 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT-steered Editing Instructor for Customization of Abstractive Summarization
May 04, 2023Tailoring outputs of large language models, such as ChatGPT, to specific user needs remains a challenge despite their impressive generation quality. In this paper, we propose a tri-agent generation pipeline consisting of a generator, an instructor, and an editor to enhance the customization of generated outputs. The generator produces an initial output, the user-specific instructor generates editing instructions, and the editor generates a revised output aligned with user preferences. The inference-only large language model (ChatGPT) serves as both the generator and the editor, while a smaller model acts as the user-specific instructor to guide the generation process toward user needs. The instructor is trained using editor-steered reinforcement learning, leveraging feedback from the large-scale editor model to optimize instruction generation. Experimental results on two abstractive summarization datasets demonstrate the effectiveness of our approach in generating outputs that better fulfill user expectations.
NL4Opt Competition: Formulating Optimization Problems Based on Their Natural Language Descriptions
Mar 27, 2023



The Natural Language for Optimization (NL4Opt) Competition was created to investigate methods of extracting the meaning and formulation of an optimization problem based on its text description. Specifically, the goal of the competition is to increase the accessibility and usability of optimization solvers by allowing non-experts to interface with them using natural language. We separate this challenging goal into two sub-tasks: (1) recognize and label the semantic entities that correspond to the components of the optimization problem; (2) generate a meaning representation (i.e., a logical form) of the problem from its detected problem entities. The first task aims to reduce ambiguity by detecting and tagging the entities of the optimization problems. The second task creates an intermediate representation of the linear programming (LP) problem that is converted into a format that can be used by commercial solvers. In this report, we present the LP word problem dataset and shared tasks for the NeurIPS 2022 competition. Furthermore, we investigate and compare the performance of the ChatGPT large language model against the winning solutions. Through this competition, we hope to bring interest towards the development of novel machine learning applications and datasets for optimization modeling.
Discourse Structure Extraction from Pre-Trained and Fine-Tuned Language Models in Dialogues
Feb 12, 2023



Discourse processing suffers from data sparsity, especially for dialogues. As a result, we explore approaches to build discourse structures for dialogues, based on attention matrices from Pre-trained Language Models (PLMs). We investigate multiple tasks for fine-tuning and show that the dialogue-tailored Sentence Ordering task performs best. To locate and exploit discourse information in PLMs, we propose an unsupervised and a semi-supervised method. Our proposals achieve encouraging results on the STAC corpus, with F1 scores of 57.2 and 59.3 for unsupervised and semi-supervised methods, respectively. When restricted to projective trees, our scores improved to 63.3 and 68.1.
Attend to the Right Context: A Plug-and-Play Module for Content-Controllable Summarization
Dec 21, 2022



Content-Controllable Summarization generates summaries focused on the given controlling signals. Due to the lack of large-scale training corpora for the task, we propose a plug-and-play module RelAttn to adapt any general summarizers to the content-controllable summarization task. RelAttn first identifies the relevant content in the source documents, and then makes the model attend to the right context by directly steering the attention weight. We further apply an unsupervised online adaptive parameter searching algorithm to determine the degree of control in the zero-shot setting, while such parameters are learned in the few-shot setting. By applying the module to three backbone summarization models, experiments show that our method effectively improves all the summarizers, and outperforms the prefix-based method and a widely used plug-and-play model in both zero- and few-shot settings. Tellingly, more benefit is observed in the scenarios when more control is needed.
