 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevance-based Margin for Contrastively-trained Video Retrieval Models
Apr 27, 2022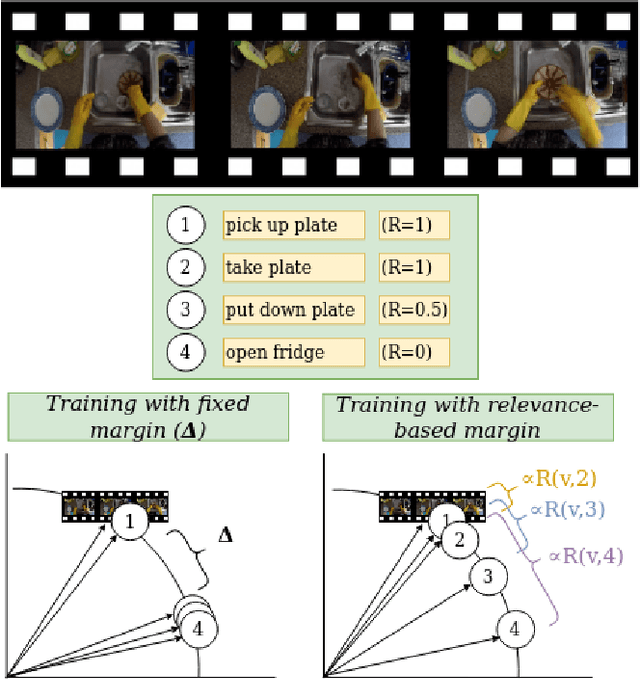
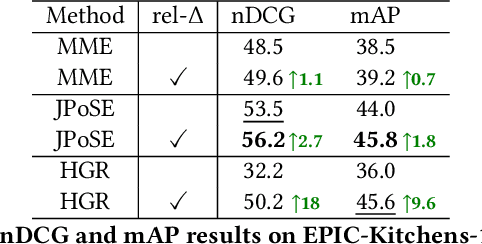
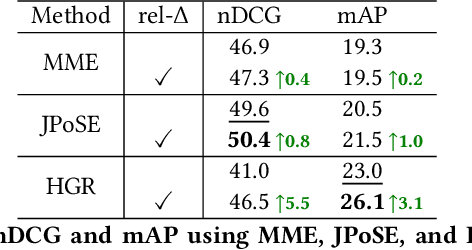
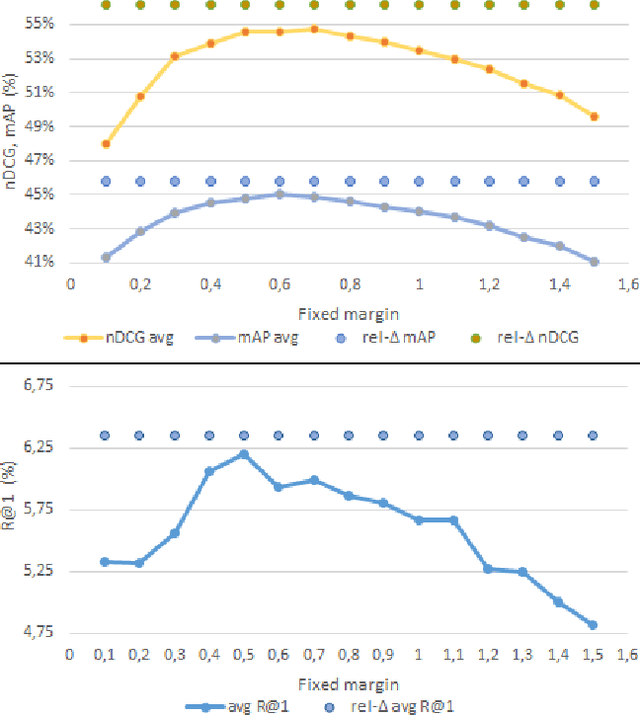
Video retrieval using natural language queries has attracted increasing interest due to its relevance in real-world applications, from intelligent access in private media galleries to web-scale video search. Learning the cross-similarity of video and text in a joint embedding space is the dominant approach. To do so, a contrastive loss is usually employed because it organizes the embedding space by putting similar items close and dissimilar items far. This framework leads to competitive recall rates, as they solely focus on the rank of the groundtruth items. Yet, assessing the quality of the ranking list is of utmost importance when considering intelligent retrieval systems, since multiple items may share similar semantics, hence a high relevance. Moreover, the aforementioned framework uses a fixed margin to separate similar and dissimilar items, treating all non-groundtruth items as equally irrelevant. In this paper we propose to use a variable margin: we argue that varying the margin used during training based on how much relevant an item is to a given query, i.e. a relevance-based margin, easily improves the quality of the ranking lists measured through nDCG and mAP. We demonstrate the advantages of our technique using different models on EPIC-Kitchens-100 and YouCook2. We show that even if we carefully tuned the fixed margin, our technique (which does not have the margin as a hyper-parameter) would still achieve better performance. Finally, extensive ablation studies and qualitative analysis support the robustness of our approach. Code will be released at \url{https://github.com/aranciokov/RelevanceMargin-ICMR22}.
