 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Joint Training with Self-Attention Mechanism for Robust End-to-End Speech Recognition
Apr 03, 2021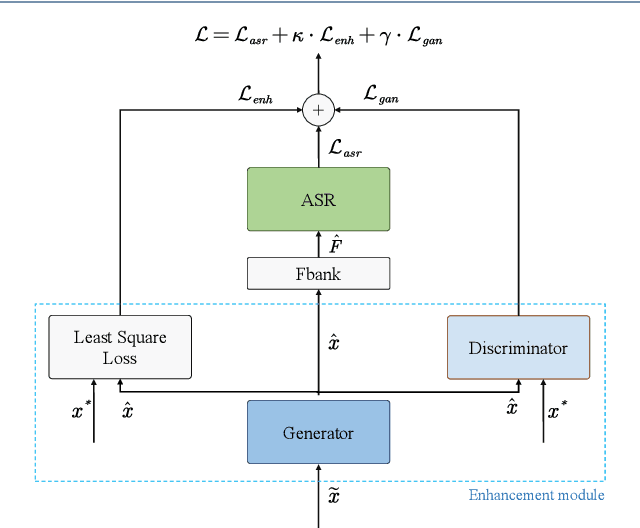

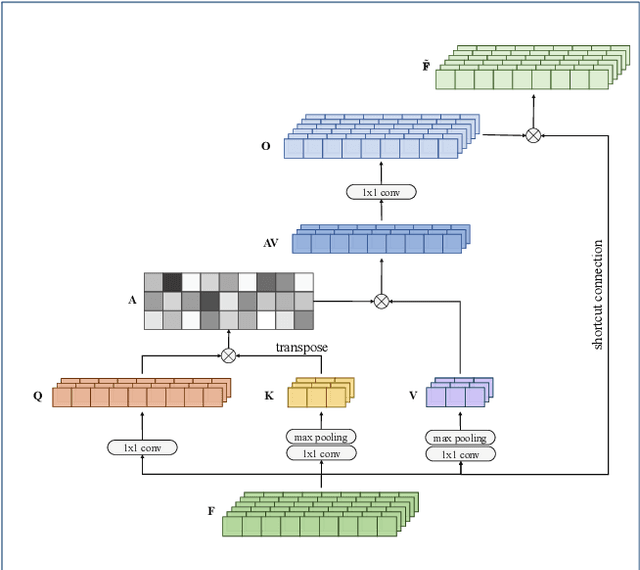
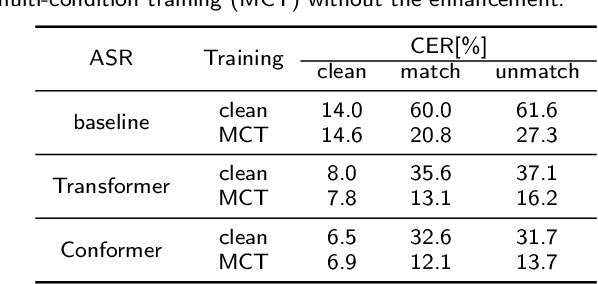
Lately, the self-attention mechanism has marked a new milestone in the field of automatic speech recognition (ASR). Nevertheless, its performance is susceptible to environmental intrusions as the system predicts the next output symbol depending on the full input sequence and the previous predictions. Inspired by the extensive applications of the generative adversarial networks (GANs) in speech enhancement and ASR tasks, we propose an adversarial joint training framework with the self-attention mechanism to boost the noise robustness of the ASR system. Generally, it consists of a self-attention speech enhancement GAN and a self-attention end-to-end ASR model. There are two highlights which are worth noting in this proposed framework. One is that it benefits from the advancement of both self-attention mechanism and GANs; while the other is that the discriminator of GAN plays the role of the global discriminant network in the stage of the adversarial joint training, which guides the enhancement front-end to capture more compatible structures for the subsequent ASR module and thereby offsets the limitation of the separate training and handcrafted loss functions. With the adversarial joint optimization, the proposed framework is expected to learn more robust representations suitable for the ASR task. We execute systematic experiments on the corpus AISHELL-1, and the experimental results show that on the artificial noisy test set, the proposed framework achieves the relative improvements of 66% compared to the ASR model trained by clean data solely, 35.1% compared to the speech enhancement & ASR scheme without joint training, and 5.3% compared to multi-condition training.
