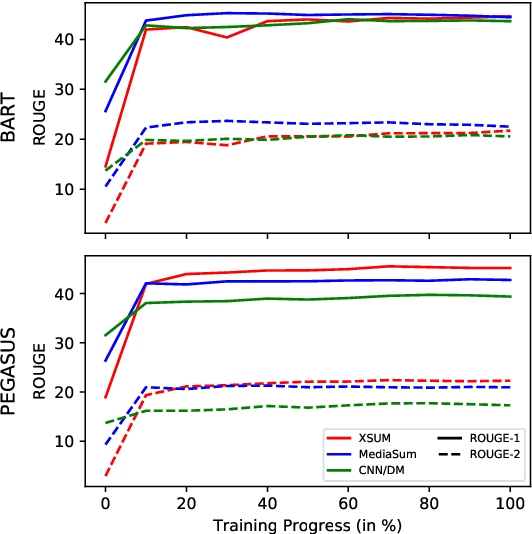
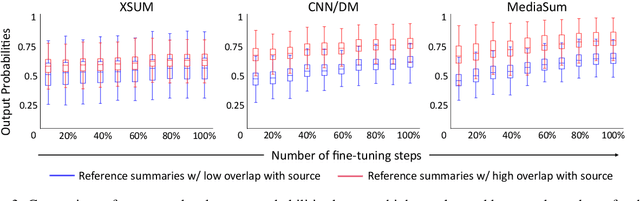
Pre-trained language models (e.g. BART) have shown impressive results when fine-tuned on large summarization datasets. However, little is understood about this fine-tuning process, including what knowledge is retained from pre-training models or how content selection and generation strategies are learnt across iterations. In this work, we analyze the training dynamics for generation models, focusing on news summarization. Across different datasets (CNN/DM, XSum, MediaSum) and summary properties, such as abstractiveness and hallucination, we study what the model learns at different stages of its fine-tuning process. We find that properties such as copy behavior are learnt earlier in the training process and these observations are robust across domains. On the other hand, factual errors, such as hallucination of unsupported facts, are learnt in the later stages, and this behavior is more varied across domains. Based on these observations, we explore complementary approaches for modifying training: first, disregarding high-loss tokens that are challenging to learn and second, disregarding low-loss tokens that are learnt very quickly. This simple training modification allows us to configure our model to achieve different goals, such as improving factuality or improving abstractiveness.
Aspect-Oriented Summarization through Query-Focused Extraction
Oct 15, 2021


A reader interested in a particular topic might be interested in summarizing documents on that subject with a particular focus, rather than simply seeing generic summaries produced by most summarization systems. While query-focused summarization has been explored in prior work, this is often approached from the standpoint of document-specific questions or on synthetic data. Real users' needs often fall more closely into aspects, broad topics in a dataset the user is interested in rather than specific queries. In this paper, we collect a dataset of realistic aspect-oriented test cases, AspectNews, which covers different subtopics about articles in news sub-domains. We then investigate how query-focused methods, for which we can construct synthetic data, can handle this aspect-oriented setting: we benchmark extractive query-focused training schemes, and propose a contrastive augmentation approach to train the model. We evaluate on two aspect-oriented datasets and find this approach yields (a) focused summaries, better than those from a generic summarization system, which go beyond simple keyword matching; (b) a system sensitive to the choice of keywords.
