 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Super-Resolution Network for Single Image Super-Resolution with Realistic Degradations
Sep 09, 2019
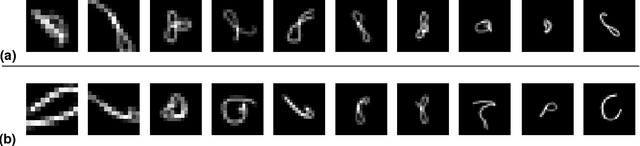
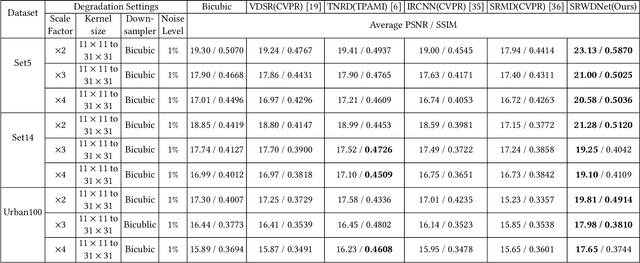

Single Image Super-Resolution (SISR) aims to generate a high-resolution (HR) image of a given low-resolution (LR) image. The most of existing convolutional neural network (CNN) based SISR methods usually take an assumption that a LR image is only bicubicly down-sampled version of an HR image. However, the true degradation (i.e. the LR image is a bicubicly downsampled, blurred and noisy version of an HR image) of a LR image goes beyond the widely used bicubic assumption, which makes the SISR problem highly ill-posed nature of inverse problems. To address this issue, we propose a deep SISR network that works for blur kernels of different sizes, and different noise levels in an unified residual CNN-based denoiser network, which significantly improves a practical CNN-based super-resolver for real applications. Extensive experimental results on synthetic LR datasets and real images demonstrate that our proposed method not only can produce better results on more realistic degradation but also computational efficient to practical SISR applications.
* 7 pages
Image anomaly detection with capsule networks and imbalanced datasets
Sep 06, 2019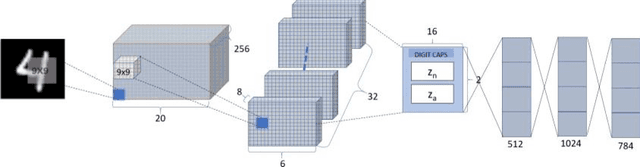

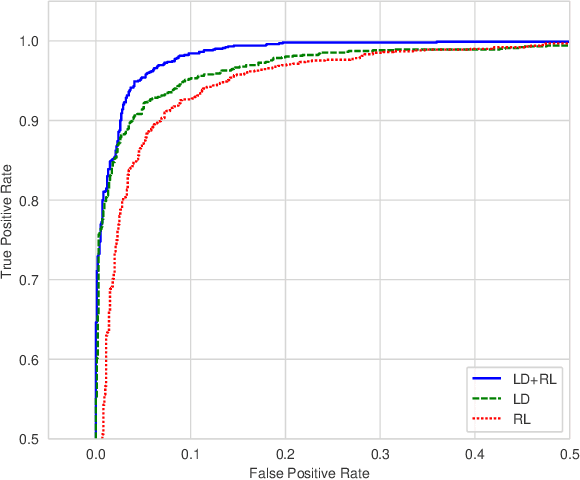
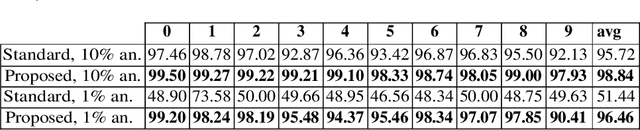
Image anomaly detection consists in finding images with anomalous, unusual patterns with respect to a set of normal data. Anomaly detection can be applied to several fields and has numerous practical applications, e.g. in industrial inspection, medical imaging, security enforcement, etc.. However, anomaly detection techniques often still rely on traditional approaches such as one-class Support Vector Machines, while the topic has not been fully developed yet in the context of modern deep learning approaches. In this paper, we propose an image anomaly detection system based on capsule networks under the assumption that anomalous data are available for training but their amount is scarce.