GaitGraph: Graph Convolutional Network for Skeleton-Based Gait Recognition
Jan 27, 2021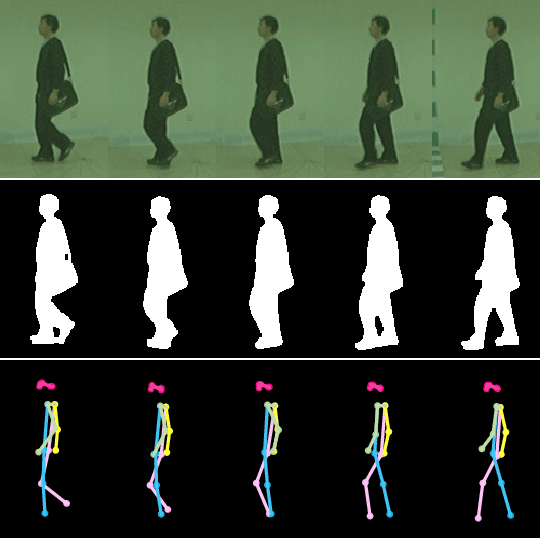
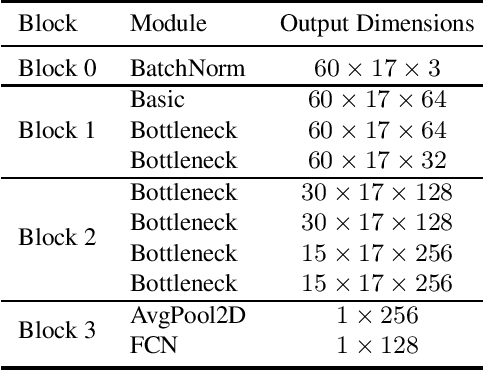
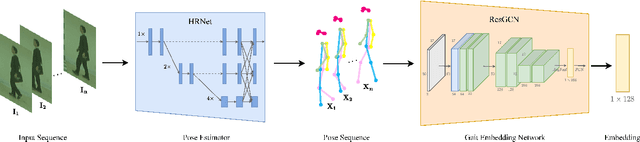
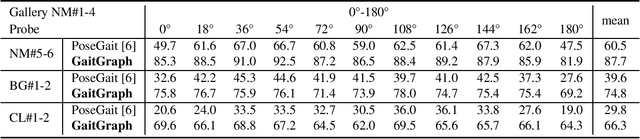
Gait recognition is a promising video-based biometric for identifying individual walking patterns from a long distance. At present, most gait recognition methods use silhouette images to represent a person in each frame. However, silhouette images can lose fine-grained spatial information, and most papers do not regard how to obtain these silhouettes in complex scenes. Furthermore, silhouette images contain not only gait features but also other visual clues that can be recognized. Hence these approaches can not be considered as strict gait recognition. We leverage recent advances in human pose estimation to estimate robust skeleton poses directly from RGB images to bring back model-based gait recognition with a cleaner representation of gait. Thus, we propose GaitGraph that combines skeleton poses with Graph Convolutional Network (GCN) to obtain a modern model-based approach for gait recognition. The main advantages are a cleaner, more elegant extraction of the gait features and the ability to incorporate powerful spatio-temporal modeling using GCN. Experiments on the popular CASIA-B gait dataset show that our method archives state-of-the-art performance in model-based gait recognition. The code and models are publicly available.
