 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCNet: Probing Self-Similarity Learning for Generalized Counting Network
Feb 10, 2023The class-agnostic counting (CAC) problem has caught increasing attention recently due to its wide societal applications and arduous challenges. To count objects of different categories, existing approaches rely on user-provided exemplars, which is hard-to-obtain and limits their generality. In this paper, we aim to empower the framework to recognize adaptive exemplars within the whole images. A zero-shot Generalized Counting Network (GCNet) is developed, which uses a pseudo-Siamese structure to automatically and effectively learn pseudo exemplar clues from inherent repetition patterns. In addition, a weakly-supervised scheme is presented to reduce the burden of laborious density maps required by all contemporary CAC models, allowing GCNet to be trained using count-level supervisory signals in an end-to-end manner. Without providing any spatial location hints, GCNet is capable of adaptively capturing them through a carefully-designed self-similarity learning strategy. Extensive experiments and ablation studies on the prevailing benchmark FSC147 for zero-shot CAC demonstrate the superiority of our GCNet. It performs on par with existing exemplar-dependent methods and shows stunning cross-dataset generality on crowd-specific datasets, e.g., ShanghaiTech Part A, Part B and UCF_QNRF.
Quantum HyperNetworks: Training Binary Neural Networks in Quantum Superposition
Jan 19, 2023



Binary neural networks, i.e., neural networks whose parameters and activations are constrained to only two possible values, offer a compelling avenue for the deployment of deep learning models on energy- and memory-limited devices. However, their training, architectural design, and hyperparameter tuning remain challenging as these involve multiple computationally expensive combinatorial optimization problems. Here we introduce quantum hypernetworks as a mechanism to train binary neural networks on quantum computers, which unify the search over parameters, hyperparameters, and architectures in a single optimization loop. Through classical simulations, we demonstrate that of our approach effectively finds optimal parameters, hyperparameters and architectural choices with high probability on classification problems including a two-dimensional Gaussian dataset and a scaled-down version of the MNIST handwritten digits. We represent our quantum hypernetworks as variational quantum circuits, and find that an optimal circuit depth maximizes the probability of finding performant binary neural networks. Our unified approach provides an immense scope for other applications in the field of machine learning.
Bounding generalization error with input compression: An empirical study with infinite-width networks
Jul 19, 2022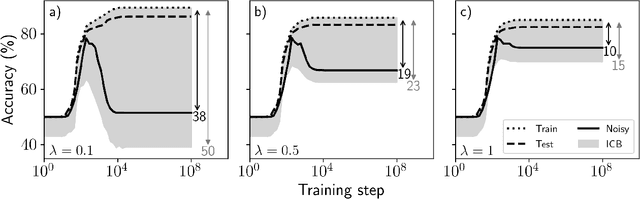

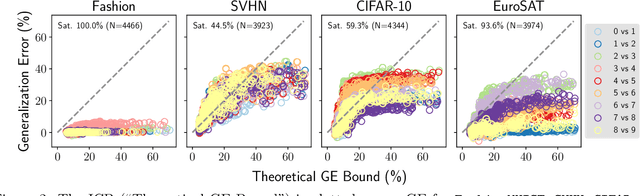
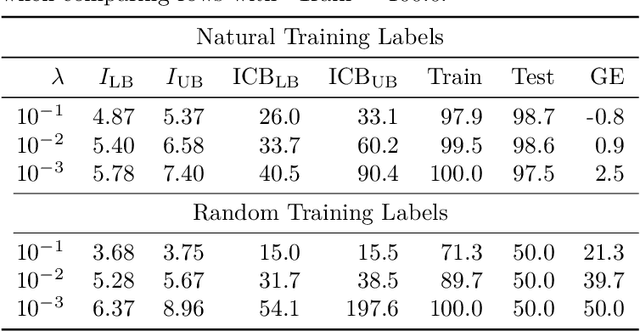
Estimating the Generalization Error (GE) of Deep Neural Networks (DNNs) is an important task that often relies on availability of held-out data. The ability to better predict GE based on a single training set may yield overarching DNN design principles to reduce a reliance on trial-and-error, along with other performance assessment advantages. In search of a quantity relevant to GE, we investigate the Mutual Information (MI) between the input and final layer representations, using the infinite-width DNN limit to bound MI. An existing input compression-based GE bound is used to link MI and GE. To the best of our knowledge, this represents the first empirical study of this bound. In our attempt to empirically falsify the theoretical bound, we find that it is often tight for best-performing models. Furthermore, it detects randomization of training labels in many cases, reflects test-time perturbation robustness, and works well given only few training samples. These results are promising given that input compression is broadly applicable where MI can be estimated with confidence.