* Published in conference ICIAP 2019
Deep Temporal Analysis for Non-Acted Body Affect Recognition
Jul 23, 2019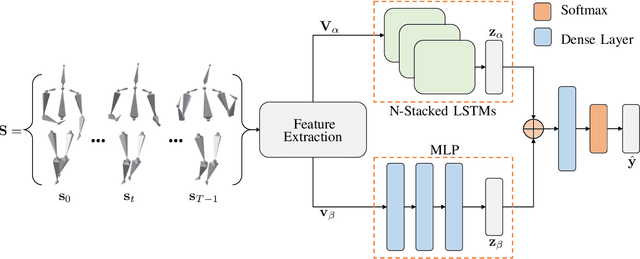
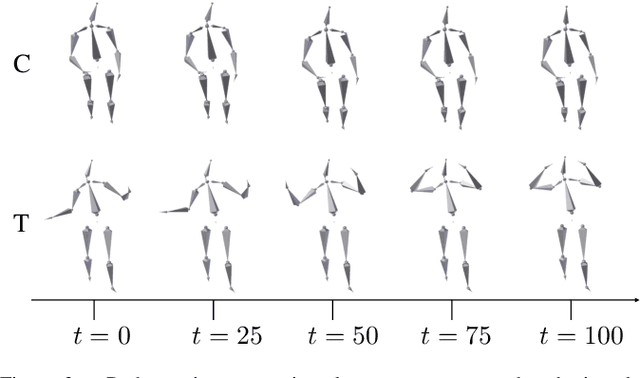
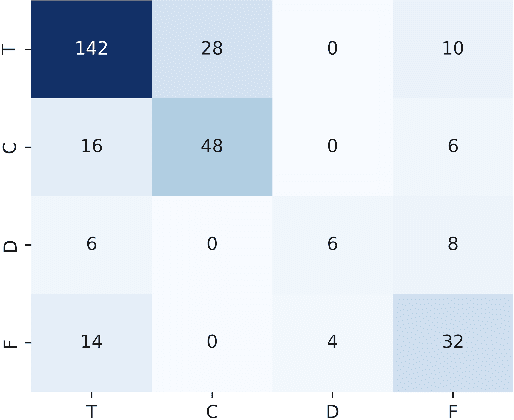
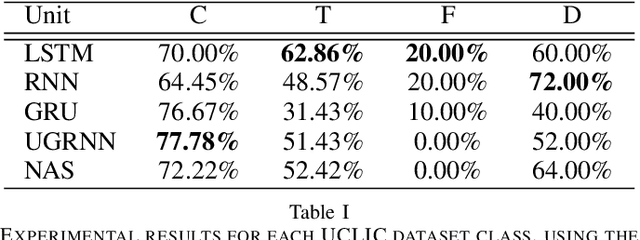
Affective computing is a field of great interest in many computer vision applications, including video surveillance, behaviour analysis, and human-robot interaction. Most of the existing literature has addressed this field by analysing different sets of face features. However, in the last decade, several studies have shown how body movements can play a key role even in emotion recognition. The majority of these experiments on the body are performed by trained actors whose aim is to simulate emotional reactions. These unnatural expressions differ from the more challenging genuine emotions, thus invalidating the obtained results. In this paper, a solution for basic non-acted emotion recognition based on 3D skeleton and Deep Neural Networks (DNNs) is provided. The proposed work introduces three majors contributions. First, unlike the current state-of-the-art in non-acted body affect recognition, where only static or global body features are considered, in this work also temporal local movements performed by subjects in each frame are examined. Second, an original set of global and time-dependent features for body movement description is provided. Third, to the best of out knowledge, this is the first attempt to use deep learning methods for non-acted body affect recognition. Due to the novelty of the topic, only the UCLIC dataset is currently considered the benchmark for comparative tests. On the latter, the proposed method outperforms all the competitors.