Lightweight Multi-Branch Network for Person Re-Identification
Jan 26, 2021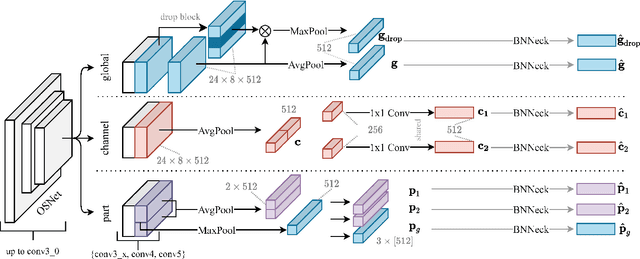
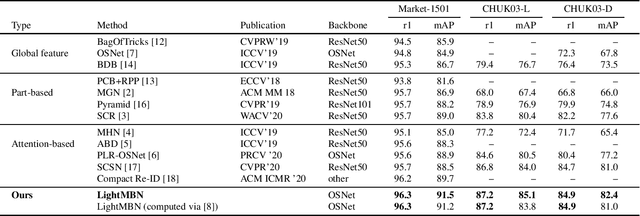
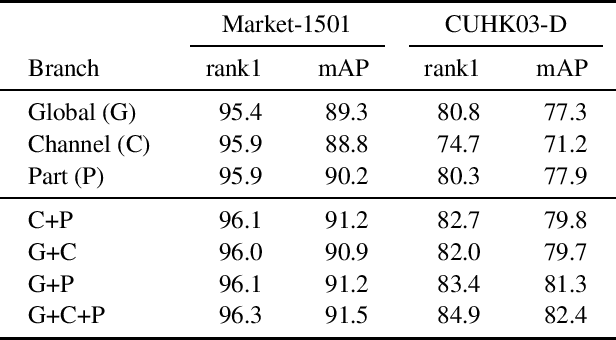
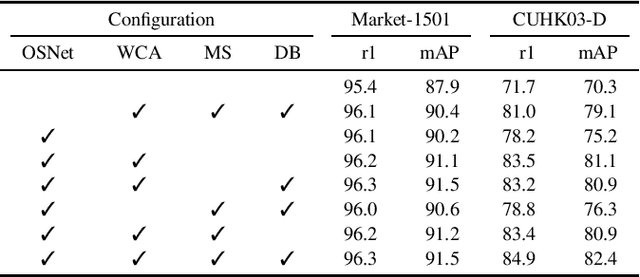
Person Re-Identification aims to retrieve person identities from images captured by multiple cameras or the same cameras in different time instances and locations. Because of its importance in many vision applications from surveillance to human-machine interaction, person re-identification methods need to be reliable and fast. While more and more deep architectures are proposed for increasing performance, those methods also increase overall model complexity. This paper proposes a lightweight network that combines global, part-based, and channel features in a unified multi-branch architecture that builds on the resource-efficient OSNet backbone. Using a well-founded combination of training techniques and design choices, our final model achieves state-of-the-art results on CUHK03 labeled, CUHK03 detected, and Market-1501 with 85.1% mAP / 87.2% rank1, 82.4% mAP / 84.9% rank1, and 91.5% mAP / 96.3% rank1, respectively.
Driver Anomaly Detection: A Dataset and Contrastive Learning Approach
Sep 30, 2020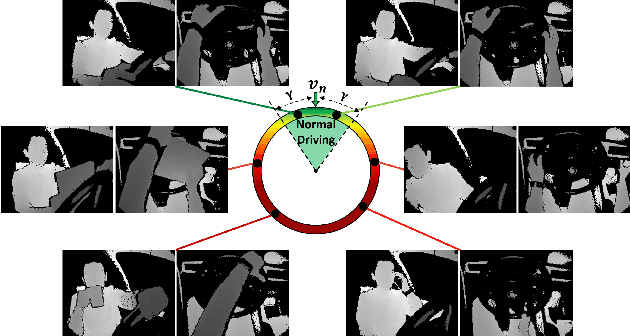



Distracted drivers are more likely to fail to anticipate hazards, which result in car accidents. Therefore, detecting anomalies in drivers' actions (i.e., any action deviating from normal driving) contains the utmost importance to reduce driver-related accidents. However, there are unbounded many anomalous actions that a driver can do while driving, which leads to an 'open set recognition' problem. Accordingly, instead of recognizing a set of anomalous actions that are commonly defined by previous dataset providers, in this work, we propose a contrastive learning approach to learn a metric to differentiate normal driving from anomalous driving. For this task, we introduce a new video-based benchmark, the Driver Anomaly Detection (DAD) dataset, which contains normal driving videos together with a set of anomalous actions in its training set. In the test set of the DAD dataset, there are unseen anomalous actions that still need to be winnowed out from normal driving. Our method reaches 0.9673 AUC on the test set, demonstrating the effectiveness of the contrastive learning approach on the anomaly detection task. Our dataset, codes and pre-trained models are publicly available.
