 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Caching with Space-Time Popularity Dynamics
May 19, 2020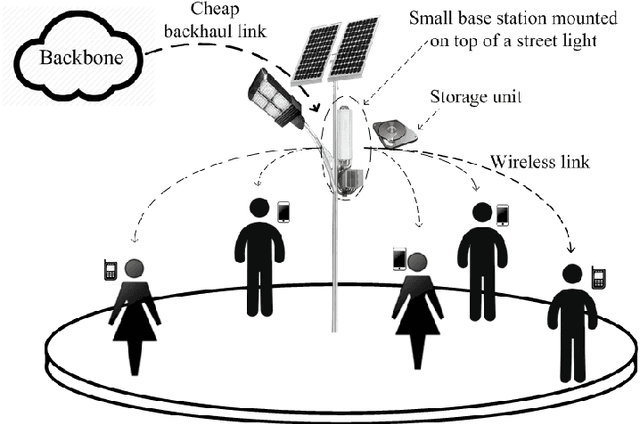
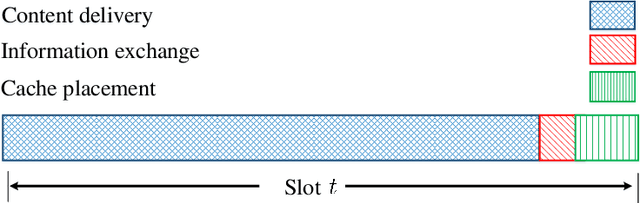
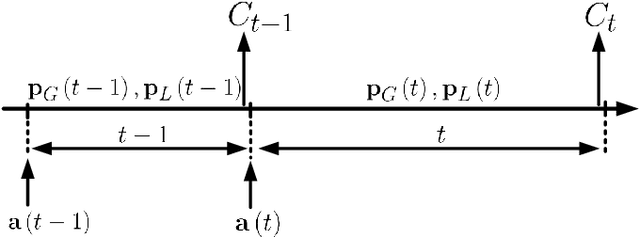
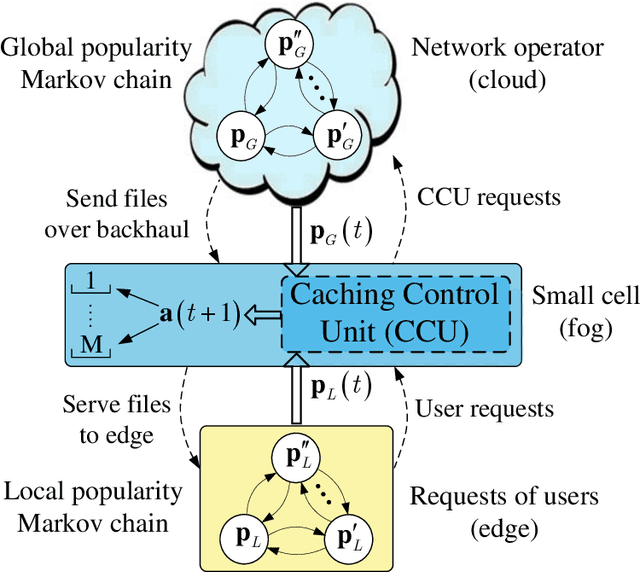
With the tremendous growth of data traffic over wired and wireless networks along with the increasing number of rich-media applications, caching is envisioned to play a critical role in next-generation networks. To intelligently prefetch and store contents, a cache node should be able to learn what and when to cache. Considering the geographical and temporal content popularity dynamics, the limited available storage at cache nodes, as well as the interactive in uence of caching decisions in networked caching settings, developing effective caching policies is practically challenging. In response to these challenges, this chapter presents a versatile reinforcement learning based approach for near-optimal caching policy design, in both single-node and network caching settings under dynamic space-time popularities. The herein presented policies are complemented using a set of numerical tests, which showcase the merits of the presented approach relative to several standard caching policies.
