 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Pre-Consultation Ability of LLMs using Diagnostic Guidelines
Jan 08, 2026We introduce EPAG, a benchmark dataset and framework designed for Evaluating the Pre-consultation Ability of LLMs using diagnostic Guidelines. LLMs are evaluated directly through HPI-diagnostic guideline comparison and indirectly through disease diagnosis. In our experiments, we observe that small open-source models fine-tuned with a well-curated, task-specific dataset can outperform frontier LLMs in pre-consultation. Additionally, we find that increased amount of HPI (History of Present Illness) does not necessarily lead to improved diagnostic performance. Further experiments reveal that the language of pre-consultation influences the characteristics of the dialogue. By open-sourcing our dataset and evaluation pipeline on https://github.com/seemdog/EPAG, we aim to contribute to the evaluation and further development of LLM applications in real-world clinical settings.
Format Inertia: A Failure Mechanism of LLMs in Medical Pre-Consultation
Oct 02, 2025Recent advances in Large Language Models (LLMs) have brought significant improvements to various service domains, including chatbots and medical pre-consultation applications. In the healthcare domain, the most common approach for adapting LLMs to multi-turn dialogue generation is Supervised Fine-Tuning (SFT). However, datasets for SFT in tasks like medical pre-consultation typically exhibit a skewed turn-count distribution. Training on such data induces a novel failure mechanism we term **Format Inertia**, where models tend to generate repetitive, format-correct, but diagnostically uninformative questions in long medical dialogues. To mitigate this observed failure mechanism, we adopt a simple, data-centric method that rebalances the turn-count distribution of the training dataset. Experimental results show that our approach substantially alleviates Format Inertia in medical pre-consultation.
Taxonomy of Comprehensive Safety for Clinical Agents
Sep 26, 2025Safety is a paramount concern in clinical chatbot applications, where inaccurate or harmful responses can lead to serious consequences. Existing methods--such as guardrails and tool calling--often fall short in addressing the nuanced demands of the clinical domain. In this paper, we introduce TACOS (TAxonomy of COmprehensive Safety for Clinical Agents), a fine-grained, 21-class taxonomy that integrates safety filtering and tool selection into a single user intent classification step. TACOS is a taxonomy that can cover a wide spectrum of clinical and non-clinical queries, explicitly modeling varying safety thresholds and external tool dependencies. To validate our framework, we curate a TACOS-annotated dataset and perform extensive experiments. Our results demonstrate the value of a new taxonomy specialized for clinical agent settings, and reveal useful insights about train data distribution and pretrained knowledge of base models.
Hierarchy Decoder is All You Need To Text Classification
Nov 22, 2021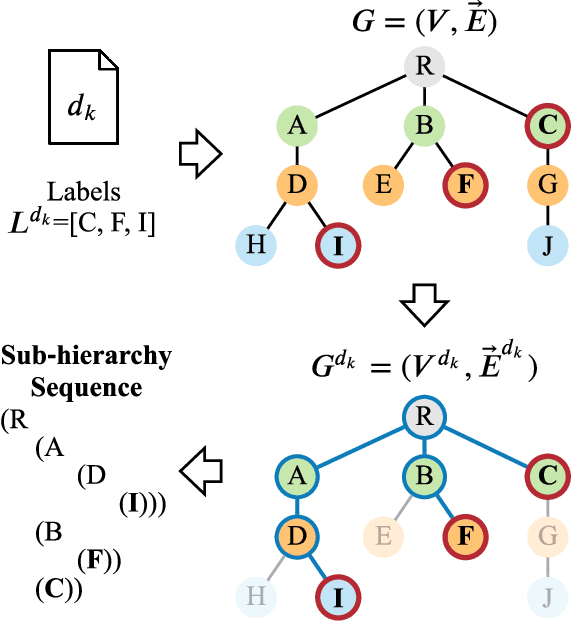
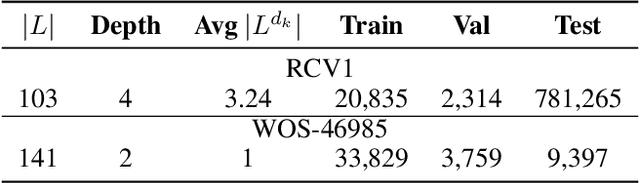
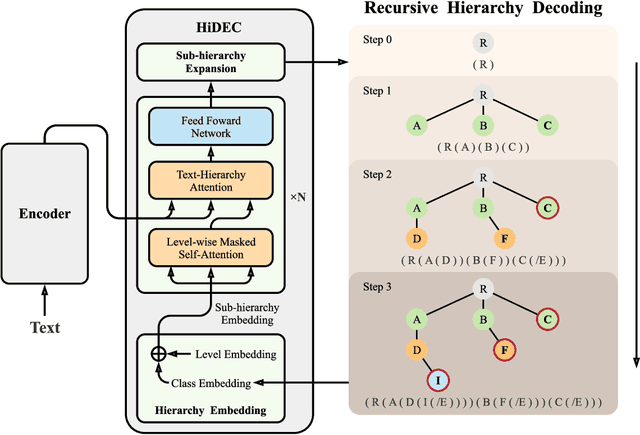
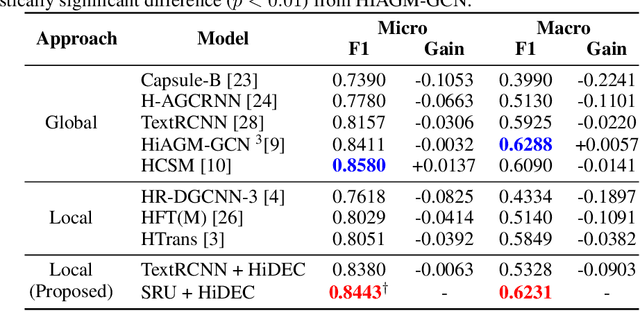
Hierarchical text classification (HTC) to a taxonomy is essential for various real applications butchallenging since HTC models often need to process a large volume of data that are severelyimbalanced and have hierarchy dependencies. Existing local and global approaches use deep learningto improve HTC by reducing the time complexity and incorporating the hierarchy dependencies.However, it is difficult to satisfy both conditions in a single HTC model. This paper proposes ahierarchy decoder (HiDEC) that uses recursive hierarchy decoding based on an encoder-decoderarchitecture. The key idea of the HiDEC involves decoding a context matrix into a sub-hierarchysequence using recursive hierarchy decoding, while staying aware of hierarchical dependenciesand level information. The HiDEC is a unified model that incorporates the benefits of existingapproaches, thereby alleviating the aforementioned difficulties without any trade-off. In addition, itcan be applied to both single- and multi-label classification with a minor modification. The superiorityof the proposed model was verified on two benchmark datasets (WOS-46985 and RCV1) with anexplanation of the reasons for its success