 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPREAD: Subspace Representation Distillation for Lifelong Imitation Learning
Mar 09, 2026A key challenge in lifelong imitation learning (LIL) is enabling agents to acquire new skills from expert demonstrations while retaining prior knowledge. This requires preserving the low-dimensional manifolds and geometric structures that underlie task representations across sequential learning. Existing distillation methods, which rely on L2-norm feature matching in raw feature space, are sensitive to noise and high-dimensional variability, often failing to preserve intrinsic task manifolds. To address this, we introduce SPREAD, a geometry-preserving framework that employs singular value decomposition (SVD) to align policy representations across tasks within low-rank subspaces. This alignment maintains the underlying geometry of multimodal features, facilitating stable transfer, robustness, and generalization. Additionally, we propose a confidence-guided distillation strategy that applies a Kullback-Leibler divergence loss restricted to the top-M most confident action samples, emphasizing reliable modes and improving optimization stability. Experiments on the LIBERO, lifelong imitation learning benchmark, show that SPREAD substantially improves knowledge transfer, mitigates catastrophic forgetting, and achieves state-of-the-art performance.
Improving Generalization Ability of Robotic Imitation Learning by Resolving Causal Confusion in Observations
Jul 30, 2025Recent developments in imitation learning have considerably advanced robotic manipulation. However, current techniques in imitation learning can suffer from poor generalization, limiting performance even under relatively minor domain shifts. In this work, we aim to enhance the generalization capabilities of complex imitation learning algorithms to handle unpredictable changes from the training environments to deployment environments. To avoid confusion caused by observations that are not relevant to the target task, we propose to explicitly learn the causal relationship between observation components and expert actions, employing a framework similar to [6], where a causal structural function is learned by intervention on the imitation learning policy. Disentangling the feature representation from image input as in [6] is hard to satisfy in complex imitation learning process in robotic manipulation, we theoretically clarify that this requirement is not necessary in causal relationship learning. Therefore, we propose a simple causal structure learning framework that can be easily embedded in recent imitation learning architectures, such as the Action Chunking Transformer [31]. We demonstrate our approach using a simulation of the ALOHA [31] bimanual robot arms in Mujoco, and show that the method can considerably mitigate the generalization problem of existing complex imitation learning algorithms.
Field trial on Ocean Estimation for Multi-Vessel Multi-Float-based Active perception
Jun 17, 2021
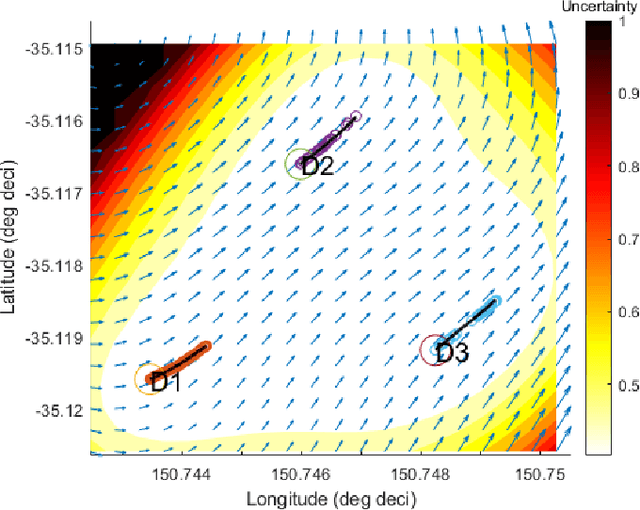
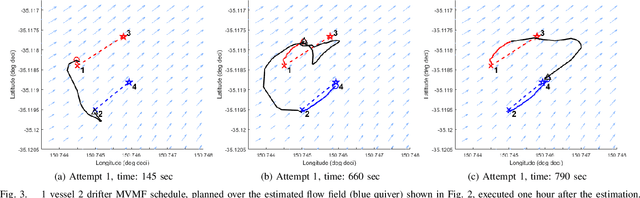
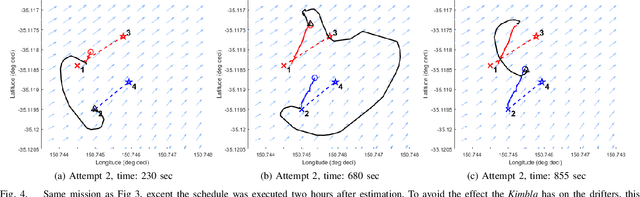
Marine vehicles have been used for various scientific missions where information over features of interest is collected. In order to maximise efficiency in collecting information over a large search space, we should be able to deploy a large number of autonomous vehicles that make a decision based on the latest understanding of the target feature in the environment. In our previous work, we have presented a hierarchical framework for the multi-vessel multi-float (MVMF) problem where surface vessels drop and pick up underactuated floats in a time-minimal way. In this paper, we present the field trial results using the framework with a number of drifters and floats. We discovered a number of important aspects that need to be considered in the proposed framework, and present the potential approaches to address the challenges.