Tensor Graph Convolutional Networks for Multi-relational and Robust Learning
Mar 15, 2020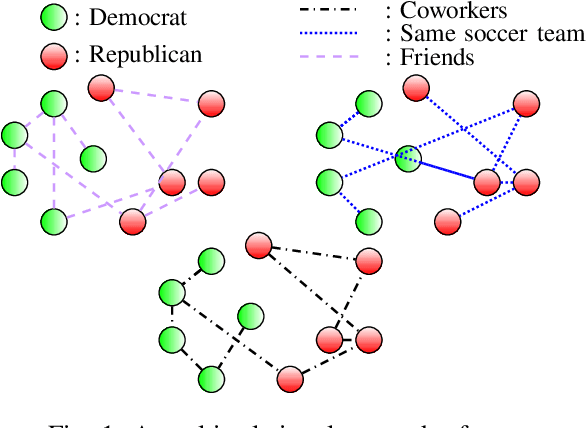
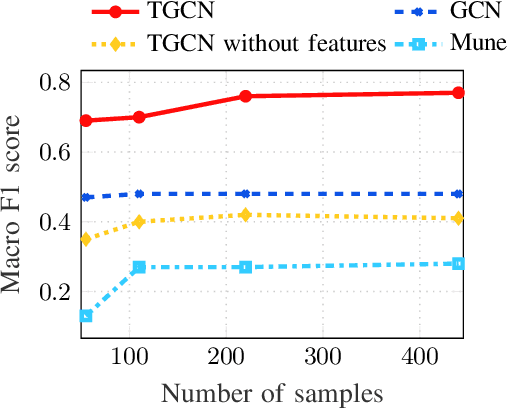
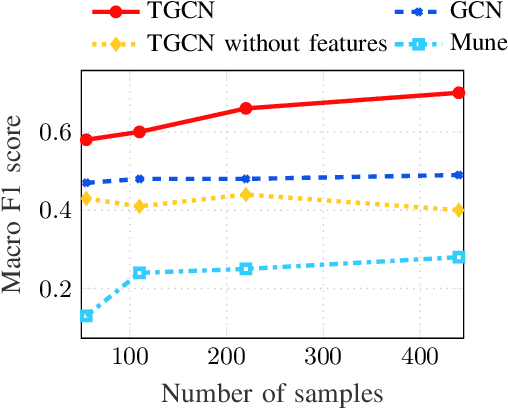
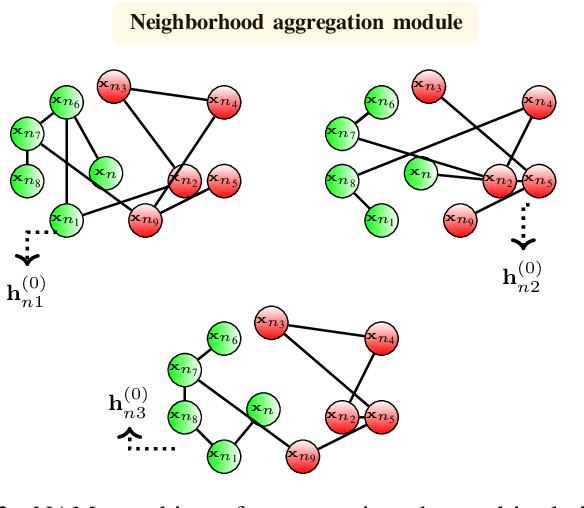
The era of "data deluge" has sparked renewed interest in graph-based learning methods and their widespread applications ranging from sociology and biology to transportation and communications. In this context of graph-aware methods, the present paper introduces a tensor-graph convolutional network (TGCN) for scalable semi-supervised learning (SSL) from data associated with a collection of graphs, that are represented by a tensor. Key aspects of the novel TGCN architecture are the dynamic adaptation to different relations in the tensor graph via learnable weights, and the consideration of graph-based regularizers to promote smoothness and alleviate over-parameterization. The ultimate goal is to design a powerful learning architecture able to: discover complex and highly nonlinear data associations, combine (and select) multiple types of relations, scale gracefully with the graph size, and remain robust to perturbations on the graph edges. The proposed architecture is relevant not only in applications where the nodes are naturally involved in different relations (e.g., a multi-relational graph capturing family, friendship and work relations in a social network), but also in robust learning setups where the graph entails a certain level of uncertainty, and the different tensor slabs correspond to different versions (realizations) of the nominal graph. Numerical tests showcase that the proposed architecture achieves markedly improved performance relative to standard GCNs, copes with state-of-the-art adversarial attacks, and leads to remarkable SSL performance over protein-to-protein interaction networks.