Cross-Lingual Fine-Grained Entity Typing
Oct 15, 2021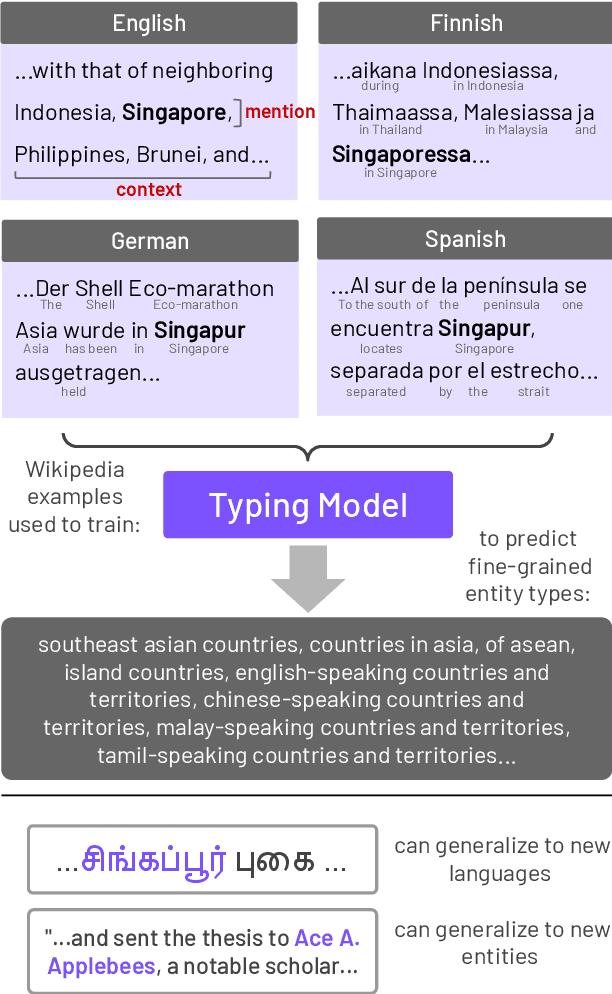
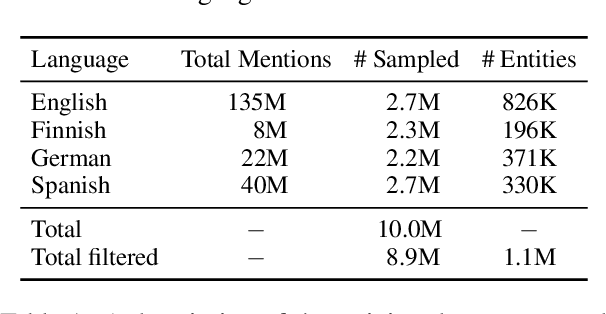
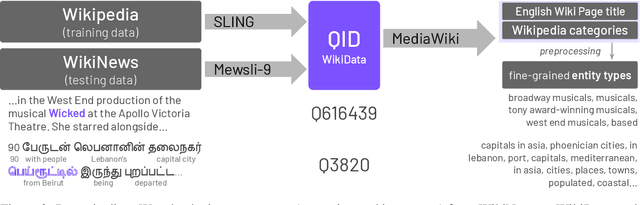
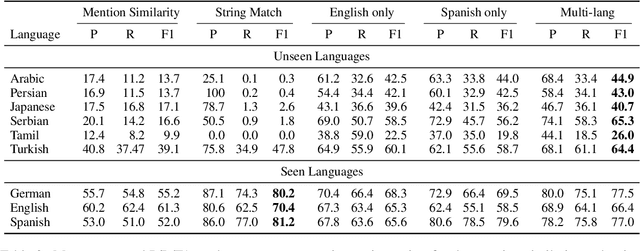
The growth of cross-lingual pre-trained models has enabled NLP tools to rapidly generalize to new languages. While these models have been applied to tasks involving entities, their ability to explicitly predict typological features of these entities across languages has not been established. In this paper, we present a unified cross-lingual fine-grained entity typing model capable of handling over 100 languages and analyze this model's ability to generalize to languages and entities unseen during training. We train this model on cross-lingual training data collected from Wikipedia hyperlinks in multiple languages (training languages). During inference, our model takes an entity mention and context in a particular language (test language, possibly not in the training languages) and predicts fine-grained types for that entity. Generalizing to new languages and unseen entities are the fundamental challenges of this entity typing setup, so we focus our evaluation on these settings and compare against simple yet powerful string match baselines. Experimental results show that our approach outperforms the baselines on unseen languages such as Japanese, Tamil, Arabic, Serbian, and Persian. In addition, our approach substantially improves performance on unseen entities (even in unseen languages) over the baselines, and human evaluation shows a strong ability to predict relevant types in these settings.