Monitoring Shortcut Learning using Mutual Information
Jun 27, 2022
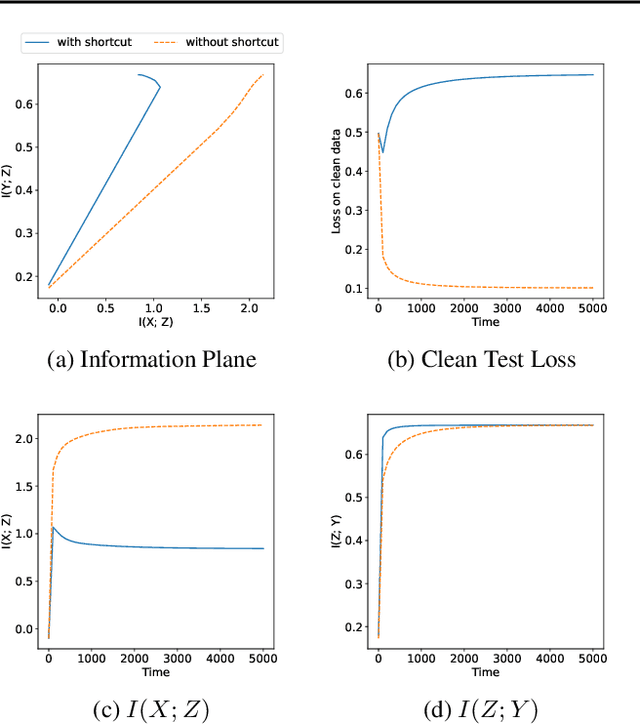
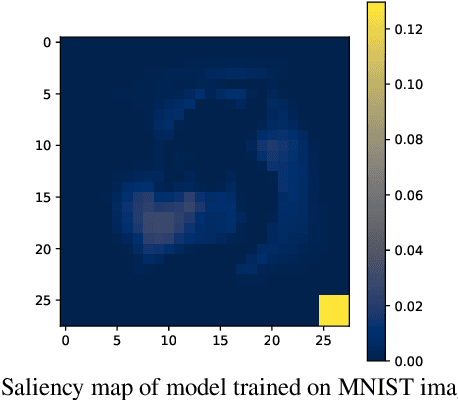
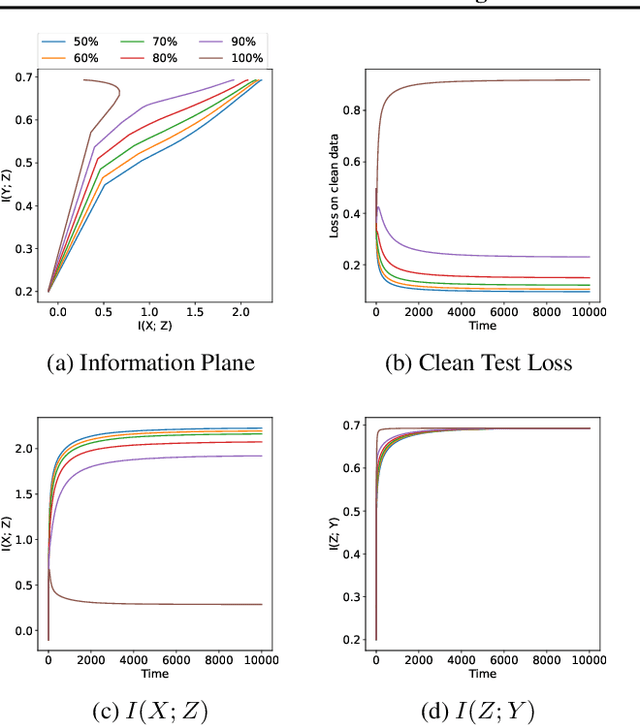
The failure of deep neural networks to generalize to out-of-distribution data is a well-known problem and raises concerns about the deployment of trained networks in safety-critical domains such as healthcare, finance and autonomous vehicles. We study a particular kind of distribution shift $\unicode{x2013}$ shortcuts or spurious correlations in the training data. Shortcut learning is often only exposed when models are evaluated on real-world data that does not contain the same spurious correlations, posing a serious dilemma for AI practitioners to properly assess the effectiveness of a trained model for real-world applications. In this work, we propose to use the mutual information (MI) between the learned representation and the input as a metric to find where in training, the network latches onto shortcuts. Experiments demonstrate that MI can be used as a domain-agnostic metric for monitoring shortcut learning.