Efficient and Stable Graph Scattering Transforms via Pruning
Jan 27, 2020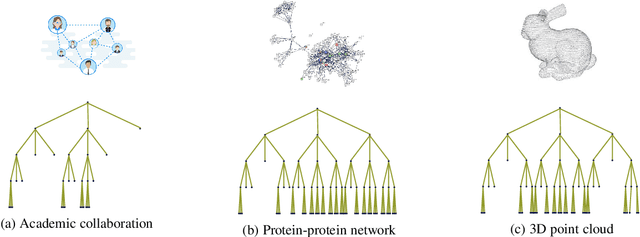
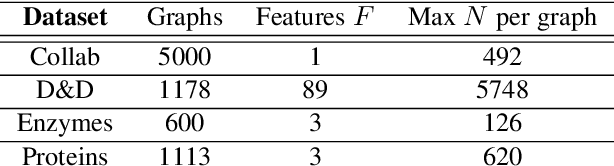
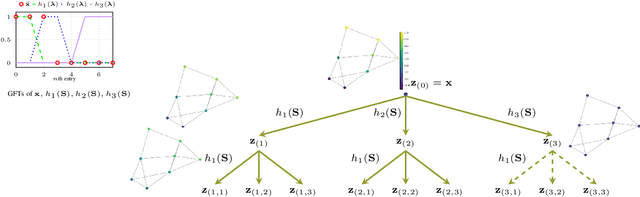
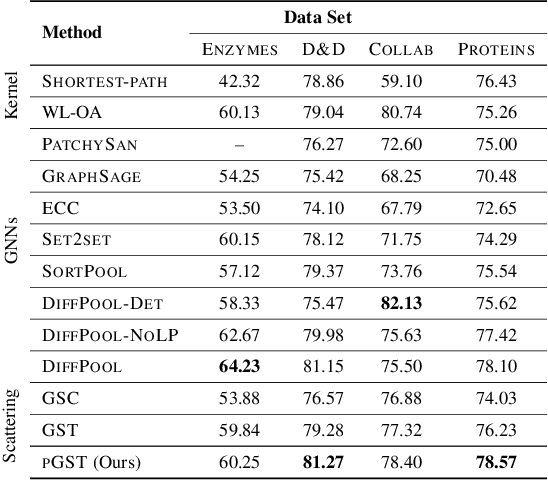
Graph convolutional networks (GCNs) have well-documented performance in various graph learning tasks, but their analysis is still at its infancy. Graph scattering transforms (GSTs) offer training-free deep GCN models that extract features from graph data, and are amenable to generalization and stability analyses. The price paid by GSTs is exponential complexity in space and time that increases with the number of layers. This discourages deployment of GSTs when a deep architecture is needed. The present work addresses the complexity limitation of GSTs by introducing an efficient so-termed pruned (p)GST approach. The resultant pruning algorithm is guided by a graph-spectrum-inspired criterion, and retains informative scattering features on-the-fly while bypassing the exponential complexity associated with GSTs. Stability of the novel pGSTs is also established when the input graph data or the network structure are perturbed. Furthermore, the sensitivity of pGST to random and localized signal perturbations is investigated analytically and experimentally. Numerical tests showcase that pGST performs comparably to the baseline GST at considerable computational savings. Furthermore, pGST achieves comparable performance to state-of-the-art GCNs in graph and 3D point cloud classification tasks. Upon analyzing the pGST pruning patterns, it is shown that graph data in different domains call for different network architectures, and that the pruning algorithm may be employed to guide the design choices for contemporary GCNs.