Dissected 3D CNNs: Temporal Skip Connections for Efficient Online Video Processing
Sep 30, 2020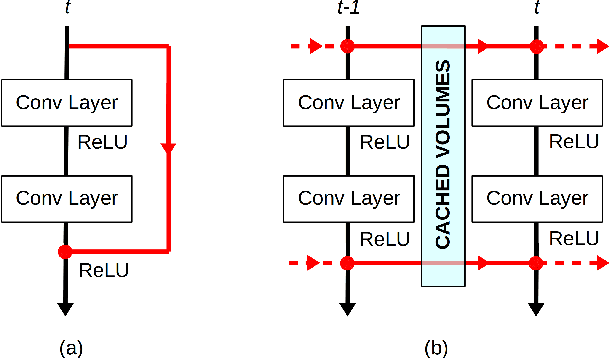
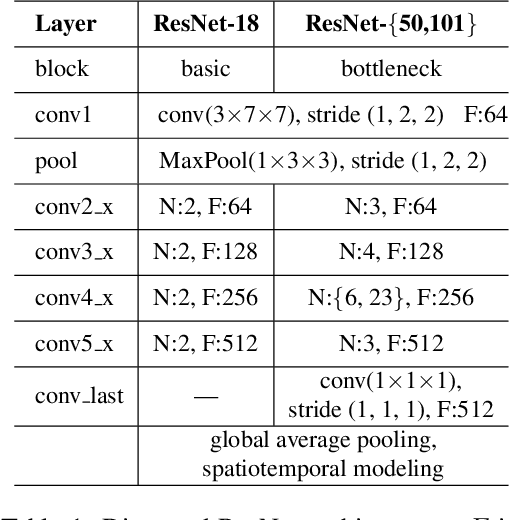
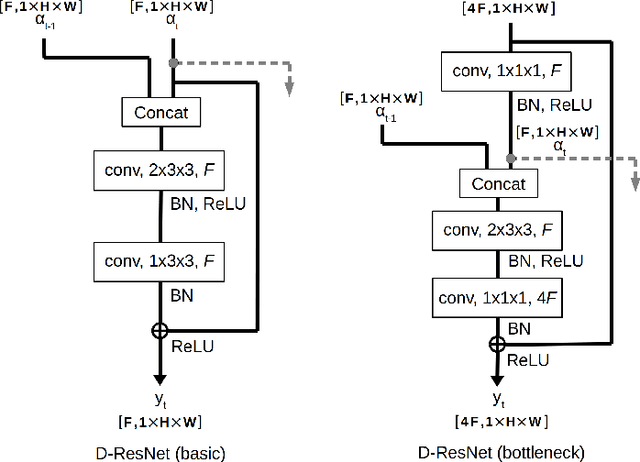

Convolutional Neural Networks with 3D kernels (3D CNNs) currently achieve state-of-the-art results in video recognition tasks due to their supremacy in extracting spatiotemporal features within video frames. There have been many successful 3D CNN architectures surpassing the state-of-the-art results successively. However, nearly all of them are designed to operate offline creating several serious handicaps during online operation. Firstly, conventional 3D CNNs are not dynamic since their output features represent the complete input clip instead of the most recent frame in the clip. Secondly, they are not temporal resolution-preserving due to their inherent temporal downsampling. Lastly, 3D CNNs are constrained to be used with fixed temporal input size limiting their flexibility. In order to address these drawbacks, we propose dissected 3D CNNs, where the intermediate volumes of the network are dissected and propagated over depth (time) dimension for future calculations, substantially reducing the number of computations at online operation. For action classification, the dissected version of ResNet models performs 74-90% fewer computations at online operation while achieving $\sim$5% better classification accuracy on the Kinetics-600 dataset than conventional 3D ResNet models. Moreover, the advantages of dissected 3D CNNs are demonstrated by deploying our approach onto several vision tasks, which consistently improved the performance.