Making Document-Level Information Extraction Right for the Right Reasons
Oct 14, 2021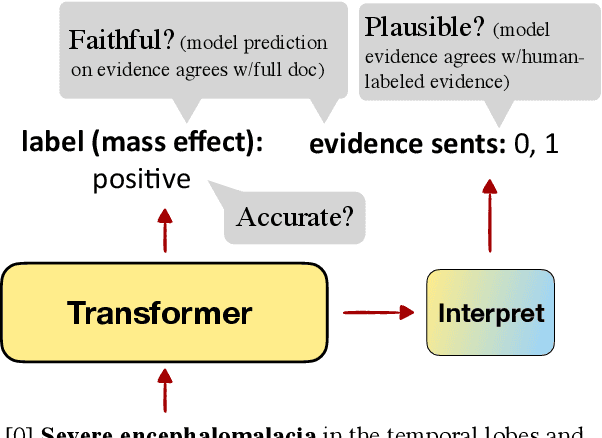

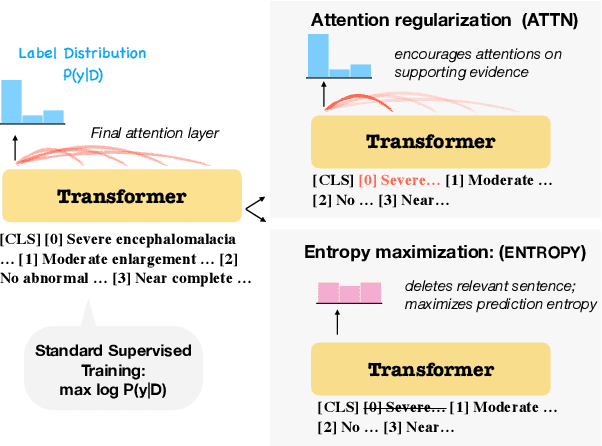
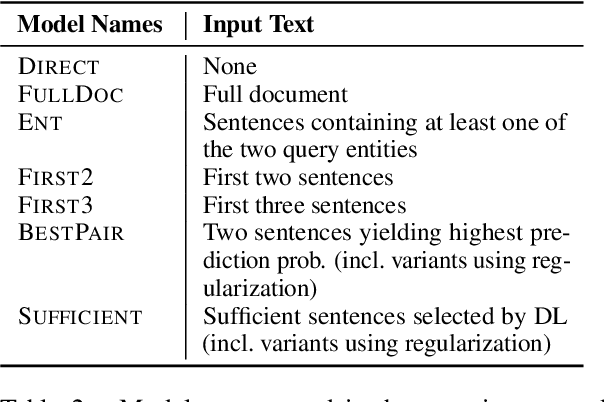
Document-level information extraction is a flexible framework compatible with applications where information is not necessarily localized in a single sentence. For example, key features of a diagnosis in radiology a report may not be explicitly stated, but nevertheless can be inferred from the report's text. However, document-level neural models can easily learn spurious correlations from irrelevant information. This work studies how to ensure that these models make correct inferences from complex text and make those inferences in an auditable way: beyond just being right, are these models "right for the right reasons?" We experiment with post-hoc evidence extraction in a predict-select-verify framework using feature attribution techniques. While this basic approach can extract reasonable evidence, it can be regularized with small amounts of evidence supervision during training, which substantially improves the quality of extracted evidence. We evaluate on two domains: a small-scale labeled dataset of brain MRI reports and a large-scale modified version of DocRED (Yao et al., 2019) and show that models' plausibility can be improved with no loss in accuracy.
Can Explanations Be Useful for Calibrating Black Box Models?
Oct 14, 2021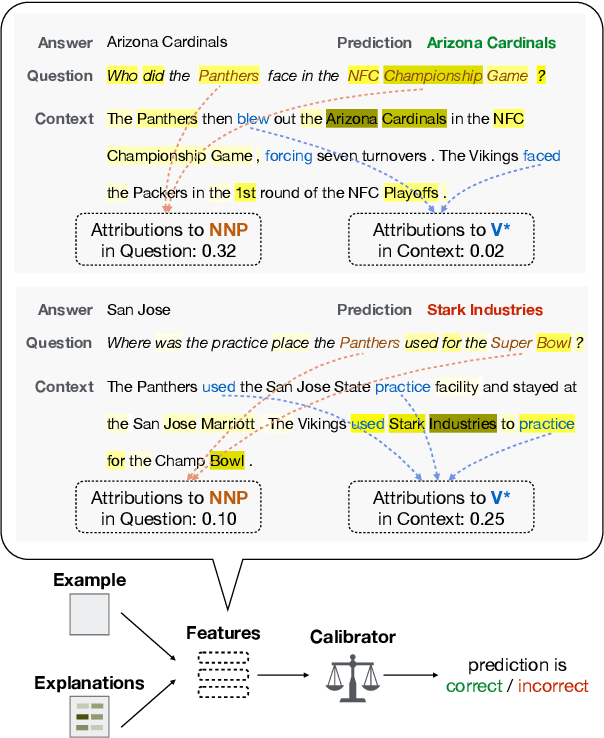
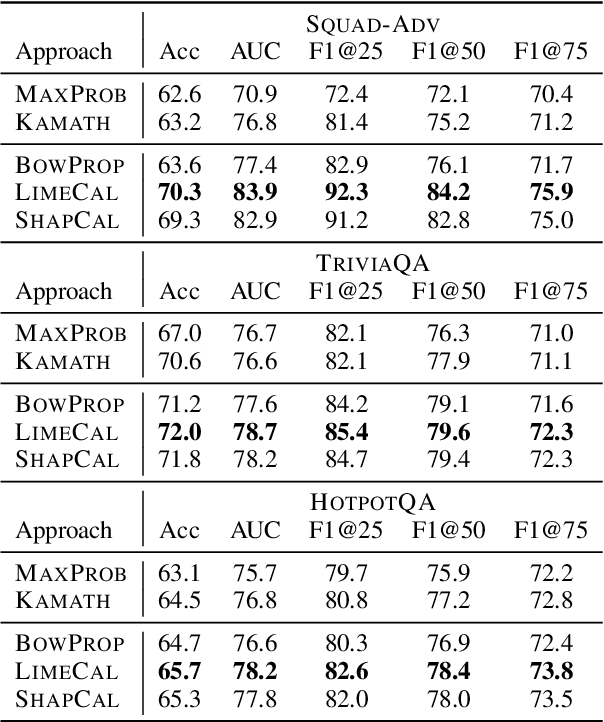
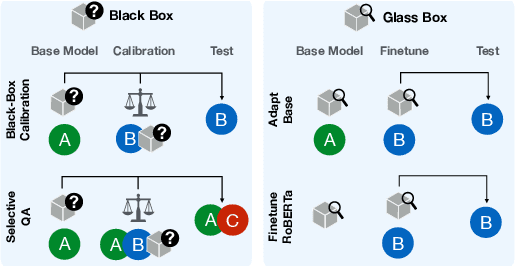
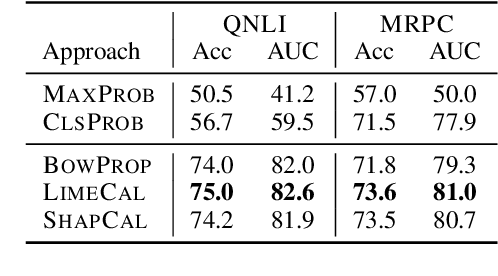
One often wants to take an existing, trained NLP model and use it on data from a new domain. While fine-tuning or few-shot learning can be used to adapt the base model, there is no one simple recipe to getting these working; moreover, one may not have access to the original model weights if it is deployed as a black box. To this end, we study how to improve a black box model's performance on a new domain given examples from the new domain by leveraging explanations of the model's behavior. Our approach first extracts a set of features combining human intuition about the task with model attributions generated by black box interpretation techniques, and then uses a simple model to calibrate