 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Policy Distillation
Jul 21, 2024We introduce Proximal Policy Distillation (PPD), a novel policy distillation method that integrates student-driven distillation and Proximal Policy Optimization (PPO) to increase sample efficiency and to leverage the additional rewards that the student policy collects during distillation. To assess the efficacy of our method, we compare PPD with two common alternatives, student-distill and teacher-distill, over a wide range of reinforcement learning environments that include discrete actions and continuous control (ATARI, Mujoco, and Procgen). For each environment and method, we perform distillation to a set of target student neural networks that are smaller, identical (self-distillation), or larger than the teacher network. Our findings indicate that PPD improves sample efficiency and produces better student policies compared to typical policy distillation approaches. Moreover, PPD demonstrates greater robustness than alternative methods when distilling policies from imperfect demonstrations. The code for the paper is released as part of a new Python library built on top of stable-baselines3 to facilitate policy distillation: `sb3-distill'.
Learning secondary tool affordances of human partners using iCub robot's egocentric data
Jul 16, 2024



Objects, in particular tools, provide several action possibilities to the agents that can act on them, which are generally associated with the term of affordances. A tool is typically designed for a specific purpose, such as driving a nail in the case of a hammer, which we call as the primary affordance. A tool can also be used beyond its primary purpose, in which case we can associate this auxiliary use with the term secondary affordance. Previous work on affordance perception and learning has been mostly focused on primary affordances. Here, we address the less explored problem of learning the secondary tool affordances of human partners. To do this, we use the iCub robot to observe human partners with three cameras while they perform actions on twenty objects using four different tools. In our experiments, human partners utilize tools to perform actions that do not correspond to their primary affordances. For example, the iCub robot observes a human partner using a ruler for pushing, pulling, and moving objects instead of measuring their lengths. In this setting, we constructed a dataset by taking images of objects before and after each action is executed. We then model learning secondary affordances by training three neural networks (ResNet-18, ResNet-50, and ResNet-101) each on three tasks, using raw images showing the `initial' and `final' position of objects as input: (1) predicting the tool used to move an object, (2) predicting the tool used with an additional categorical input that encoded the action performed, and (3) joint prediction of both tool used and action performed. Our results indicate that deep learning architectures enable the iCub robot to predict secondary tool affordances, thereby paving the road for human-robot collaborative object manipulation involving complex affordances.
Imitation of human motion achieves natural head movements for humanoid robots in an active-speaker detection task
Jul 16, 2024Head movements are crucial for social human-human interaction. They can transmit important cues (e.g., joint attention, speaker detection) that cannot be achieved with verbal interaction alone. This advantage also holds for human-robot interaction. Even though modeling human motions through generative AI models has become an active research area within robotics in recent years, the use of these methods for producing head movements in human-robot interaction remains underexplored. In this work, we employed a generative AI pipeline to produce human-like head movements for a Nao humanoid robot. In addition, we tested the system on a real-time active-speaker tracking task in a group conversation setting. Overall, the results show that the Nao robot successfully imitates human head movements in a natural manner while actively tracking the speakers during the conversation. Code and data from this study are available at https://github.com/dingdingding60/Humanoids2024HRI
Investigating Trade-offs in Utility, Fairness and Differential Privacy in Neural Networks
Feb 11, 2021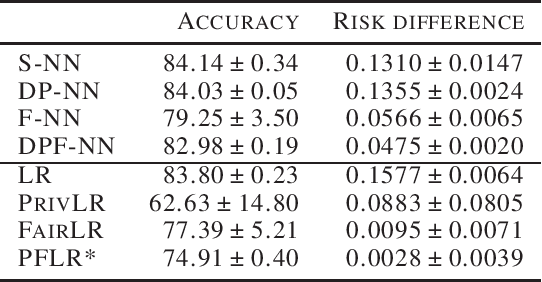
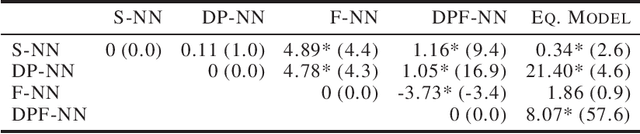

To enable an ethical and legal use of machine learning algorithms, they must both be fair and protect the privacy of those whose data are being used. However, implementing privacy and fairness constraints might come at the cost of utility (Jayaraman & Evans, 2019; Gong et al., 2020). This paper investigates the privacy-utility-fairness trade-off in neural networks by comparing a Simple (S-NN), a Fair (F-NN), a Differentially Private (DP-NN), and a Differentially Private and Fair Neural Network (DPF-NN) to evaluate differences in performance on metrics for privacy (epsilon, delta), fairness (risk difference), and utility (accuracy). In the scenario with the highest considered privacy guarantees (epsilon = 0.1, delta = 0.00001), the DPF-NN was found to achieve better risk difference than all the other neural networks with only a marginally lower accuracy than the S-NN and DP-NN. This model is considered fair as it achieved a risk difference below the strict (0.05) and lenient (0.1) thresholds. However, while the accuracy of the proposed model improved on previous work from Xu, Yuan and Wu (2019), the risk difference was found to be worse.