Learning video retrieval models with relevance-aware online mining
Mar 16, 2022
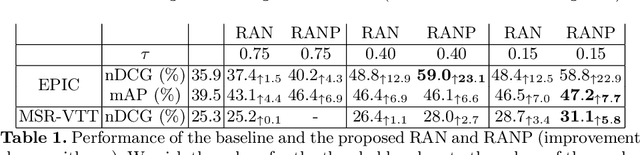

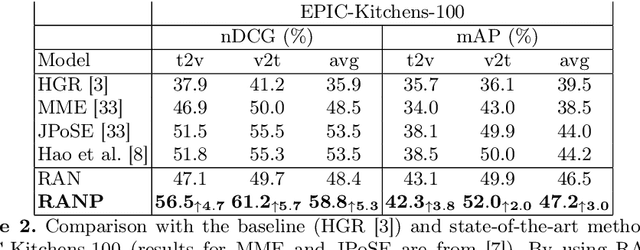
Due to the amount of videos and related captions uploaded every hour, deep learning-based solutions for cross-modal video retrieval are attracting more and more attention. A typical approach consists in learning a joint text-video embedding space, where the similarity of a video and its associated caption is maximized, whereas a lower similarity is enforced with all the other captions, called negatives. This approach assumes that only the video and caption pairs in the dataset are valid, but different captions - positives - may also describe its visual contents, hence some of them may be wrongly penalized. To address this shortcoming, we propose the Relevance-Aware Negatives and Positives mining (RANP) which, based on the semantics of the negatives, improves their selection while also increasing the similarity of other valid positives. We explore the influence of these techniques on two video-text datasets: EPIC-Kitchens-100 and MSR-VTT. By using the proposed techniques, we achieve considerable improvements in terms of nDCG and mAP, leading to state-of-the-art results, e.g. +5.3% nDCG and +3.0% mAP on EPIC-Kitchens-100. We share code and pretrained models at \url{https://github.com/aranciokov/ranp}.
NADE: A Benchmark for Robust Adverse Drug Events Extraction in Face of Negations
Sep 24, 2021
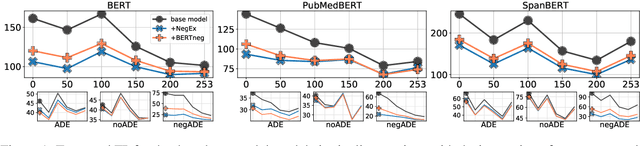
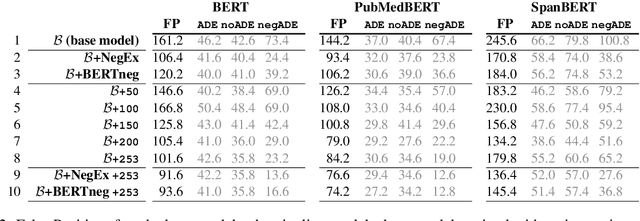
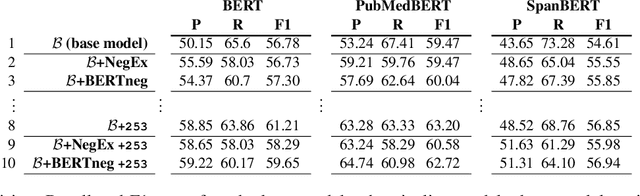
Adverse Drug Event (ADE) extraction models can rapidly examine large collections of social media texts, detecting mentions of drug-related adverse reactions and trigger medical investigations. However, despite the recent advances in NLP, it is currently unknown if such models are robust in face of negation, which is pervasive across language varieties. In this paper we evaluate three state-of-the-art systems, showing their fragility against negation, and then we introduce two possible strategies to increase the robustness of these models: a pipeline approach, relying on a specific component for negation detection; an augmentation of an ADE extraction dataset to artificially create negated samples and further train the models. We show that both strategies bring significant increases in performance, lowering the number of spurious entities predicted by the models. Our dataset and code will be publicly released to encourage research on the topic.