or rerank the model's predictions based on the features. We experiment with our method on two tasks, extractive question answering and natural language inference, covering adaptation from several pairs of domains. The experimental results across all the domain pairs show that explanations are useful for calibrating these models. We show that the calibration features transfer to some extent between tasks and shed light on how to effectively use them.
CREAK: A Dataset for Commonsense Reasoning over Entity Knowledge
Sep 03, 2021

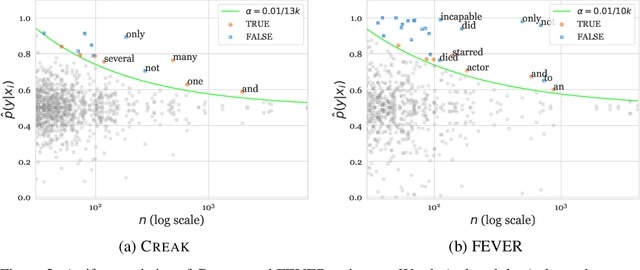

Most benchmark datasets targeting commonsense reasoning focus on everyday scenarios: physical knowledge like knowing that you could fill a cup under a waterfall [Talmor et al., 2019], social knowledge like bumping into someone is awkward [Sap et al., 2019], and other generic situations. However, there is a rich space of commonsense inferences anchored to knowledge about specific entities: for example, deciding the truthfulness of a claim "Harry Potter can teach classes on how to fly on a broomstick." Can models learn to combine entity knowledge with commonsense reasoning in this fashion? We introduce CREAK, a testbed for commonsense reasoning about entity knowledge, bridging fact-checking about entities (Harry Potter is a wizard and is skilled at riding a broomstick) with commonsense inferences (if you're good at a skill you can teach others how to do it). Our dataset consists of 13k human-authored English claims about entities that are either true or false, in addition to a small contrast set. Crowdworkers can easily come up with these statements and human performance on the dataset is high (high 90s); we argue that models should be able to blend entity knowledge and commonsense reasoning to do well here. In our experiments, we focus on the closed-book setting and observe that a baseline model finetuned on existing fact verification benchmark struggles on CREAK. Training a model on CREAK improves accuracy by a substantial margin, but still falls short of human performance. Our benchmark provides a unique probe into natural language understanding models, testing both its ability to retrieve facts (e.g., who teaches at the University of Chicago?) and unstated commonsense knowledge (e.g., butlers do not yell at guests).