Regularized Forward-Backward Decoder for Attention Models
Jun 15, 2020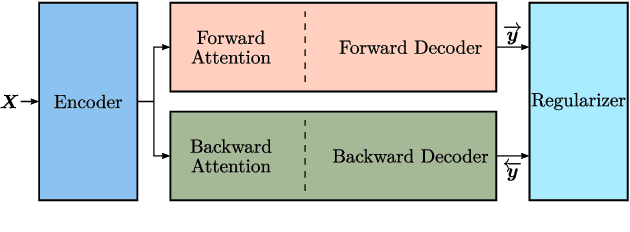
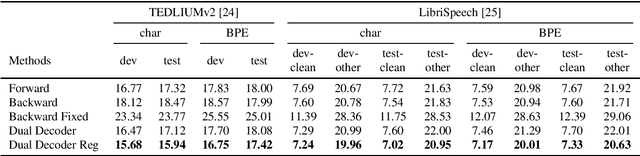
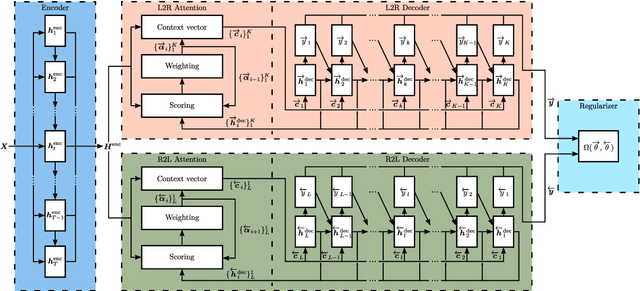
Nowadays, attention models are one of the popular candidates for speech recognition. So far, many studies mainly focus on the encoder structure or the attention module to enhance the performance of these models. However, mostly ignore the decoder. In this paper, we propose a novel regularization technique incorporating a second decoder during the training phase. This decoder is optimized on time-reversed target labels beforehand and supports the standard decoder during training by adding knowledge from future context. Since it is only added during training, we are not changing the basic structure of the network or adding complexity during decoding. We evaluate our approach on the smaller TEDLIUMv2 and the larger LibriSpeech dataset, achieving consistent improvements on both of them.
A Multi-Task Comparator Framework for Kinship Verification
Jun 02, 2020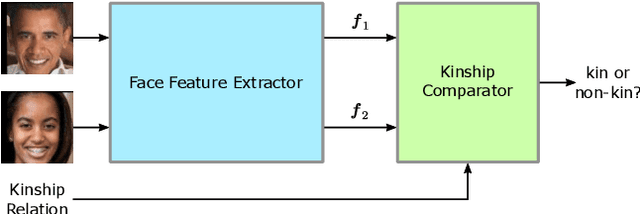
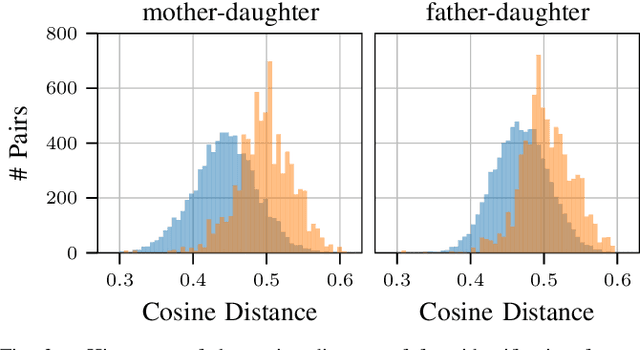
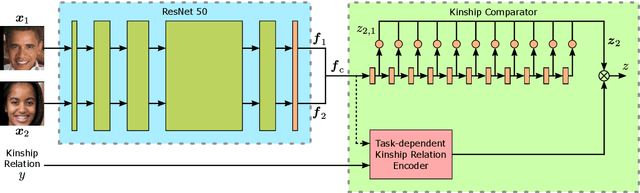
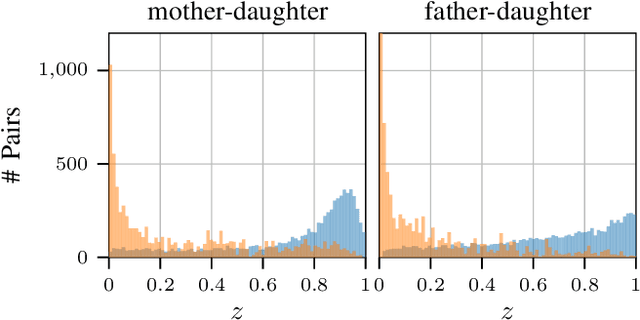
Approaches for kinship verification often rely on cosine distances between face identification features. However, due to gender bias inherent in these features, it is hard to reliably predict whether two opposite-gender pairs are related. Instead of fine tuning the feature extractor network on kinship verification, we propose a comparator network to cope with this bias. After concatenating both features, cascaded local expert networks extract the information most relevant for their corresponding kinship relation. We demonstrate that our framework is robust against this gender bias and achieves comparable results on two tracks of the RFIW Challenge 2020. Moreover, we show how our framework can be further extended to handle partially known or unknown kinship relations.