Can the Crowd Judge Truthfulness? A Longitudinal Study on Recent Misinformation about COVID-19
Jul 25, 2021
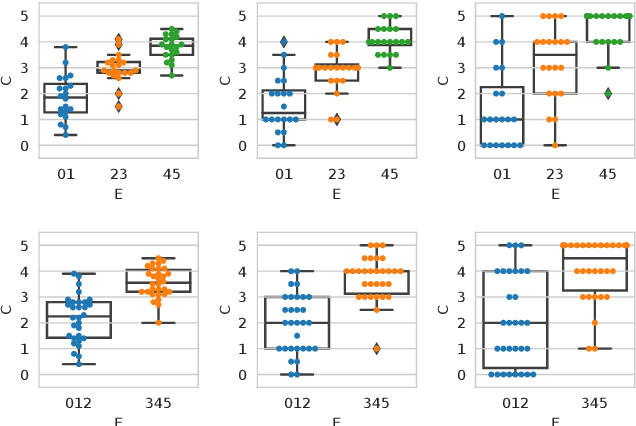
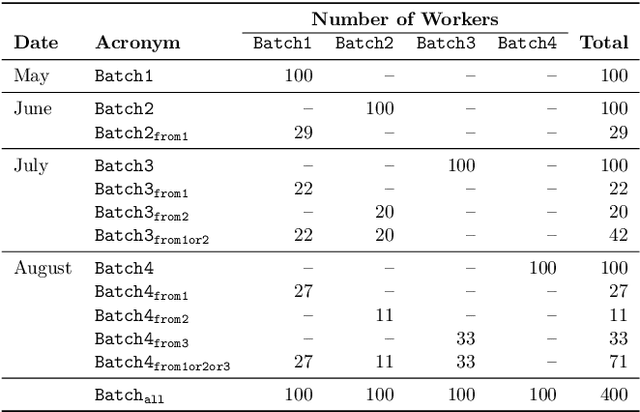
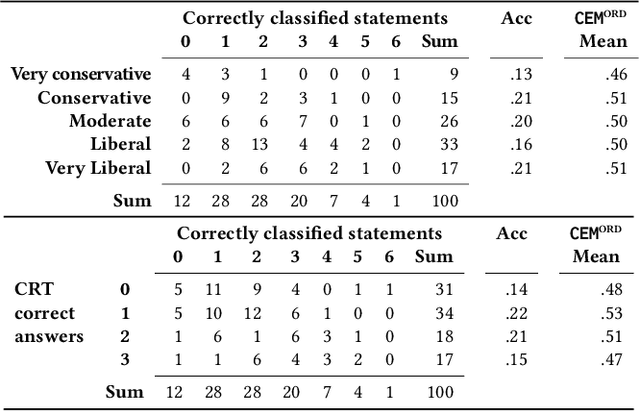
Recently, the misinformation problem has been addressed with a crowdsourcing-based approach: to assess the truthfulness of a statement, instead of relying on a few experts, a crowd of non-expert is exploited. We study whether crowdsourcing is an effective and reliable method to assess truthfulness during a pandemic, targeting statements related to COVID-19, thus addressing (mis)information that is both related to a sensitive and personal issue and very recent as compared to when the judgment is done. In our experiments, crowd workers are asked to assess the truthfulness of statements, and to provide evidence for the assessments. Besides showing that the crowd is able to accurately judge the truthfulness of the statements, we report results on workers behavior, agreement among workers, effect of aggregation functions, of scales transformations, and of workers background and bias. We perform a longitudinal study by re-launching the task multiple times with both novice and experienced workers, deriving important insights on how the behavior and quality change over time. Our results show that: workers are able to detect and objectively categorize online (mis)information related to COVID-19; both crowdsourced and expert judgments can be transformed and aggregated to improve quality; worker background and other signals (e.g., source of information, behavior) impact the quality of the data. The longitudinal study demonstrates that the time-span has a major effect on the quality of the judgments, for both novice and experienced workers. Finally, we provide an extensive failure analysis of the statements misjudged by the crowd-workers.