Understanding the impact of image and input resolution on deep digital pathology patch classifiers
Apr 29, 2022
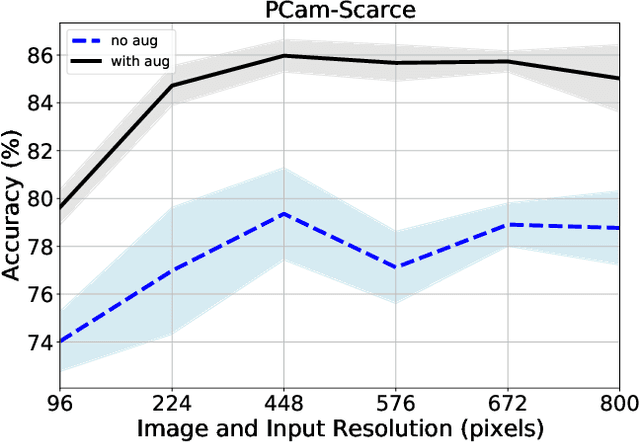
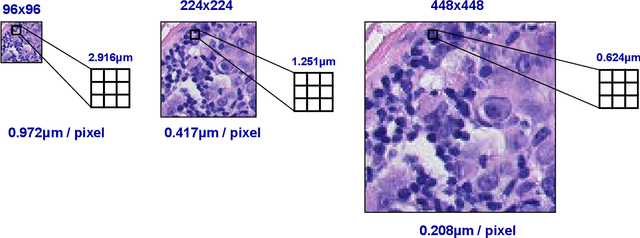
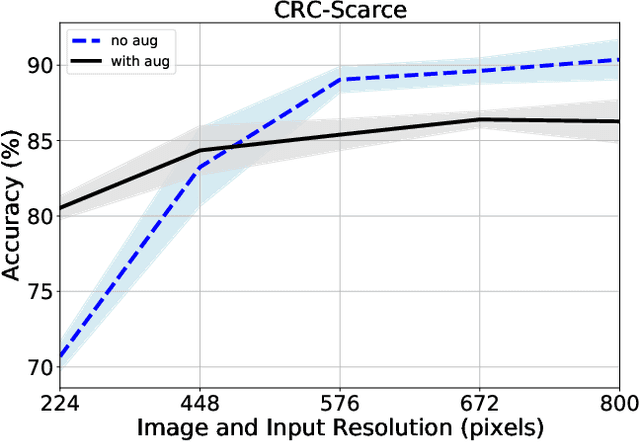
We consider annotation efficient learning in Digital Pathology (DP), where expert annotations are expensive and thus scarce. We explore the impact of image and input resolution on DP patch classification performance. We use two cancer patch classification datasets PCam and CRC, to validate the results of our study. Our experiments show that patch classification performance can be improved by manipulating both the image and input resolution in annotation-scarce and annotation-rich environments. We show a positive correlation between the image and input resolution and the patch classification accuracy on both datasets. By exploiting the image and input resolution, our final model trained on < 1% of data performs equally well compared to the model trained on 100% of data in the original image resolution on the PCam dataset.
DeepRNG: Towards Deep Reinforcement Learning-Assisted Generative Testing of Software
Jan 29, 2022Although machine learning (ML) has been successful in automating various software engineering needs, software testing still remains a highly challenging topic. In this paper, we aim to improve the generative testing of software by directly augmenting the random number generator (RNG) with a deep reinforcement learning (RL) agent using an efficient, automatically extractable state representation of the software under test. Using the Cosmos SDK as the testbed, we show that the proposed DeepRNG framework provides a statistically significant improvement to the testing of the highly complex software library with over 350,000 lines of code. The source code of the DeepRNG framework is publicly available online.