DriverMHG: A Multi-Modal Dataset for Dynamic Recognition of Driver Micro Hand Gestures and a Real-Time Recognition Framework
Mar 02, 2020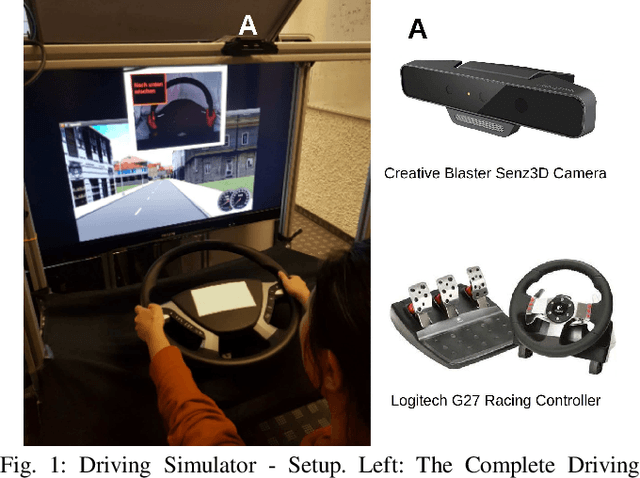

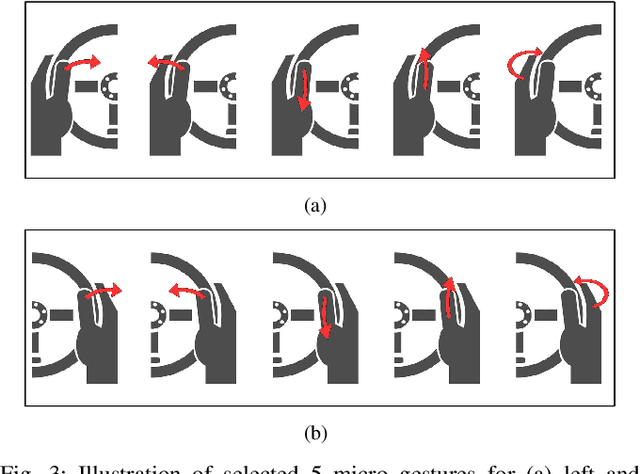
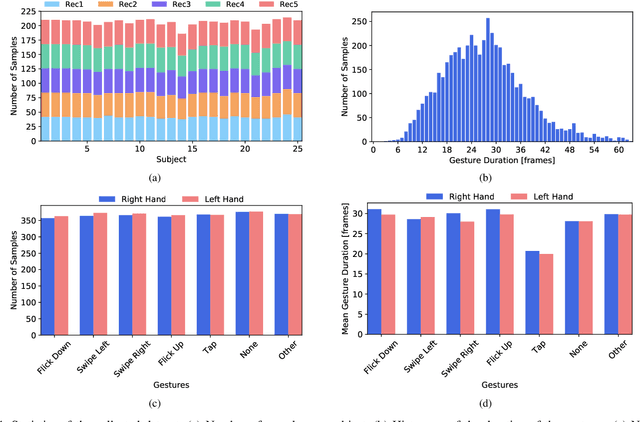
The use of hand gestures provides a natural alternative to cumbersome interface devices for Human-Computer Interaction (HCI) systems. However, real-time recognition of dynamic micro hand gestures from video streams is challenging for in-vehicle scenarios since (i) the gestures should be performed naturally without distracting the driver, (ii) micro hand gestures occur within very short time intervals at spatially constrained areas, (iii) the performed gesture should be recognized only once, and (iv) the entire architecture should be designed lightweight as it will be deployed to an embedded system. In this work, we propose an HCI system for dynamic recognition of driver micro hand gestures, which can have a crucial impact in automotive sector especially for safety related issues. For this purpose, we initially collected a dataset named Driver Micro Hand Gestures (DriverMHG), which consists of RGB, depth and infrared modalities. The challenges for dynamic recognition of micro hand gestures have been addressed by proposing a lightweight convolutional neural network (CNN) based architecture which operates online efficiently with a sliding window approach. For the CNN model, several 3-dimensional resource efficient networks are applied and their performances are analyzed. Online recognition of gestures has been performed with 3D-MobileNetV2, which provided the best offline accuracy among the applied networks with similar computational complexities. The final architecture is deployed on a driver simulator operating in real-time. We make DriverMHG dataset and our source code publicly available.