Improving Adverse Drug Event Extraction with SpanBERT on Different Text Typologies
May 19, 2021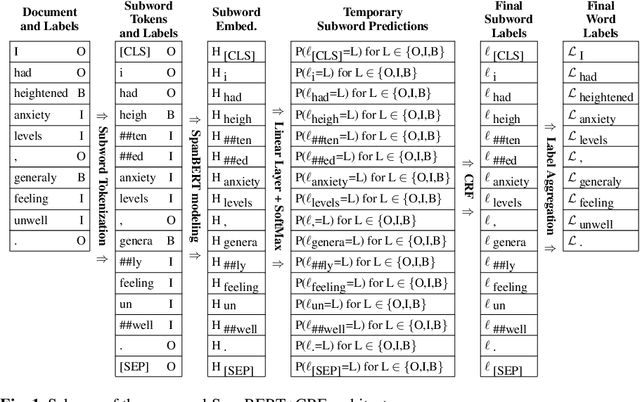
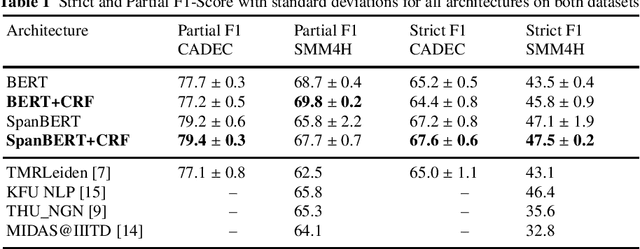
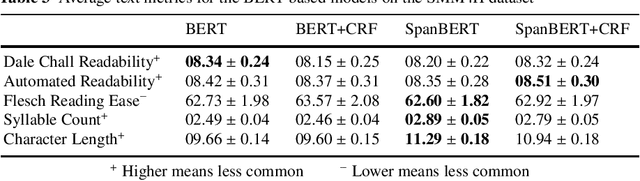
In recent years, Internet users are reporting Adverse Drug Events (ADE) on social media, blogs and health forums. Because of the large volume of reports, pharmacovigilance is seeking to resort to NLP to monitor these outlets. We propose for the first time the use of the SpanBERT architecture for the task of ADE extraction: this new version of the popular BERT transformer showed improved capabilities with multi-token text spans. We validate our hypothesis with experiments on two datasets (SMM4H and CADEC) with different text typologies (tweets and blog posts), finding that SpanBERT combined with a CRF outperforms all the competitors on both of them.
Data augmentation techniques for the Video Question Answering task
Aug 22, 2020



Video Question Answering (VideoQA) is a task that requires a model to analyze and understand both the visual content given by the input video and the textual part given by the question, and the interaction between them in order to produce a meaningful answer. In our work we focus on the Egocentric VideoQA task, which exploits first-person videos, because of the importance of such task which can have impact on many different fields, such as those pertaining the social assistance and the industrial training. Recently, an Egocentric VideoQA dataset, called EgoVQA, has been released. Given its small size, models tend to overfit quickly. To alleviate this problem, we propose several augmentation techniques which give us a +5.5% improvement on the final accuracy over the considered baseline.
The COVID-19 Infodemic: Can the Crowd Judge Recent Misinformation Objectively?
Aug 13, 2020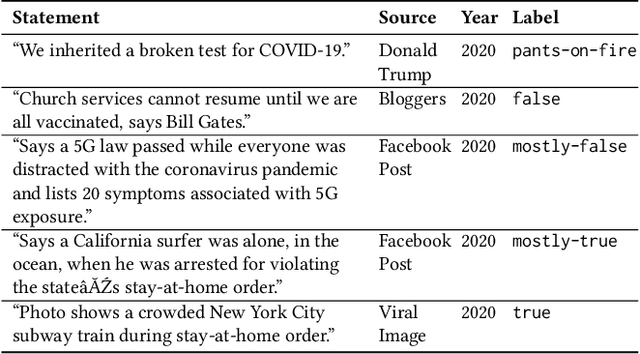

Misinformation is an ever increasing problem that is difficult to solve for the research community and has a negative impact on the society at large. Very recently, the problem has been addressed with a crowdsourcing-based approach to scale up labeling efforts: to assess the truthfulness of a statement, instead of relying on a few experts, a crowd of (non-expert) judges is exploited. We follow the same approach to study whether crowdsourcing is an effective and reliable method to assess statements truthfulness during a pandemic. We specifically target statements related to the COVID-19 health emergency, that is still ongoing at the time of the study and has arguably caused an increase of the amount of misinformation that is spreading online (a phenomenon for which the term "infodemic" has been used). By doing so, we are able to address (mis)information that is both related to a sensitive and personal issue like health and very recent as compared to when the judgment is done: two issues that have not been analyzed in related work. In our experiment, crowd workers are asked to assess the truthfulness of statements, as well as to provide evidence for the assessments as a URL and a text justification. Besides showing that the crowd is able to accurately judge the truthfulness of the statements, we also report results on many different aspects, including: agreement among workers, the effect of different aggregation functions, of scales transformations, and of workers background / bias. We also analyze workers behavior, in terms of queries submitted, URLs found / selected, text justifications, and other behavioral data like clicks and mouse actions collected by means of an ad hoc logger.