Federated Variance-Reduced Stochastic Gradient Descent with Robustness to Byzantine Attacks
Dec 29, 2019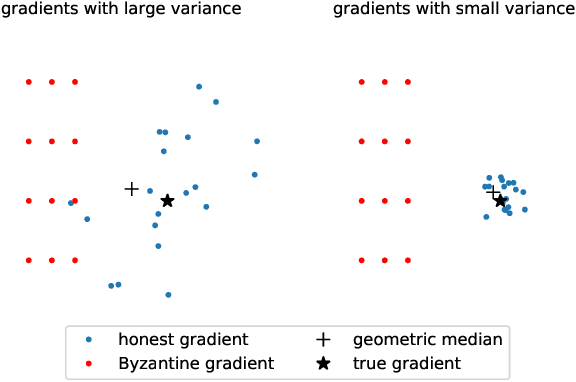
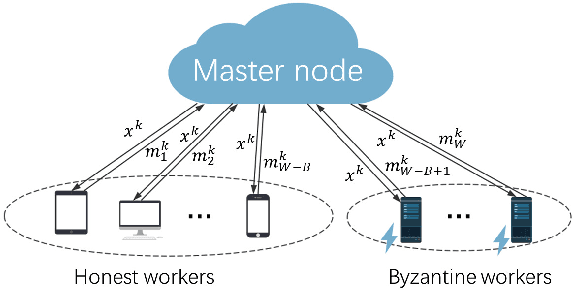
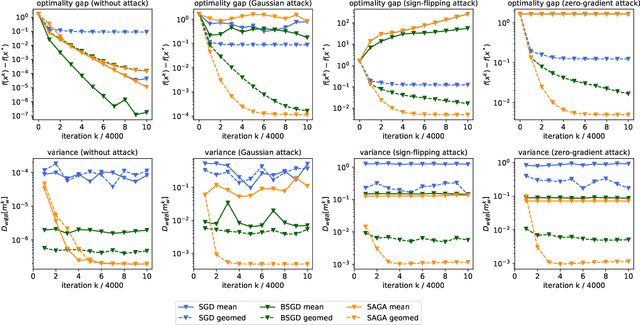
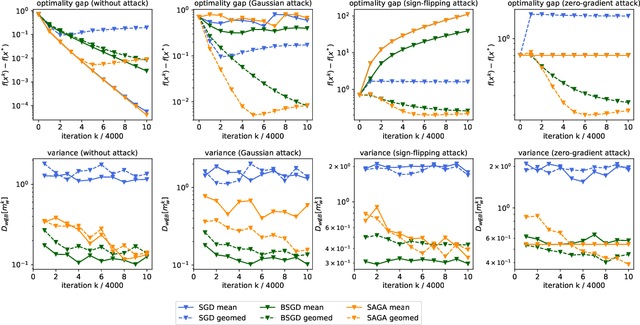
This paper deals with distributed finite-sum optimization for learning over networks in the presence of malicious Byzantine attacks. To cope with such attacks, most resilient approaches so far combine stochastic gradient descent (SGD) with different robust aggregation rules. However, the sizeable SGD-induced stochastic gradient noise makes it challenging to distinguish malicious messages sent by the Byzantine attackers from noisy stochastic gradients sent by the 'honest' workers. This motivates us to reduce the variance of stochastic gradients as a means of robustifying SGD in the presence of Byzantine attacks. To this end, the present work puts forth a Byzantine attack resilient distributed (Byrd-) SAGA approach for learning tasks involving finite-sum optimization over networks. Rather than the mean employed by distributed SAGA, the novel Byrd- SAGA relies on the geometric median to aggregate the corrected stochastic gradients sent by the workers. When less than half of the workers are Byzantine attackers, the robustness of geometric median to outliers enables Byrd-SAGA to attain provably linear convergence to a neighborhood of the optimal solution, with the asymptotic learning error determined by the number of Byzantine workers. Numerical tests corroborate the robustness to various Byzantine attacks, as well as the merits of Byrd- SAGA over Byzantine attack resilient distributed SGD.