Unsupervised Inference of Data-Driven Discourse Structures using a Tree Auto-Encoder
Oct 18, 2022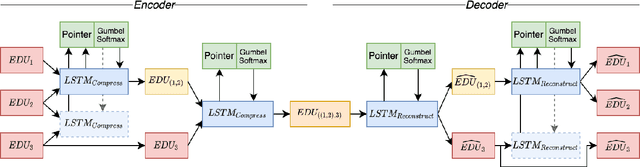
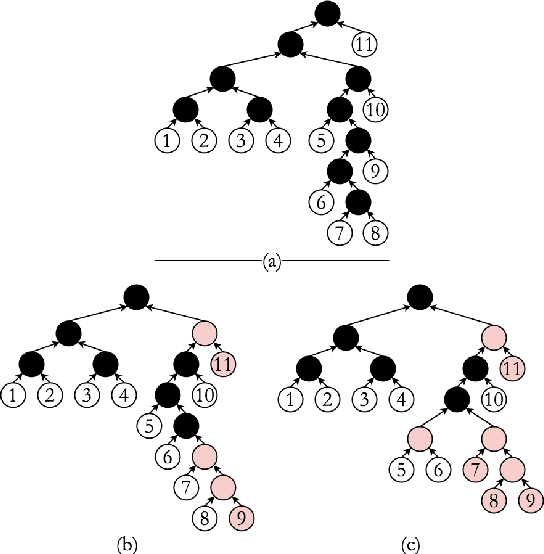
With a growing need for robust and general discourse structures in many downstream tasks and real-world applications, the current lack of high-quality, high-quantity discourse trees poses a severe shortcoming. In order the alleviate this limitation, we propose a new strategy to generate tree structures in a task-agnostic, unsupervised fashion by extending a latent tree induction framework with an auto-encoding objective. The proposed approach can be applied to any tree-structured objective, such as syntactic parsing, discourse parsing and others. However, due to the especially difficult annotation process to generate discourse trees, we initially develop such method to complement task-specific models in generating much larger and more diverse discourse treebanks.
* Extended Abstract. Non-Archival. 2 pages
Towards Domain-Independent Supervised Discourse Parsing Through Gradient Boosting
Oct 18, 2022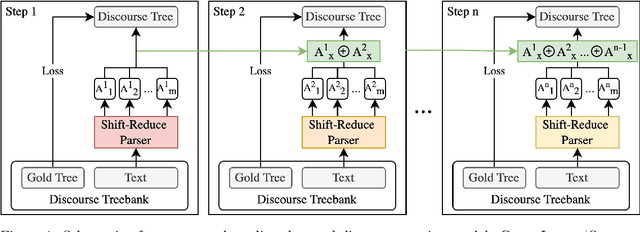
Discourse analysis and discourse parsing have shown great impact on many important problems in the field of Natural Language Processing (NLP). Given the direct impact of discourse annotations on model performance and interpretability, robustly extracting discourse structures from arbitrary documents is a key task to further improve computational models in NLP. To this end, we present a new, supervised paradigm directly tackling the domain adaptation issue in discourse parsing. Specifically, we introduce the first fully supervised discourse parser designed to alleviate the domain dependency through a staged model of weak classifiers by introducing the gradient boosting framework.
* Extended Abstract. Non Archival. 3 pages
Transition to Adulthood for Young People with Intellectual or Developmental Disabilities: Emotion Detection and Topic Modeling
Sep 21, 2022Transition to Adulthood is an essential life stage for many families. The prior research has shown that young people with intellectual or development disabil-ities (IDD) have more challenges than their peers. This study is to explore how to use natural language processing (NLP) methods, especially unsupervised machine learning, to assist psychologists to analyze emotions and sentiments and to use topic modeling to identify common issues and challenges that young people with IDD and their families have. Additionally, the results were compared to those obtained from young people without IDD who were in tran-sition to adulthood. The findings showed that NLP methods can be very useful for psychologists to analyze emotions, conduct cross-case analysis, and sum-marize key topics from conversational data. Our Python code is available at https://github.com/mlaricheva/emotion_topic_modeling.