On Evaluation Metrics for Graph Generative Models
Jan 24, 2022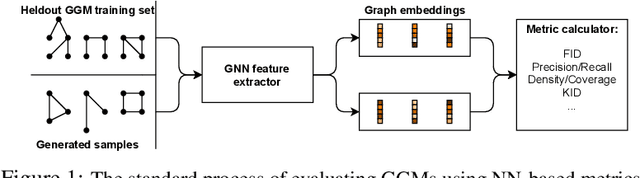
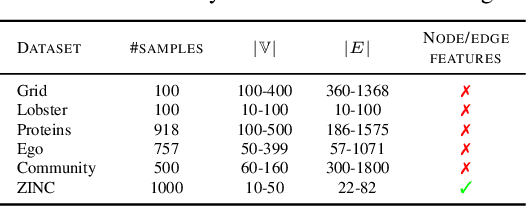
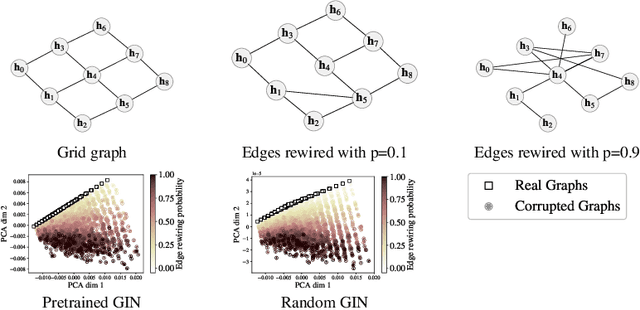

In image generation, generative models can be evaluated naturally by visually inspecting model outputs. However, this is not always the case for graph generative models (GGMs), making their evaluation challenging. Currently, the standard process for evaluating GGMs suffers from three critical limitations: i) it does not produce a single score which makes model selection challenging, ii) in many cases it fails to consider underlying edge and node features, and iii) it is prohibitively slow to perform. In this work, we mitigate these issues by searching for scalar, domain-agnostic, and scalable metrics for evaluating and ranking GGMs. To this end, we study existing GGM metrics and neural-network-based metrics emerging from generative models of images that use embeddings extracted from a task-specific network. Motivated by the power of certain Graph Neural Networks (GNNs) to extract meaningful graph representations without any training, we introduce several metrics based on the features extracted by an untrained random GNN. We design experiments to thoroughly test metrics on their ability to measure the diversity and fidelity of generated graphs, as well as their sample and computational efficiency. Depending on the quantity of samples, we recommend one of two random-GNN-based metrics that we show to be more expressive than pre-existing metrics. While we focus on applying these metrics to GGM evaluation, in practice this enables the ability to easily compute the dissimilarity between any two sets of graphs regardless of domain. Our code is released at: https://github.com/uoguelph-mlrg/GGM-metrics.
Learning with Less Labels in Digital Pathology via Scribble Supervision from Natural Images
Jan 20, 2022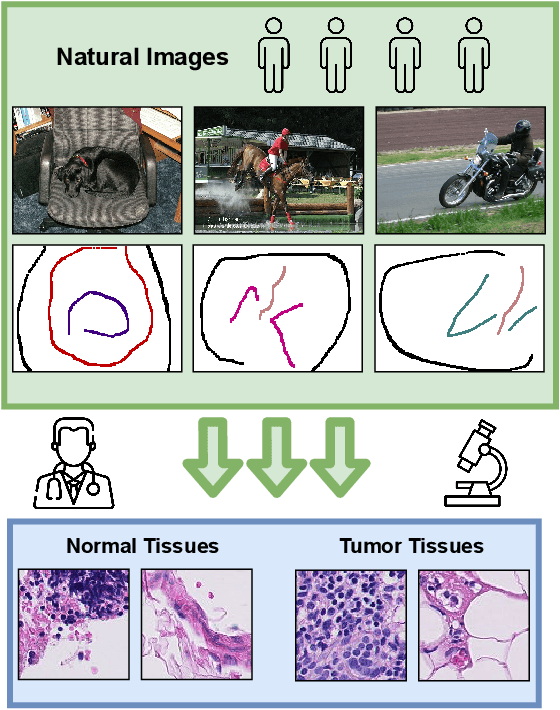
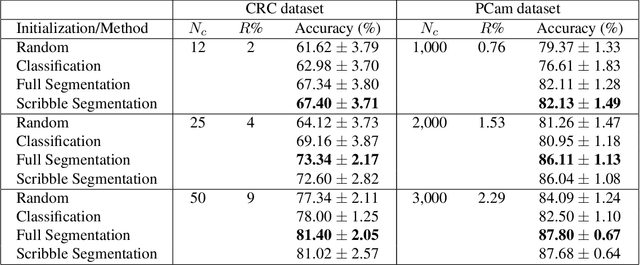
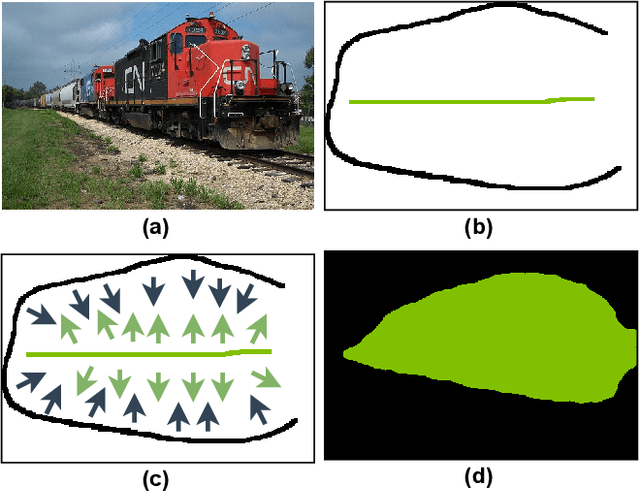

A critical challenge of training deep learning models in the Digital Pathology (DP) domain is the high annotation cost by medical experts. One way to tackle this issue is via transfer learning from the natural image domain (NI), where the annotation cost is considerably cheaper. Cross-domain transfer learning from NI to DP is shown to be successful via class labels. One potential weakness of relying on class labels is the lack of spatial information, which can be obtained from spatial labels such as full pixel-wise