Finite-Sample Analysis of Decentralized Temporal-Difference Learning with Linear Function Approximation
Nov 03, 2019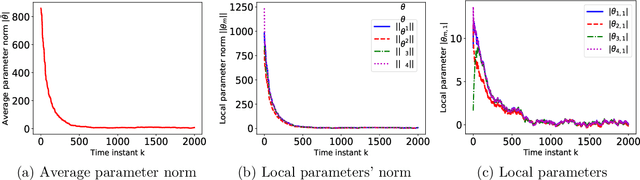
Motivated by the emerging use of multi-agent reinforcement learning (MARL) in engineering applications such as networked robotics, swarming drones, and sensor networks, we investigate the policy evaluation problem in a fully decentralized setting, using temporal-difference (TD) learning with linear function approximation to handle large state spaces in practice. The goal of a group of agents is to collaboratively learn the value function of a given policy from locally private rewards observed in a shared environment, through exchanging local estimates with neighbors. Despite their simplicity and widespread use, our theoretical understanding of such decentralized TD learning algorithms remains limited. Existing results were obtained based on i.i.d. data samples, or by imposing an `additional' projection step to control the `gradient' bias incurred by the Markovian observations. In this paper, we provide a finite-sample analysis of the fully decentralized TD(0) learning under both i.i.d. as well as Markovian samples, and prove that all local estimates converge linearly to a small neighborhood of the optimum. The resultant error bounds are the first of its type---in the sense that they hold under the most practical assumptions ---which is made possible by means of a novel multi-step Lyapunov analysis.
A Statistical Learning Approach to Reactive Power Control in Distribution Systems
Oct 25, 2019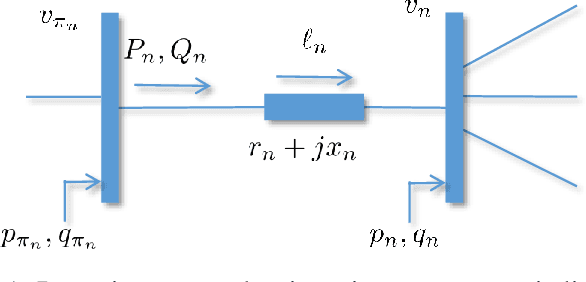
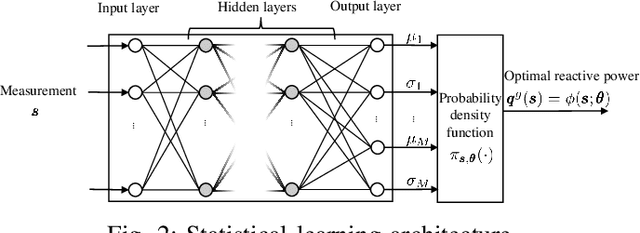
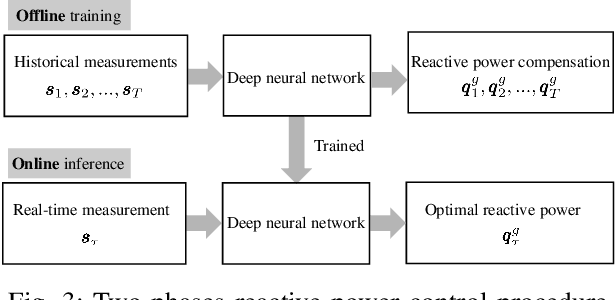
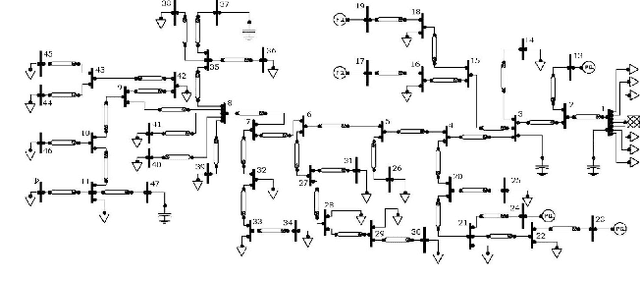
Pronounced variability due to the growth of renewable energy sources, flexible loads, and distributed generation is challenging residential distribution systems. This context, motivates well fast, efficient, and robust reactive power control. Real-time optimal reactive power control is possible in theory by solving a non-convex optimization problem based on the exact model of distribution flow. However, lack of high-precision instrumentation and reliable communications, as well as the heavy computational burden of non-convex optimization solvers render computing and implementing the optimal control challenging in practice. Taking a statistical learning viewpoint, the input-output relationship between each grid state and the corresponding optimal reactive power control is parameterized in the present work by a deep neural network, whose unknown weights are learned offline by minimizing the power loss over a number of historical and simulated training pairs. In the inference phase, one just feeds the real-time state vector into the learned neural network to obtain the `optimal' reactive power control with only several matrix-vector multiplications. The merits of this novel statistical learning approach are computational efficiency as well as robustness to random input perturbations. Numerical tests on a 47-bus distribution network using real data corroborate these practical merits.