Exploiting Recurrent Neural Networks and Leap Motion Controller for Sign Language and Semaphoric Gesture Recognition
Mar 28, 2018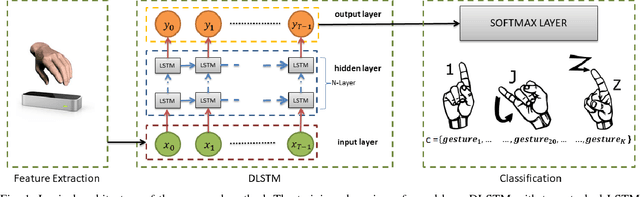
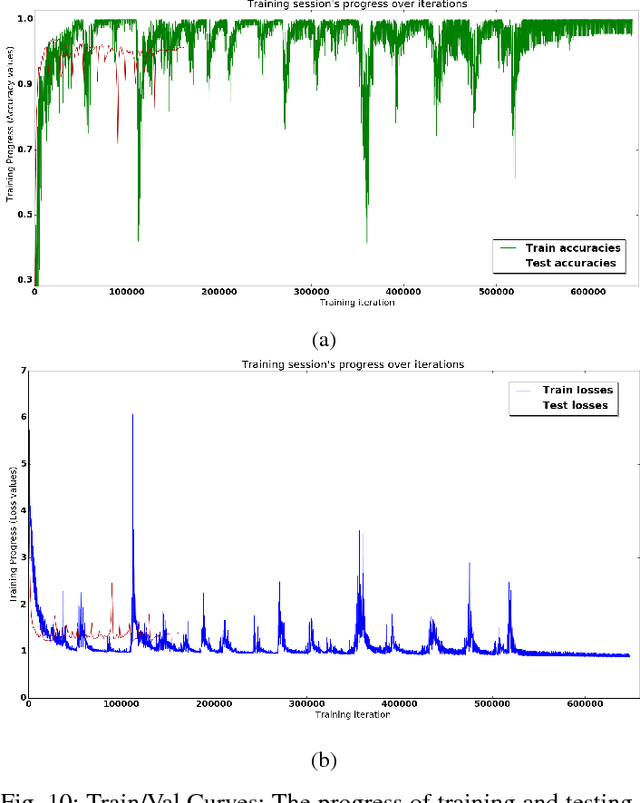
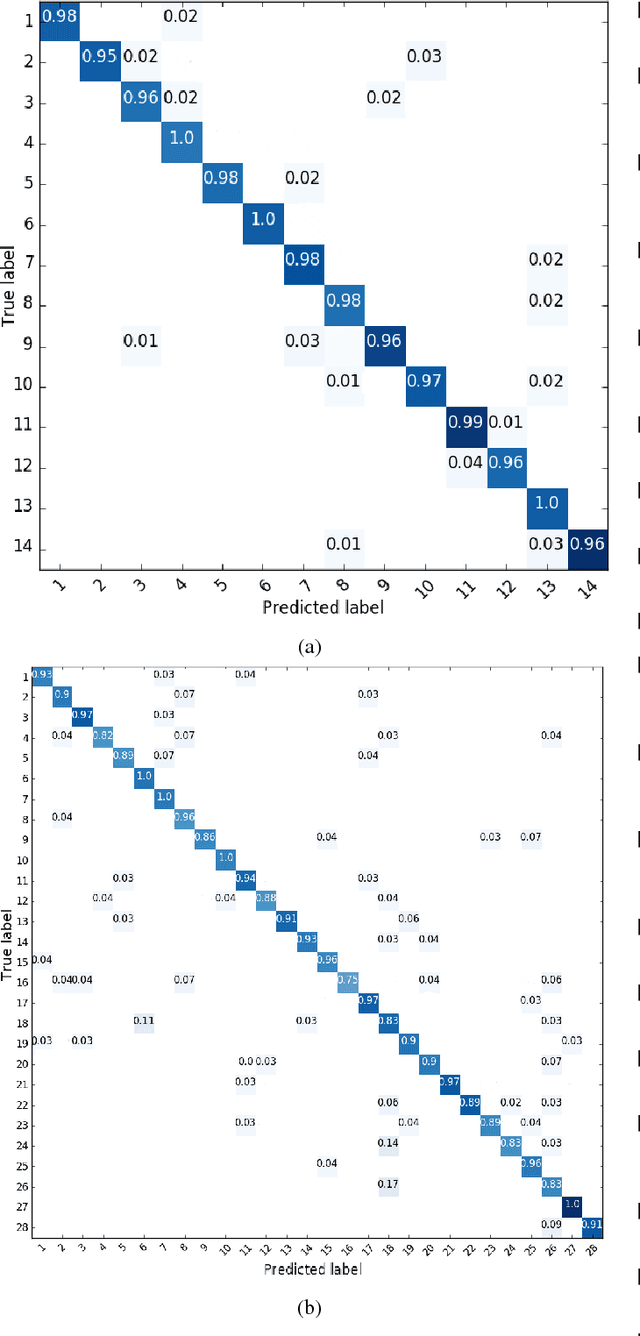
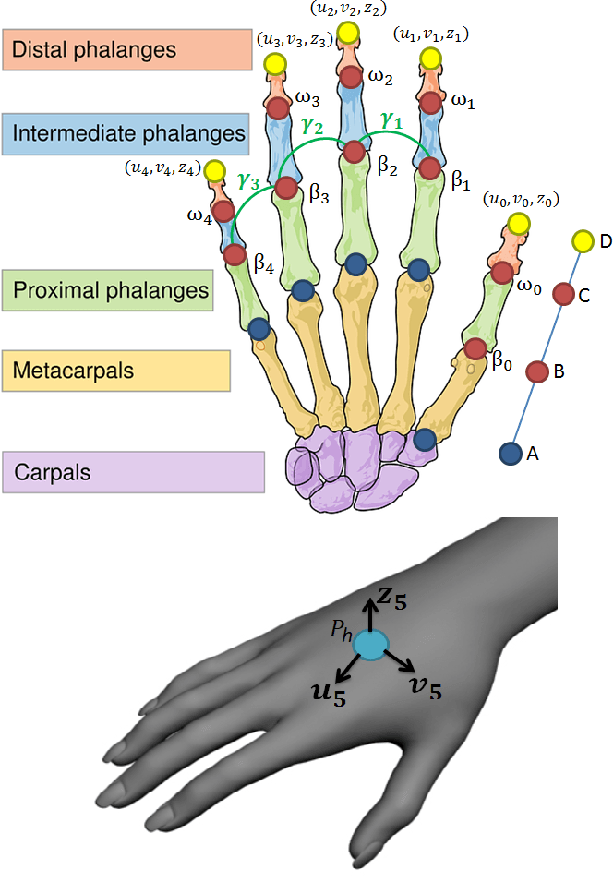
In human interactions, hands are a powerful way of expressing information that, in some cases, can be used as a valid substitute for voice, as it happens in Sign Language. Hand gesture recognition has always been an interesting topic in the areas of computer vision and multimedia. These gestures can be represented as sets of feature vectors that change over time. Recurrent Neural Networks (RNNs) are suited to analyse this type of sets thanks to their ability to model the long term contextual information of temporal sequences. In this paper, a RNN is trained by using as features the angles formed by the finger bones of human hands. The selected features, acquired by a Leap Motion Controller (LMC) sensor, have been chosen because the majority of human gestures produce joint movements that generate truly characteristic corners. A challenging subset composed by a large number of gestures defined by the American Sign Language (ASL) is used to test the proposed solution and the effectiveness of the selected angles. Moreover, the proposed method has been compared to other state of the art works on the SHREC dataset, thus demonstrating its superiority in hand gesture recognition accuracy.