segmentation labels and scribble labels. We demonstrate that scribble labels from NI domain can boost the performance of DP models on two cancer classification datasets (Patch Camelyon Breast Cancer and Colorectal Cancer dataset). Furthermore, we show that models trained with scribble labels yield the same performance boost as full pixel-wise segmentation labels despite being significantly easier and faster to collect.
Domain-Agnostic Clustering with Self-Distillation
Nov 23, 2021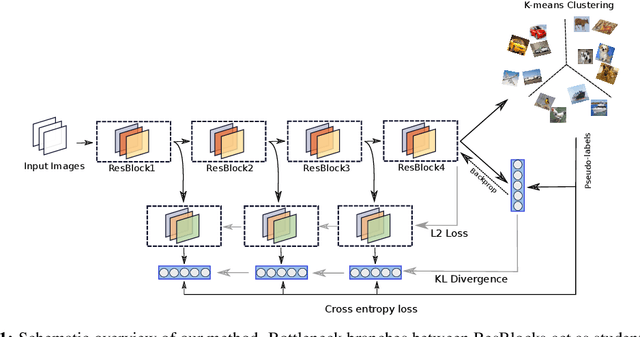

Recent advancements in self-supervised learning have reduced the gap between supervised and unsupervised representation learning. However, most self-supervised and deep clustering techniques rely heavily on data augmentation, rendering them ineffective for many learning tasks where insufficient domain knowledge exists for performing augmentation. We propose a new self-distillation based algorithm for domain-agnostic clustering. Our method builds upon the existing deep clustering frameworks and requires no separate student model. The proposed method outperforms existing domain agnostic (augmentation-free) algorithms on CIFAR-10. We empirically demonstrate that knowledge distillation can improve unsupervised representation learning by extracting richer `dark knowledge' from the model than using predicted labels alone. Preliminary experiments also suggest that self-distillation improves the convergence of DeepCluster-v2.
An Empirical Study of Neural Kernel Bandits
Nov 05, 2021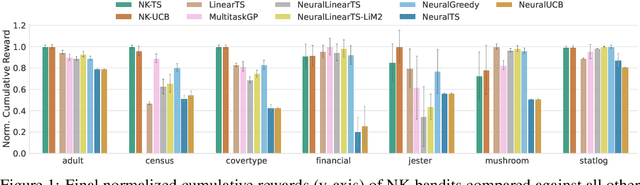

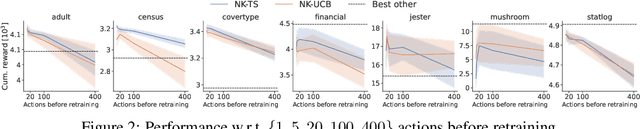

Neural bandits have enabled practitioners to operate efficiently on problems with non-linear reward functions. While in general contextual bandits commonly utilize Gaussian process (GP) predictive distributions for decision making, the most successful neural variants use only the last layer parameters in the derivation. Research on neural kernels (NK) has recently established a correspondence between deep networks and GPs that take into account all the parameters of a NN and can be trained more efficiently than most Bayesian NNs. We propose to directly apply NK-induced distributions to guide an upper confidence bound or Thompson sampling-based policy. We show that NK bandits achieve state-of-the-art performance on highly non-linear structured data. Furthermore, we analyze practical considerations such as training frequency and model partitioning. We believe our work will help better understand the impact of utilizing NKs in applied settings.