Edge Dithering for Robust Adaptive Graph Convolutional Networks
Oct 21, 2019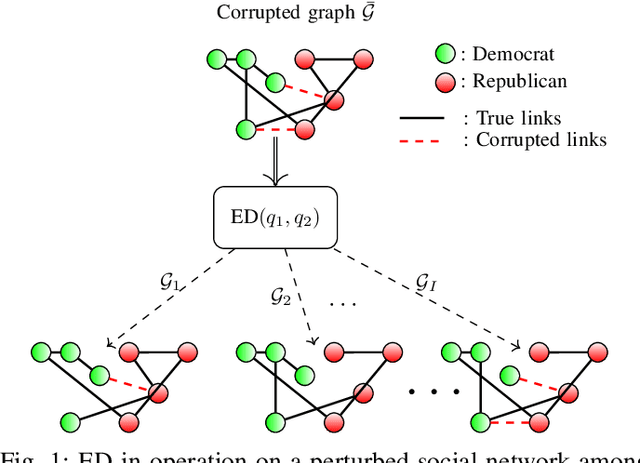
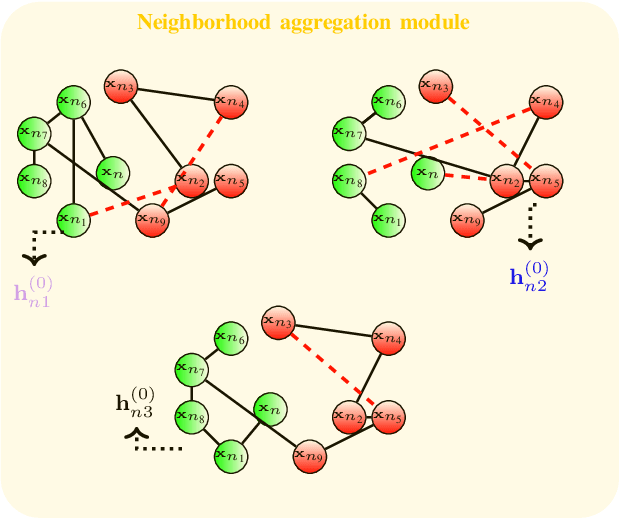
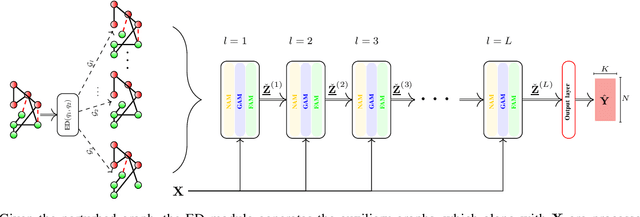
Graph convolutional networks (GCNs) are vulnerable to perturbations of the graph structure that are either random, or, adversarially designed. The perturbed links modify the graph neighborhoods, which critically affects the performance of GCNs in semi-supervised learning (SSL) tasks. Aiming at robustifying GCNs conditioned on the perturbed graph, the present paper generates multiple auxiliary graphs, each having its binary 0-1 edge weights flip values with probabilities designed to enhance robustness. The resultant edge-dithered auxiliary graphs are leveraged by an adaptive (A)GCN that performs SSL. Robustness is enabled through learnable graph-combining weights along with suitable regularizers. Relative to GCN, the novel AGCN achieves markedly improved performance in tests with noisy inputs, graph perturbations, and state-of-the-art adversarial attacks. Further experiments with protein interaction networks showcase the competitive performance of AGCN for SSL over multiple graphs.