Dissecting Generation Modes for Abstractive Summarization Models via Ablation and Attribution
Jun 03, 2021
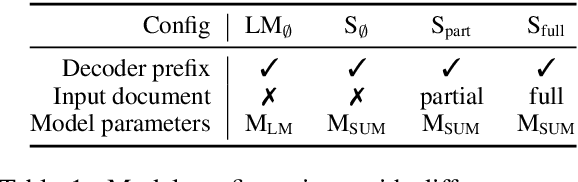
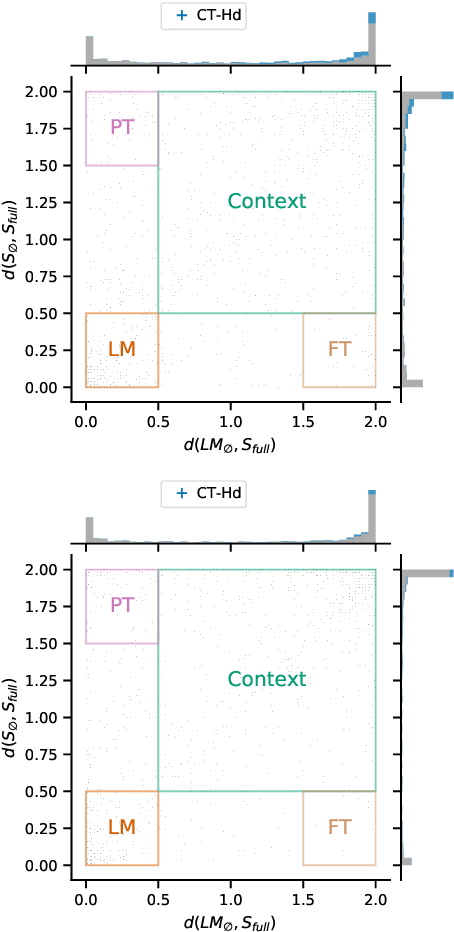
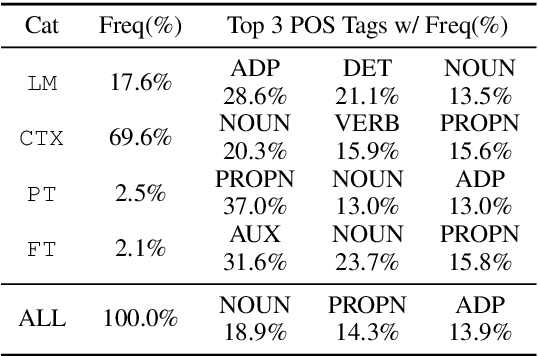
Despite the prominence of neural abstractive summarization models, we know little about how they actually form summaries and how to understand where their decisions come from. We propose a two-step method to interpret summarization model decisions. We first analyze the model's behavior by ablating the full model to categorize each decoder decision into one of several generation modes: roughly, is the model behaving like a language model, is it relying heavily on the input, or is it somewhere in between? After isolating decisions that do depend on the input, we explore interpreting these decisions using several different attribution methods. We compare these techniques based on their ability to select content and reconstruct the model's predicted token from perturbations of the input, thus revealing whether highlighted attributions are truly important for the generation of the next token. While this machinery can be broadly useful even beyond summarization, we specifically demonstrate its capability to identify phrases the summarization model has memorized and determine where in the training pipeline this memorization happened, as well as study complex generation phenomena like sentence fusion on a per-instance basis.