Text-to-Image Synthesis Based on Machine Generated Captions
Oct 09, 2019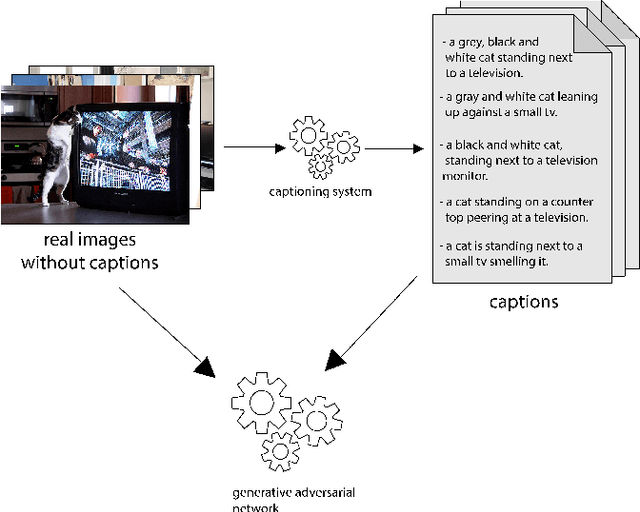
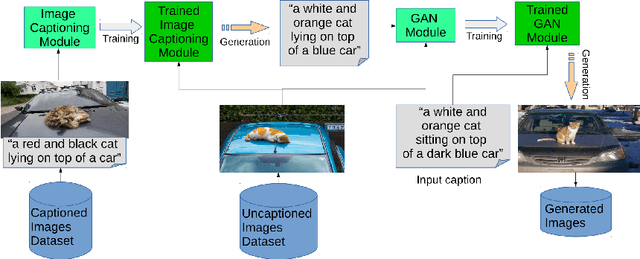


Text to Image Synthesis refers to the process of automatic generation of a photo-realistic image starting from a given text and is revolutionizing many real-world applications. In order to perform such process it is necessary to exploit datasets containing captioned images, meaning that each image is associated with one (or more) captions describing it. Despite the abundance of uncaptioned images datasets, the number of captioned datasets is limited. To address this issue, in this paper we propose an approach capable of generating images starting from a given text using conditional GANs trained on uncaptioned images dataset. In particular, uncaptioned images are fed to an Image Captioning Module to generate the descriptions. Then, the GAN Module is trained on both the input image and the machine-generated caption. To evaluate the results, the performance of our solution is compared with the results obtained by the unconditional GAN. For the experiments, we chose to use the uncaptioned dataset LSUN bedroom. The results obtained in our study are preliminary but still promising.