GraphSAC: Detecting anomalies in large-scale graphs
Oct 21, 2019
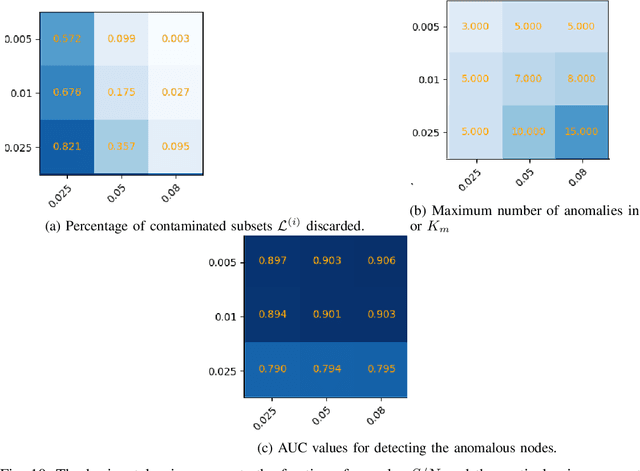
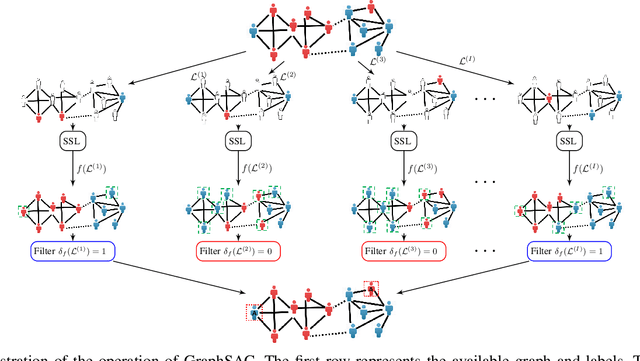
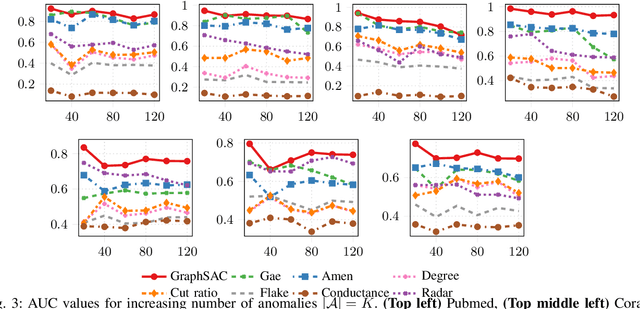
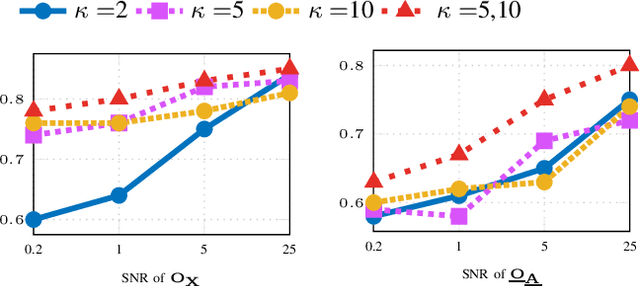
A graph-based sampling and consensus (GraphSAC) approach is introduced to effectively detect anomalous nodes in large-scale graphs. Existing approaches rely on connectivity and attributes of all nodes to assign an anomaly score per node. However, nodal attributes and network links might be compromised by adversaries, rendering these holistic approaches vulnerable. Alleviating this limitation, GraphSAC randomly draws subsets of nodes, and relies on graph-aware criteria to judiciously filter out sets contaminated by anomalous nodes, before employing a semi-supervised learning (SSL) module to estimate nominal label distributions per node. These learned nominal distributions are minimally affected by the anomalous nodes, and hence can be directly adopted for anomaly detection. Rigorous analysis provides performance guarantees for GraphSAC, by bounding the required number of draws. The per-draw complexity grows linearly with the number of edges, which implies efficient SSL, while draws can be run in parallel, thereby ensuring scalability to large graphs. GraphSAC is tested under different anomaly generation models based on random walks, clustered anomalies, as well as contemporary adversarial attacks for graph data. Experiments with real-world graphs showcase the advantage of GraphSAC relative to state-of-the-art alternatives.