Deep Attention Based Semi-Supervised 2D-Pose Estimation for Surgical Instruments
Dec 10, 2019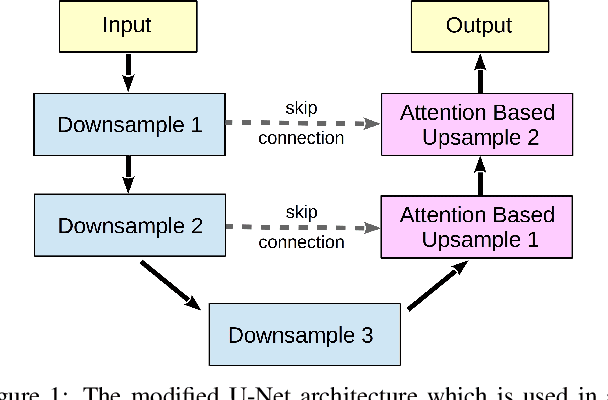
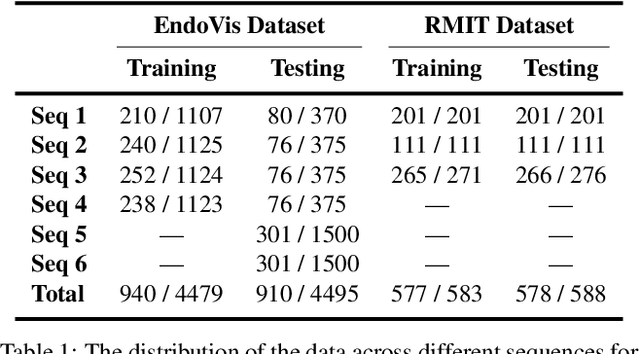
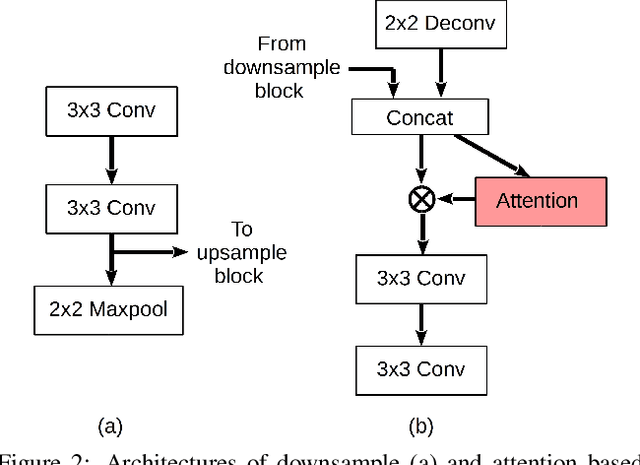
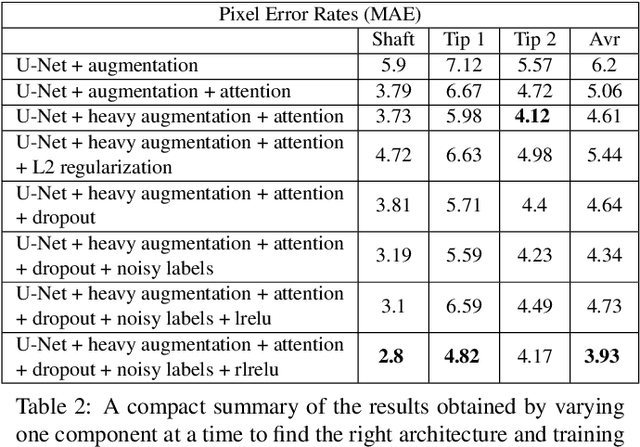
For many practical problems and applications, it is not feasible to create a vast and accurately labeled dataset, which restricts the application of deep learning in many areas. Semi-supervised learning algorithms intend to improve performance by also leveraging unlabeled data. This is very valuable for 2D-pose estimation task where data labeling requires substantial time and is subject to noise. This work aims to investigate if semi-supervised learning techniques can achieve acceptable performance level that makes using these algorithms during training justifiable. To this end, a lightweight network architecture is introduced and mean teacher, virtual adversarial training and pseudo-labeling algorithms are evaluated on 2D-pose estimation for surgical instruments. For the applicability of pseudo-labelling algorithm, we propose a novel confidence measure, total variation. Experimental results show that utilization of semi-supervised learning improves the performance on unseen geometries drastically while maintaining high accuracy for seen geometries. For RMIT benchmark, our lightweight architecture outperforms state-of-the-art with supervised learning. For Endovis benchmark, pseudo-labelling algorithm improves the supervised baseline achieving the new state-of-the-art performance.