* Conference proceedings of 2022 SBP-BRiMS
Improving Topic Segmentation by Injecting Discourse Dependencies
Sep 18, 2022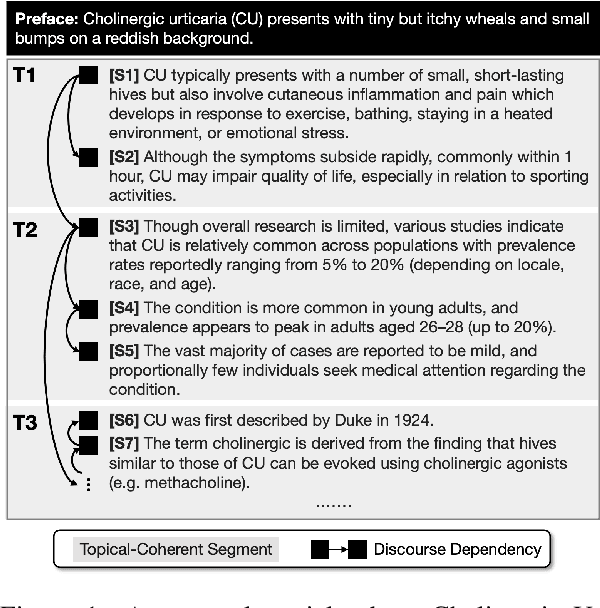
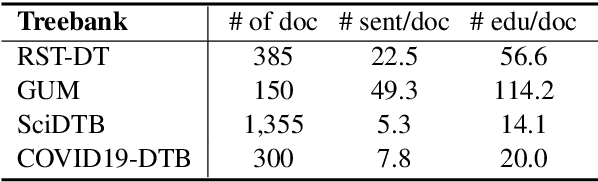
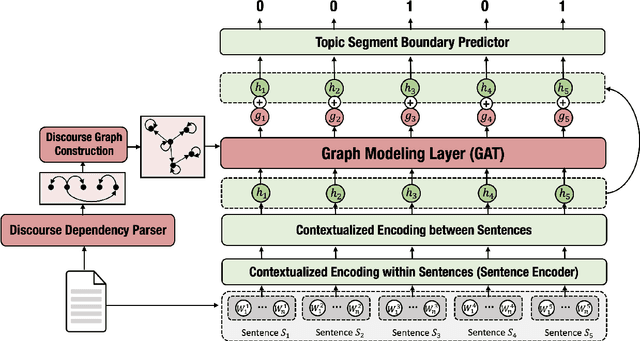
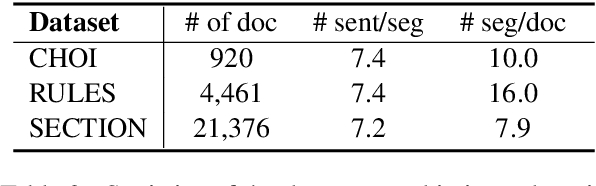
Recent neural supervised topic segmentation models achieve distinguished superior effectiveness over unsupervised methods, with the availability of large-scale training corpora sampled from Wikipedia. These models may, however, suffer from limited robustness and transferability caused by exploiting simple linguistic cues for prediction, but overlooking more important inter-sentential topical consistency. To address this issue, we present a discourse-aware neural topic segmentation model with the injection of above-sentence discourse dependency structures to encourage the model make topic boundary prediction based more on the topical consistency between sentences. Our empirical study on English evaluation datasets shows that injecting above-sentence discourse structures to a neural topic segmenter with our proposed strategy can substantially improve its performances on intra-domain and out-of-domain data, with little increase of model's complexity.