Adaptive Step Sizes in Variance Reduction via Regularization
Oct 15, 2019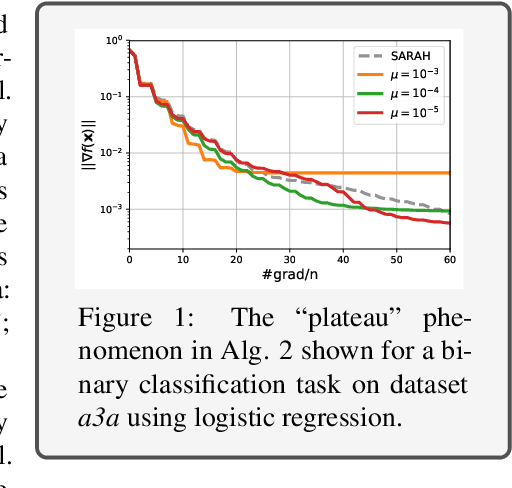
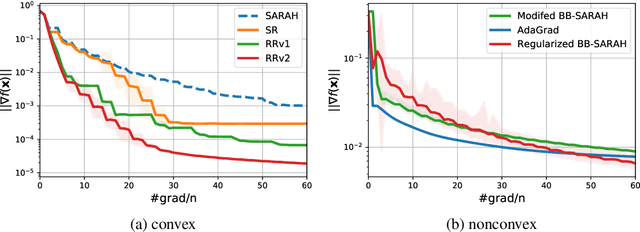
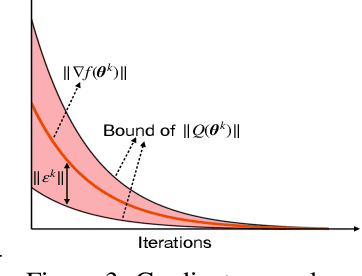
The main goal of this work is equipping convex and nonconvex problems with Barzilai-Borwein (BB) step size. With the adaptivity of BB step sizes granted, they can fail when the objective function is not strongly convex. To overcome this challenge, the key idea here is to bridge (non)convex problems and strongly convex ones via regularization. The proposed regularization schemes are \textit{simple} yet effective. Wedding the BB step size with a variance reduction method, known as SARAH, offers a free lunch compared with vanilla SARAH in convex problems. The convergence of BB step sizes in nonconvex problems is also established and its complexity is no worse than other adaptive step sizes such as AdaGrad. As a byproduct, our regularized SARAH methods for convex functions ensure that the complexity to find $\mathbb{E}[\| \nabla f(\mathbf{x}) \|^2]\leq \epsilon$ is ${\cal O}\big( (n+\frac{1}{\sqrt{\epsilon}})\ln{\frac{1}{\epsilon}}\big)$, improving $\epsilon$ dependence over existing results. Numerical tests further validate the merits of proposed approaches.
Communication-Efficient Distributed Learning via Lazily Aggregated Quantized Gradients
Sep 17, 2019
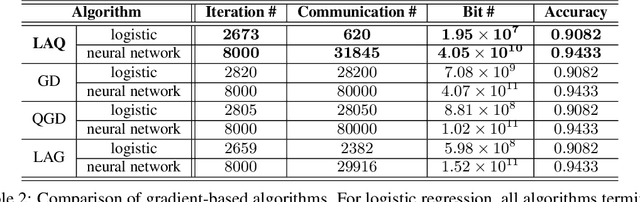
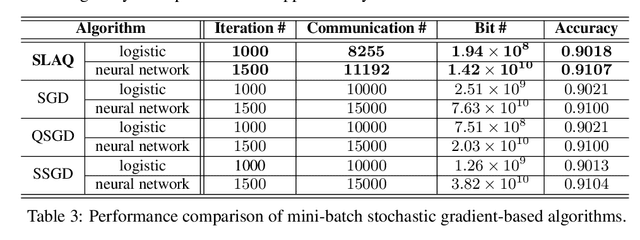
The present paper develops a novel aggregated gradient approach for distributed machine learning that adaptively compresses the gradient communication. The key idea is to first quantize the computed gradients, and then skip less informative quantized gradient communications by reusing outdated gradients. Quantizing and skipping result in `lazy' worker-server communications, which justifies the term Lazily Aggregated Quantized gradient that is henceforth abbreviated as LAQ. Our LAQ can provably attain the same linear convergence rate as the gradient descent in the strongly convex case, while effecting major savings in the communication overhead both in transmitted bits as well as in communication rounds. Empirically, experiments with real data corroborate a significant communication reduction compared to existing gradient- and stochastic gradient-based algorithms.