 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParalESN: Enabling parallel information processing in Reservoir Computing
Jan 29, 2026Reservoir Computing (RC) has established itself as an efficient paradigm for temporal processing. However, its scalability remains severely constrained by (i) the necessity of processing temporal data sequentially and (ii) the prohibitive memory footprint of high-dimensional reservoirs. In this work, we revisit RC through the lens of structured operators and state space modeling to address these limitations, introducing Parallel Echo State Network (ParalESN). ParalESN enables the construction of high-dimensional and efficient reservoirs based on diagonal linear recurrence in the complex space, enabling parallel processing of temporal data. We provide a theoretical analysis demonstrating that ParalESN preserves the Echo State Property and the universality guarantees of traditional Echo State Networks while admitting an equivalent representation of arbitrary linear reservoirs in the complex diagonal form. Empirically, ParalESN matches the predictive accuracy of traditional RC on time series benchmarks, while delivering substantial computational savings. On 1-D pixel-level classification tasks, ParalESN achieves competitive accuracy with fully trainable neural networks while reducing computational costs and energy consumption by orders of magnitude. Overall, ParalESN offers a promising, scalable, and principled pathway for integrating RC within the deep learning landscape.
Mixture of Raytraced Experts
Jul 16, 2025
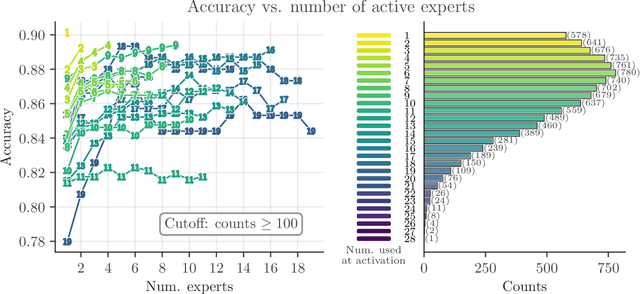

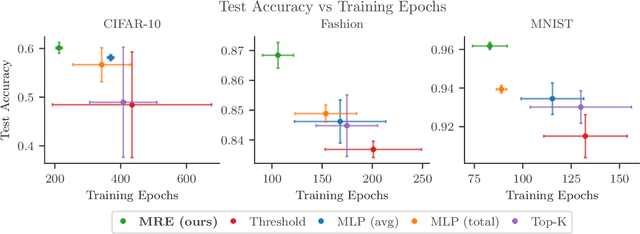
We introduce a Mixture of Raytraced Experts, a stacked Mixture of Experts (MoE) architecture which can dynamically select sequences of experts, producing computational graphs of variable width and depth. Existing MoE architectures generally require a fixed amount of computation for a given sample. Our approach, in contrast, yields predictions with increasing accuracy as the computation cycles through the experts' sequence. We train our model by iteratively sampling from a set of candidate experts, unfolding the sequence akin to how Recurrent Neural Networks are trained. Our method does not require load-balancing mechanisms, and preliminary experiments show a reduction in training epochs of 10\% to 40\% with a comparable/higher accuracy. These results point to new research directions in the field of MoEs, allowing the design of potentially faster and more expressive models. The code is available at https://github.com/nutig/RayTracing