Flatland-RL : Multi-Agent Reinforcement Learning on Trains
Dec 11, 2020
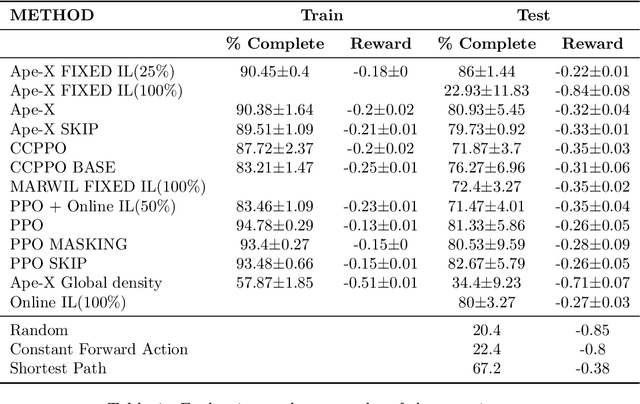
Efficient automated scheduling of trains remains a major challenge for modern railway systems. The underlying vehicle rescheduling problem (VRSP) has been a major focus of Operations Research (OR) since decades. Traditional approaches use complex simulators to study VRSP, where experimenting with a broad range of novel ideas is time consuming and has a huge computational overhead. In this paper, we introduce a two-dimensional simplified grid environment called "Flatland" that allows for faster experimentation. Flatland does not only reduce the complexity of the full physical simulation, but also provides an easy-to-use interface to test novel approaches for the VRSP, such as Reinforcement Learning (RL) and Imitation Learning (IL). In order to probe the potential of Machine Learning (ML) research on Flatland, we (1) ran a first series of RL and IL experiments and (2) design and executed a public Benchmark at NeurIPS 2020 to engage a large community of researchers to work on this problem. Our own experimental results, on the one hand, demonstrate that ML has potential in solving the VRSP on Flatland. On the other hand, we identify key topics that need further research. Overall, the Flatland environment has proven to be a robust and valuable framework to investigate the VRSP for railway networks. Our experiments provide a good starting point for further research and for the participants of the NeurIPS 2020 Flatland Benchmark. All of these efforts together have the potential to have a substantial impact on shaping the mobility of the future.