Video-Based Convolutional Attention for Person Re-Identification
Sep 26, 2019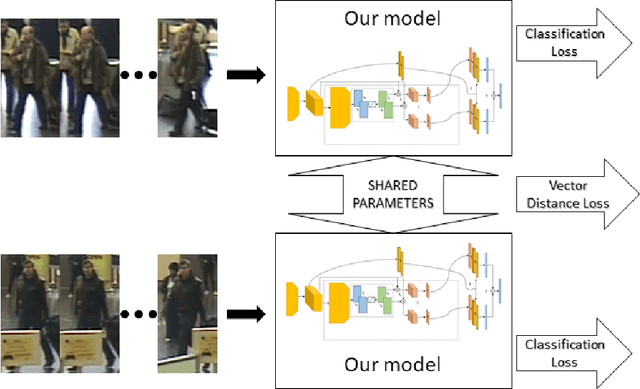

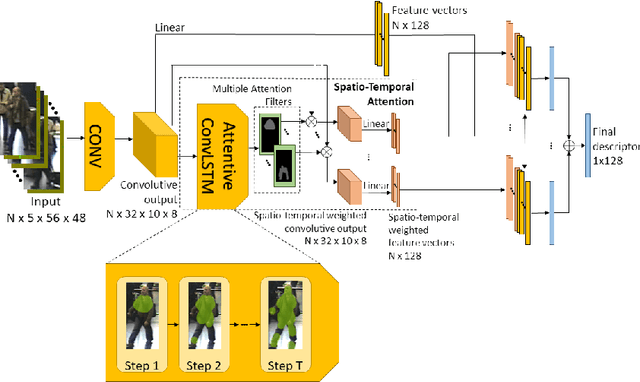
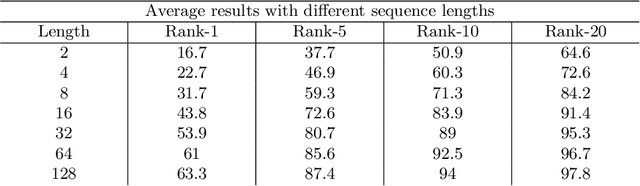
In this paper we consider the problem of video-based person re-identification, which is the task of associating videos of the same person captured by different and non-overlapping cameras. We propose a Siamese framework in which video frames of the person to re-identify and of the candidate one are processed by two identical networks which produce a similarity score. We introduce an attention mechanisms to capture the relevant information both at frame level (spatial information) and at video level (temporal information given by the importance of a specific frame within the sequence). One of the novelties of our approach is given by a joint concurrent processing of both frame and video levels, providing in such a way a very simple architecture. Despite this fact, our approach achieves better performance than the state-of-the-art on the challenging iLIDS-VID dataset.
Predicting the Usefulness of Amazon Reviews Using Off-The-Shelf Argumentation Mining
Sep 21, 2018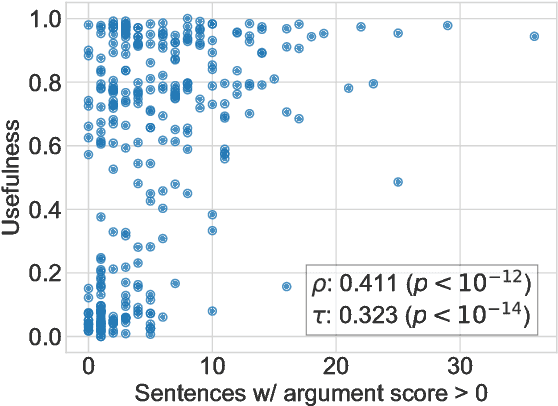
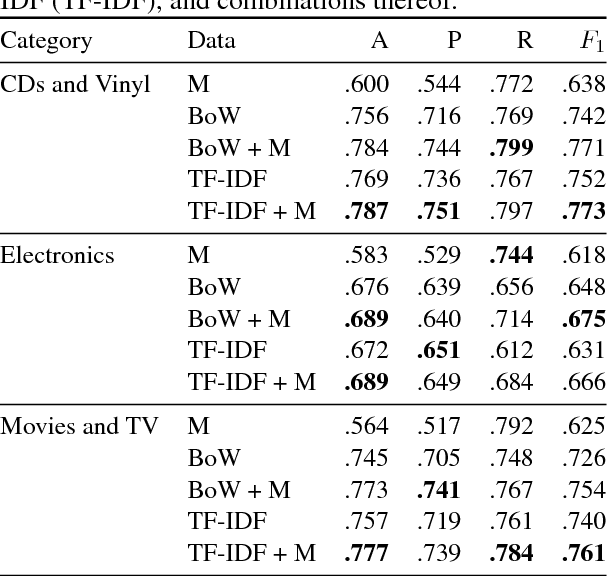
Internet users generate content at unprecedented rates. Building intelligent systems capable of discriminating useful content within this ocean of information is thus becoming a urgent need. In this paper, we aim to predict the usefulness of Amazon reviews, and to do this we exploit features coming from an off-the-shelf argumentation mining system. We argue that the usefulness of a review, in fact, is strictly related to its argumentative content, whereas the use of an already trained system avoids the costly need of relabeling a novel dataset. Results obtained on a large publicly available corpus support this hypothesis.