You Only Watch Once: A Unified CNN Architecture for Real-Time Spatiotemporal Action Localization
Nov 15, 2019
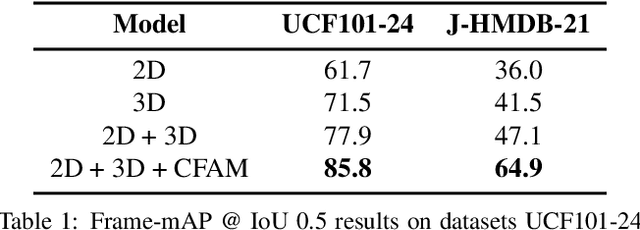
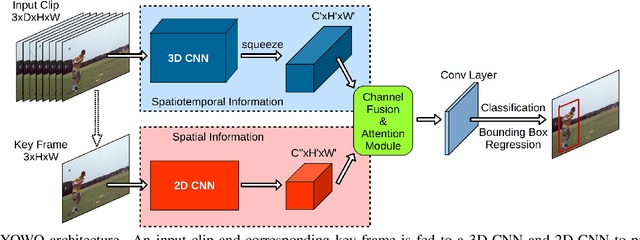
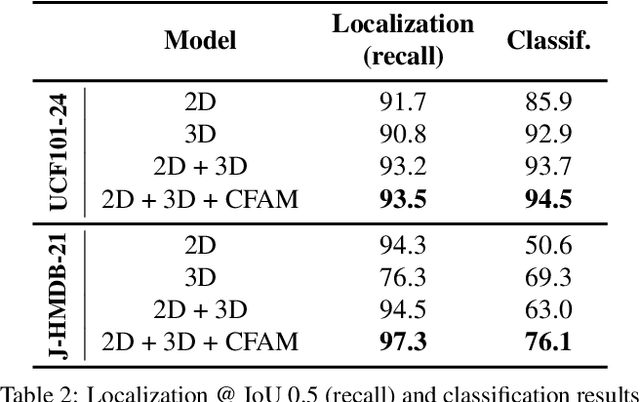
Spatiotemporal action localization requires incorporation of two sources of information into the designed architecture: (1) Temporal information from the previous frames and (2) spatial information from the key frame. Current state-of-the-art approaches usually extract these information with separate networks and use an extra mechanism for fusion to get detections. In this work, we present YOWO, a unified CNN architecture for real-time spatiotemporal action localization in video stream. YOWO makes use of a single neural network to extract temporal and spatial information concurrently and predict bounding boxes and action probabilities directly from video clips in one evaluation. Since the whole architecture is unified, it can be optimized end-to-end. The YOWO architecture is fast providing 34 frames-per-second on 16-frames input clips and 62 frames-per-second on 8-frames input clips. Remarkably, YOWO outperforms the previous state-of-the art results on J-HMDB-21 (71.1%) and UCF101-24 (75.0%) with 74.4% and 87.2% frame-mAP, respectively.