Entity-based SpanCopy for Abstractive Summarization to Improve the Factual Consistency
Sep 07, 2022
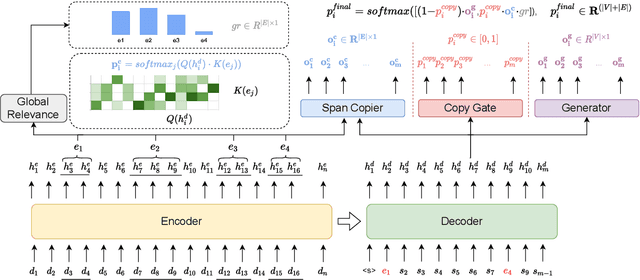
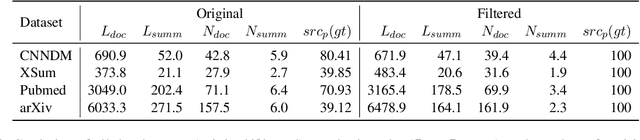
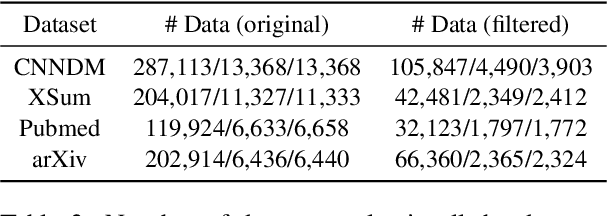
Despite the success of recent abstractive summarizers on automatic evaluation metrics, the generated summaries still present factual inconsistencies with the source document. In this paper, we focus on entity-level factual inconsistency, i.e. reducing the mismatched entities between the generated summaries and the source documents. We therefore propose a novel entity-based SpanCopy mechanism, and explore its extension with a Global Relevance component. Experiment results on four summarization datasets show that SpanCopy can effectively improve the entity-level factual consistency with essentially no change in the word-level and entity-level saliency. The code is available at https://github.com/Wendy-Xiao/Entity-based-SpanCopy
Automated Utterance Labeling of Conversations Using Natural Language Processing
Aug 12, 2022
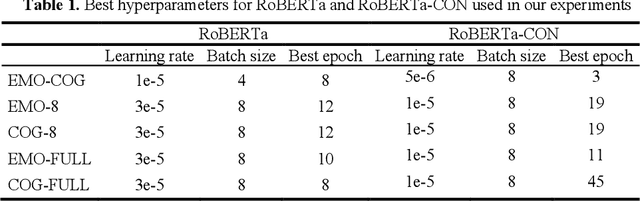
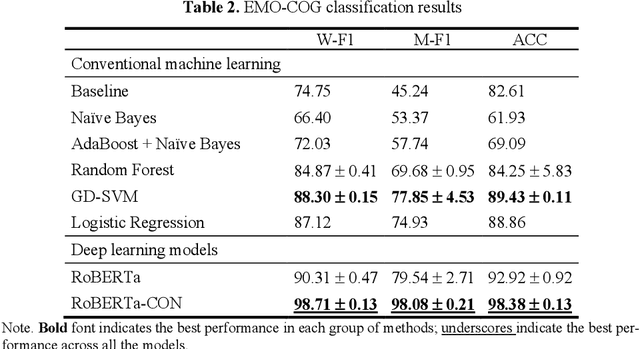
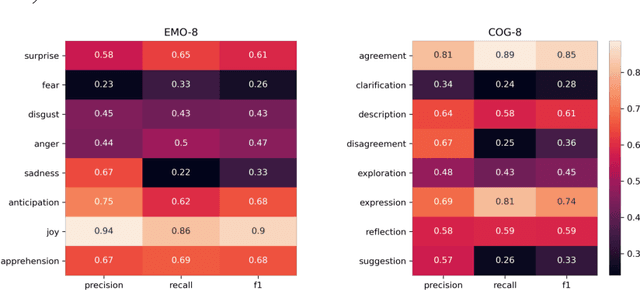
Conversational data is essential in psychology because it can help researchers understand individuals cognitive processes, emotions, and behaviors. Utterance labelling is a common strategy for analyzing this type of data. The development of NLP algorithms allows researchers to automate this task. However, psychological conversational data present some challenges to NLP researchers, including multilabel classification, a large number of classes, and limited available data. This study explored how automated labels generated by NLP methods are comparable to human labels in the context of conversations on adulthood transition. We proposed strategies to handle three common challenges raised in psychological studies. Our findings showed that the deep learning method with domain adaptation (RoBERTa-CON) outperformed all other machine learning methods; and the hierarchical labelling system that we proposed was shown to help researchers strategically analyze conversational data. Our Python code and NLP model are available at https://github.com/mlaricheva/automated_labeling.