 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertification of Machine Learning Models via Directional Sharpness
Jun 23, 2026In machine learning, model certification has been identified as an important method for gaining assurance about a model's trustworthiness and quality. A model's quality is largely determined by its ability to generalize, i.e., to perform well on data beyond what it was trained on. It is not possible to certify generalization directly, however, as it depends on unknown data and is not directly measurable. Proxies such as test accuracy can be misleading when the training process is perturbed (intentionally or accidentally), and metrics such as sharpness -- which has an empirically supported link to generalization -- are computationally expensive and can also serve as unreliable signals when training deviates from a prescribed procedure. In this work, we propose directional sharpness, a metric designed to efficiently and reliably indicate generalization despite potential training deviations. We provide empirical and analytical evidence that directional sharpness (1) correlates more strongly with generalization than existing metrics and (2) identifies models with poor generalization more reliably than existing metrics. Furthermore, directional sharpness is efficiently computable in model auditing settings, where the verifier has access to training data, and via zero-knowledge proofs that certify quality without revealing training data.
Reproducible Subjective Evaluation
Mar 08, 2022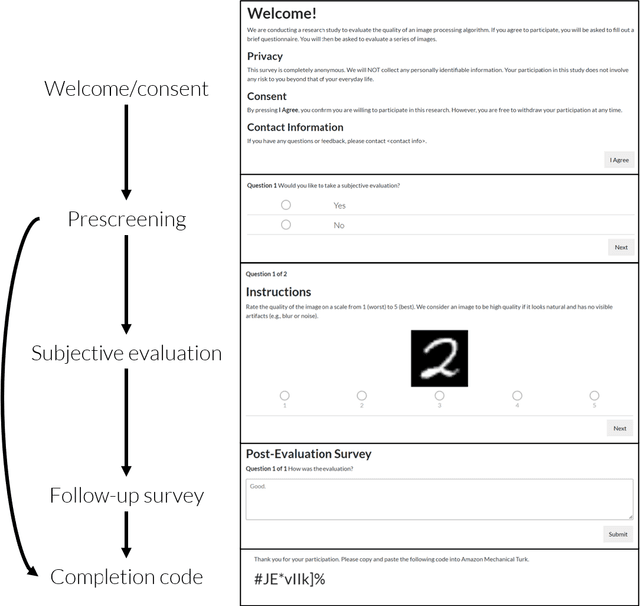

Human perceptual studies are the gold standard for the evaluation of many research tasks in machine learning, linguistics, and psychology. However, these studies require significant time and cost to perform. As a result, many researchers use objective measures that can correlate poorly with human evaluation. When subjective evaluations are performed, they are often not reported with sufficient detail to ensure reproducibility. We propose Reproducible Subjective Evaluation (ReSEval), an open-source framework for quickly deploying crowdsourced subjective evaluations directly from Python. ReSEval lets researchers launch A/B, ABX, Mean Opinion Score (MOS) and MUltiple Stimuli with Hidden Reference and Anchor (MUSHRA) tests on audio, image, text, or video data from a command-line interface or using one line of Python, making it as easy to run as objective evaluation. With ReSEval, researchers can reproduce each other's subjective evaluations by sharing a configuration file and the audio, image, text, or video files.