Meta-learnt priors slow down catastrophic forgetting in neural networks
Sep 09, 2019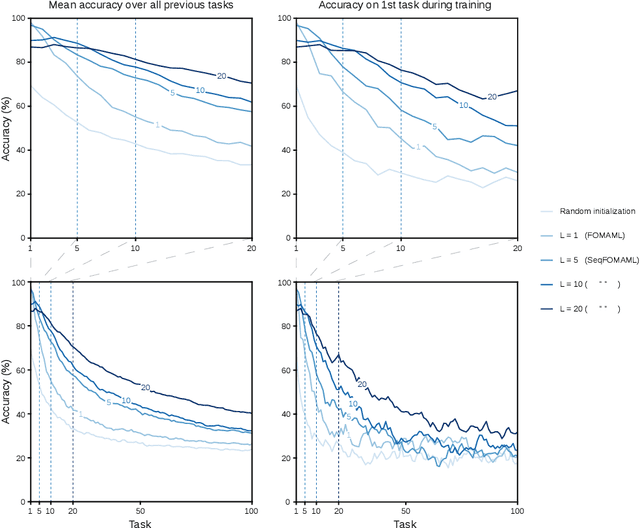
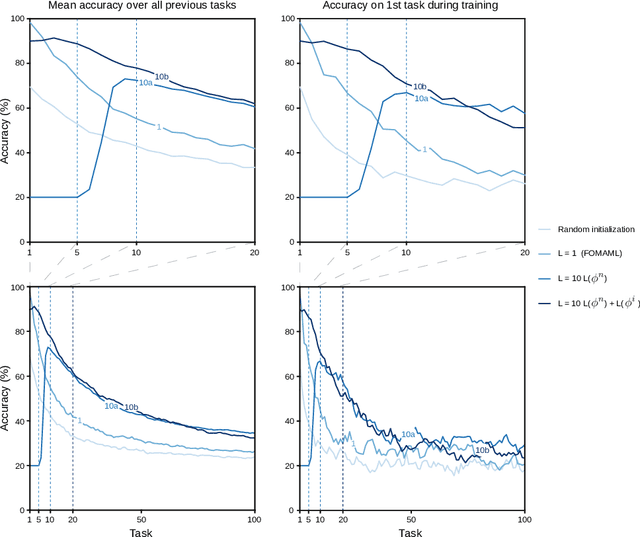
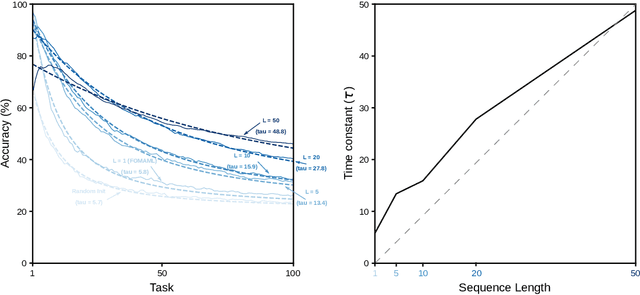
Current training regimes for deep learning usually involve exposure to a single task / dataset at a time. Here we start from the observation that in this context the trained model is not given any knowledge of anything outside its (single) training distribution, and has thus no way to learn parameters (i.e., feature detectors or policies) that could be helpful to solve other tasks, and to limit future interference on the acquired knowledge, and thus catastrophic forgetting. Here we show that catastrophic forgetting can be mitigated in a meta-learning context, by exposing a neural network to multiple tasks in a sequential manner during training. Finally, we present SeqFOMAML, a meta-learning algorithm that implements these principles, and we evaluate it on a sequential learning problem composed by Omniglot classification tasks.
Denoising Autoencoders for Overgeneralization in Neural Networks
Oct 23, 2018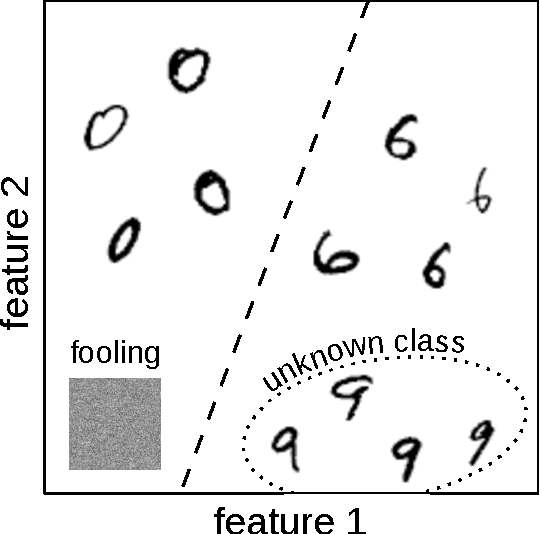
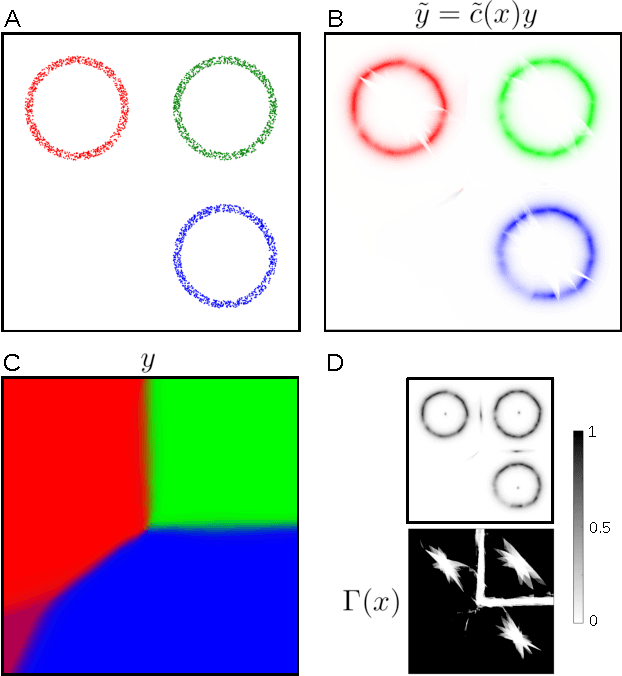

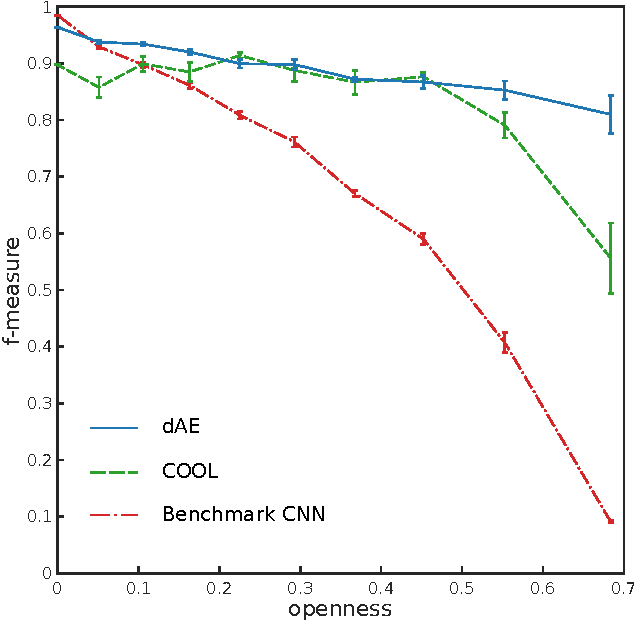
Despite the recent developments that allowed neural networks to achieve impressive performance on a variety of applications, these models are intrinsically affected by the problem of overgeneralization, due to their partitioning of the full input space into the fixed set of target classes used during training. Thus it is possible for novel inputs belonging to categories unknown during training or even completely unrecognizable to humans to fool the system into classifying them as one of the known classes, even with a high degree of confidence. Solving this problem may help improve the security of such systems in critical applications, and may further lead to applications in the context of open set recognition and 1-class recognition. This paper presents a novel way to compute a confidence score using denoising autoencoders and shows that such confidence score can correctly identify the regions of the input space close to the training distribution by approximately identifying its local maxima.
The Temporal Singularity: time-accelerated simulated civilizations and their implications
Jun 22, 2018Provided significant future progress in artificial intelligence and computing, it may ultimately be possible to create multiple Artificial General Intelligences (AGIs), and possibly entire societies living within simulated environments. In that case, it should be possible to improve the problem solving capabilities of the system by increasing the speed of the simulation. If a minimal simulation with sufficient capabilities is created, it might manage to increase its own speed by accelerating progress in science and technology, in a way similar to the Technological Singularity. This may ultimately lead to large simulated civilizations unfolding at extreme temporal speedups, achieving what from the outside would look like a Temporal Singularity. Here we discuss the feasibility of the minimal simulation and the potential advantages, dangers, and connection to the Fermi paradox of the Temporal Singularity. The medium-term importance of the topic derives from the amount of computational power required to start the process, which could be available within the next decades, making the Temporal Singularity theoretically possible before the end of the century.