 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA State-of-the-Art Morphosyntactic Parser and Lemmatizer for Ancient Greek
Oct 15, 2024



This paper presents an experiment consisting in the comparison of six models to identify a state-of-the-art morphosyntactic parser and lemmatizer for Ancient Greek capable of annotating according to the Ancient Greek Dependency Treebank annotation scheme. A normalized version of the major collections of annotated texts was used to (i) train the baseline model Dithrax with randomly initialized character embeddings and (ii) fine-tune Trankit and four recent models pretrained on Ancient Greek texts, i.e., GreBERTa and PhilBERTa for morphosyntactic annotation and GreTA and PhilTa for lemmatization. A Bayesian analysis shows that Dithrax and Trankit annotate morphology practically equivalently, while syntax is best annotated by Trankit and lemmata by GreTa. The results of the experiment suggest that token embeddings are not sufficient to achieve high UAS and LAS scores unless they are coupled with a modeling strategy specifically designed to capture syntactic relationships. The dataset and best-performing models are made available online for reuse.
Opera Graeca Adnotata: Building a 34M+ Token Multilayer Corpus for Ancient Greek
Mar 31, 2024In this article, the beta version 0.1.0 of Opera Graeca Adnotata (OGA), the largest open-access multilayer corpus for Ancient Greek (AG) is presented. OGA consists of 1,687 literary works and 34M+ tokens coming from the PerseusDL and OpenGreekAndLatin GitHub repositories, which host AG texts ranging from about 800 BCE to about 250 CE. The texts have been enriched with seven annotation layers: (i) tokenization layer; (ii) sentence segmentation layer; (iii) lemmatization layer; (iv) morphological layer; (v) dependency layer; (vi) dependency function layer; (vii) Canonical Text Services (CTS) citation layer. The creation of each layer is described by highlighting the main technical and annotation-related issues encountered. Tokenization, sentence segmentation, and CTS citation are performed by rule-based algorithms, while morphosyntactic annotation is the output of the COMBO parser trained on the data of the Ancient Greek Dependency Treebank. For the sake of scalability and reusability, the corpus is released in the standoff formats PAULA XML and its offspring LAULA XML.
SIGTYP 2020 Shared Task: Prediction of Typological Features
Oct 26, 2020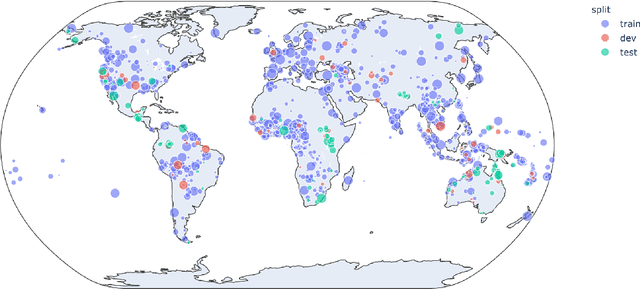

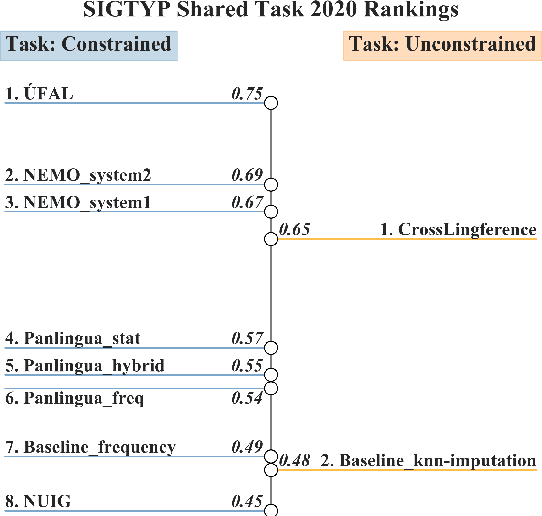
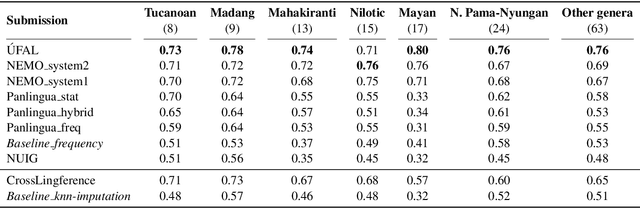
Typological knowledge bases (KBs) such as WALS (Dryer and Haspelmath, 2013) contain information about linguistic properties of the world's languages. They have been shown to be useful for downstream applications, including cross-lingual transfer learning and linguistic probing. A major drawback hampering broader adoption of typological KBs is that they are sparsely populated, in the sense that most languages only have annotations for some features, and skewed, in that few features have wide coverage. As typological features often correlate with one another, it is possible to predict them and thus automatically populate typological KBs, which is also the focus of this shared task. Overall, the task attracted 8 submissions from 5 teams, out of which the most successful methods make use of such feature correlations. However, our error analysis reveals that even the strongest submitted systems struggle with predicting feature values for languages where few features are known.