Group Re-Identification via Unsupervised Transfer of Sparse Features Encoding
Jul 28, 2017
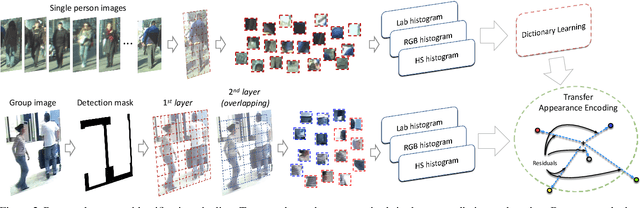
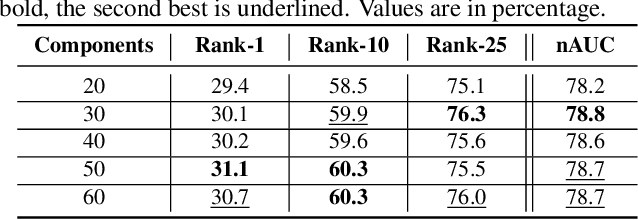
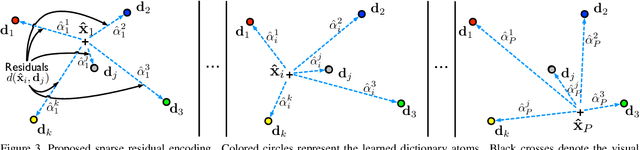
Person re-identification is best known as the problem of associating a single person that is observed from one or more disjoint cameras. The existing literature has mainly addressed such an issue, neglecting the fact that people usually move in groups, like in crowded scenarios. We believe that the additional information carried by neighboring individuals provides a relevant visual context that can be exploited to obtain a more robust match of single persons within the group. Despite this, re-identifying groups of people compound the common single person re-identification problems by introducing changes in the relative position of persons within the group and severe self-occlusions. In this paper, we propose a solution for group re-identification that grounds on transferring knowledge from single person re-identification to group re-identification by exploiting sparse dictionary learning. First, a dictionary of sparse atoms is learned using patches extracted from single person images. Then, the learned dictionary is exploited to obtain a sparsity-driven residual group representation, which is finally matched to perform the re-identification. Extensive experiments on the i-LIDS groups and two newly collected datasets show that the proposed solution outperforms state-of-the-art approaches.
The UMCD Dataset
Apr 05, 2017



In recent years, the technological improvements of low-cost small-scale Unmanned Aerial Vehicles (UAVs) are promoting an ever-increasing use of them in different tasks. In particular, the use of small-scale UAVs is useful in all these low-altitude tasks in which common UAVs cannot be adopted, such as recurrent comprehensive view of wide environments, frequent monitoring of military areas, real-time classification of static and