 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
Paper and Code
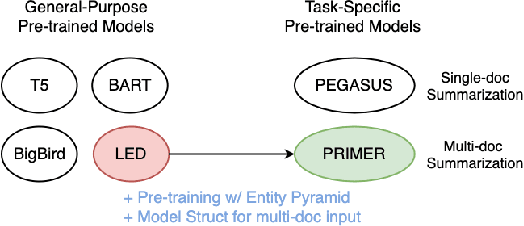
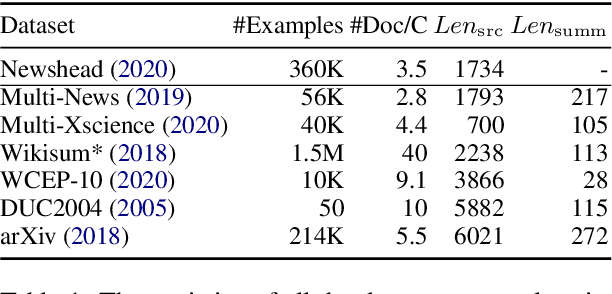
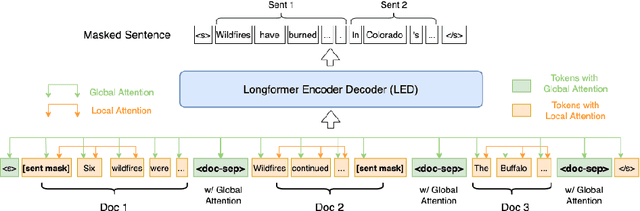
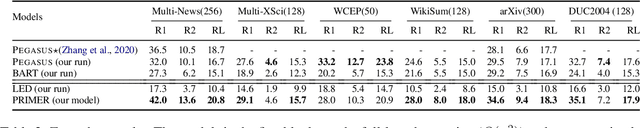
Recently proposed pre-trained generation models achieve strong performance on single-document summarization benchmarks. However, most of them are pre-trained with general-purpose objectives and mainly aim to process single document inputs. In this paper, we propose PRIMER, a pre-trained model for multi-document representation with focus on summarization that reduces the need for dataset-specific architectures and large amounts of fine-tuning labeled data. Specifically, we adopt the Longformer architecture with proper input transformation and global attention to fit for multi-document inputs, and we use Gap Sentence Generation objective with a new strategy to select salient sentences for the whole cluster, called Entity Pyramid, to teach the model to select and aggregate information across a cluster of related documents. With extensive experiments on 6 multi-document summarization datasets from 3 different domains on the zero-shot, few-shot, and full-supervised settings, our model, PRIMER, outperforms current state-of-the-art models on most of these settings with large margins. Code and pre-trained models are released at https://github.com/allenai/PRIMER