moving entities (e.g., people, cars, etc.). These tasks can be supported by mosaicking and change detection algorithms achieved at low-altitude. Currently, public datasets for testing these algorithms are not available. This paper presents the UMCD dataset, the first collection of geo-referenced video sequences acquired at low-altitude for mosaicking and change detection purposes. Five reference scenarios are also reported.
Wide-Slice Residual Networks for Food Recognition
Dec 20, 2016
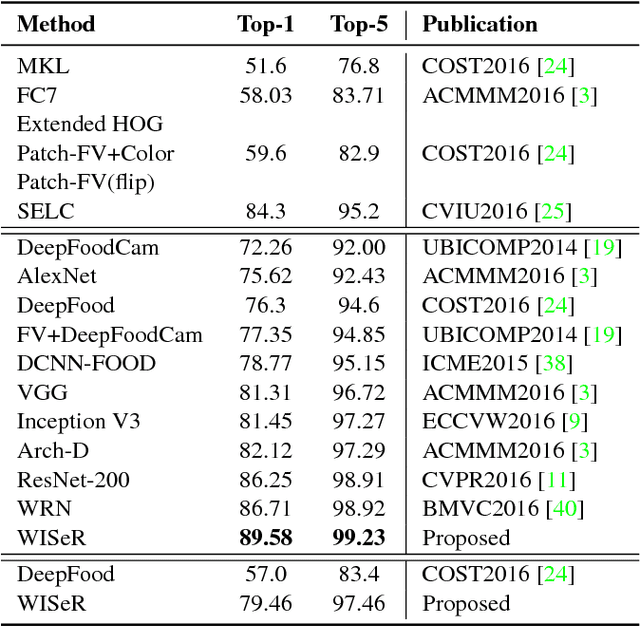
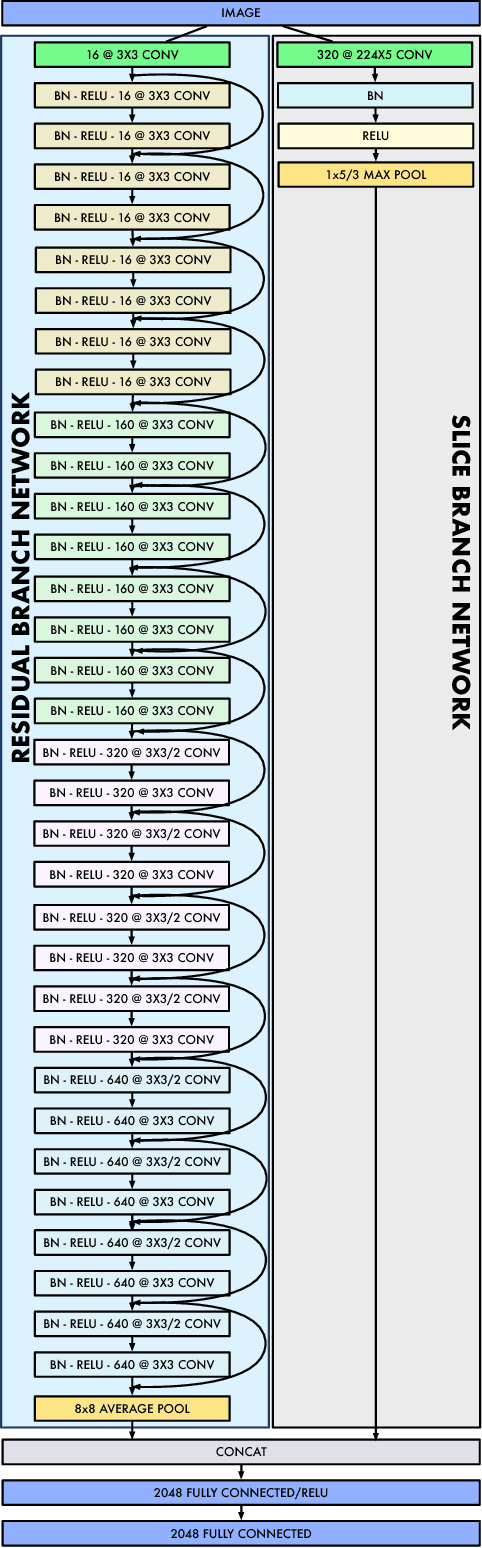
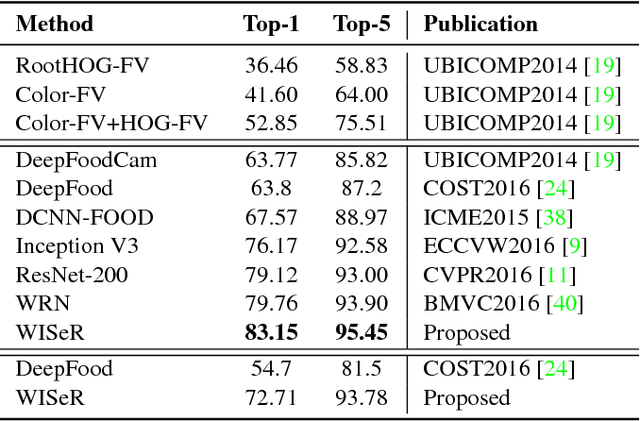
Food diary applications represent a tantalizing market. Such applications, based on image food recognition, opened to new challenges for computer vision and pattern recognition algorithms. Recent works in the field are focusing either on hand-crafted representations or on learning these by exploiting deep neural networks. Despite the success of such a last family of works, these generally exploit off-the shelf deep architectures to classify food dishes. Thus, the architectures are not cast to the specific problem. We believe that better results can be obtained if the deep architecture is defined with respect to an analysis of the food composition. Following such an intuition, this work introduces a new deep scheme that is designed to handle the food structure. Specifically, inspired by the recent success of residual deep network, we exploit such a learning scheme and introduce a slice convolution block to capture the vertical food layers. Outputs of the deep residual blocks are combined with the sliced convolution to produce the classification score for specific food categories. To evaluate our proposed architecture we have conducted experimental results on three benchmark datasets. Results demonstrate that our solution shows better performance with respect to existing approaches (e.g., a top-1 accuracy of 90.27% on the Food-101 challenging dataset).