 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-probability Convergence Bounds for Nonlinear Stochastic Gradient Descent Under Heavy-tailed Noise
Oct 28, 2023Several recent works have studied the convergence \textit{in high probability} of stochastic gradient descent (SGD) and its clipped variant. Compared to vanilla SGD, clipped SGD is practically more stable and has the additional theoretical benefit of logarithmic dependence on the failure probability. However, the convergence of other practical nonlinear variants of SGD, e.g., sign SGD, quantized SGD and normalized SGD, that achieve improved communication efficiency or accelerated convergence is much less understood. In this work, we study the convergence bounds \textit{in high probability} of a broad class of nonlinear SGD methods. For strongly convex loss functions with Lipschitz continuous gradients, we prove a logarithmic dependence on the failure probability, even when the noise is heavy-tailed. Strictly more general than the results for clipped SGD, our results hold for any nonlinearity with bounded (component-wise or joint) outputs, such as clipping, normalization, and quantization. Further, existing results with heavy-tailed noise assume bounded $\eta$-th central moments, with $\eta \in (1,2]$. In contrast, our refined analysis works even for $\eta=1$, strictly relaxing the noise moment assumptions in the literature.
Local or Global: Selective Knowledge Assimilation for Federated Learning with Limited Labels
Jul 17, 2023



Many existing FL methods assume clients with fully-labeled data, while in realistic settings, clients have limited labels due to the expensive and laborious process of labeling. Limited labeled local data of the clients often leads to their local model having poor generalization abilities to their larger unlabeled local data, such as having class-distribution mismatch with the unlabeled data. As a result, clients may instead look to benefit from the global model trained across clients to leverage their unlabeled data, but this also becomes difficult due to data heterogeneity across clients. In our work, we propose FedLabel where clients selectively choose the local or global model to pseudo-label their unlabeled data depending on which is more of an expert of the data. We further utilize both the local and global models' knowledge via global-local consistency regularization which minimizes the divergence between the two models' outputs when they have identical pseudo-labels for the unlabeled data. Unlike other semi-supervised FL baselines, our method does not require additional experts other than the local or global model, nor require additional parameters to be communicated. We also do not assume any server-labeled data or fully labeled clients. For both cross-device and cross-silo settings, we show that FedLabel outperforms other semi-supervised FL baselines by $8$-$24\%$, and even outperforms standard fully supervised FL baselines ($100\%$ labeled data) with only $5$-$20\%$ of labeled data.
The Blessing of Heterogeneity in Federated Q-learning: Linear Speedup and Beyond
May 18, 2023When the data used for reinforcement learning (RL) are collected by multiple agents in a distributed manner, federated versions of RL algorithms allow collaborative learning without the need of sharing local data. In this paper, we consider federated Q-learning, which aims to learn an optimal Q-function by periodically aggregating local Q-estimates trained on local data alone. Focusing on infinite-horizon tabular Markov decision processes, we provide sample complexity guarantees for both the synchronous and asynchronous variants of federated Q-learning. In both cases, our bounds exhibit a linear speedup with respect to the number of agents and sharper dependencies on other salient problem parameters. Moreover, existing approaches to federated Q-learning adopt an equally-weighted averaging of local Q-estimates, which can be highly sub-optimal in the asynchronous setting since the local trajectories can be highly heterogeneous due to different local behavior policies. Existing sample complexity scales inverse proportionally to the minimum entry of the stationary state-action occupancy distributions over all agents, requiring that every agent covers the entire state-action space. Instead, we propose a novel importance averaging algorithm, giving larger weights to more frequently visited state-action pairs. The improved sample complexity scales inverse proportionally to the minimum entry of the average stationary state-action occupancy distribution of all agents, thus only requiring the agents collectively cover the entire state-action space, unveiling the blessing of heterogeneity.
Federated Minimax Optimization with Client Heterogeneity
Feb 09, 2023



Minimax optimization has seen a surge in interest with the advent of modern applications such as GANs, and it is inherently more challenging than simple minimization. The difficulty is exacerbated by the training data residing at multiple edge devices or \textit{clients}, especially when these clients can have heterogeneous datasets and local computation capabilities. We propose a general federated minimax optimization framework that subsumes such settings and several existing methods like Local SGDA. We show that naive aggregation of heterogeneous local progress results in optimizing a mismatched objective function -- a phenomenon previously observed in standard federated minimization. To fix this problem, we propose normalizing the client updates by the number of local steps undertaken between successive communication rounds. We analyze the convergence of the proposed algorithm for classes of nonconvex-concave and nonconvex-nonconcave functions and characterize the impact of heterogeneous client data, partial client participation, and heterogeneous local computations. Our analysis works under more general assumptions on the intra-client noise and inter-client heterogeneity than so far considered in the literature. For all the function classes considered, we significantly improve the existing computation and communication complexity results. Experimental results support our theoretical claims.
On the Convergence of Federated Averaging with Cyclic Client Participation
Feb 06, 2023



Federated Averaging (FedAvg) and its variants are the most popular optimization algorithms in federated learning (FL). Previous convergence analyses of FedAvg either assume full client participation or partial client participation where the clients can be uniformly sampled. However, in practical cross-device FL systems, only a subset of clients that satisfy local criteria such as battery status, network connectivity, and maximum participation frequency requirements (to ensure privacy) are available for training at a given time. As a result, client availability follows a natural cyclic pattern. We provide (to our knowledge) the first theoretical framework to analyze the convergence of FedAvg with cyclic client participation with several different client optimizers such as GD, SGD, and shuffled SGD. Our analysis discovers that cyclic client participation can achieve a faster asymptotic convergence rate than vanilla FedAvg with uniform client participation under suitable conditions, providing valuable insights into the design of client sampling protocols.
FedExP: Speeding up Federated Averaging Via Extrapolation
Jan 23, 2023



Federated Averaging (FedAvg) remains the most popular algorithm for Federated Learning (FL) optimization due to its simple implementation, stateless nature, and privacy guarantees combined with secure aggregation. Recent work has sought to generalize the vanilla averaging in FedAvg to a generalized gradient descent step by treating client updates as pseudo-gradients and using a server step size. While the use of a server step size has been shown to provide performance improvement theoretically, the practical benefit of the server step size has not been seen in most existing works. In this work, we present FedExP, a method to adaptively determine the server step size in FL based on dynamically varying pseudo-gradients throughout the FL process. We begin by considering the overparameterized convex regime, where we reveal an interesting similarity between FedAvg and the Projection Onto Convex Sets (POCS) algorithm. We then show how FedExP can be motivated as a novel extension to the extrapolation mechanism that is used to speed up POCS. Our theoretical analysis later also discusses the implications of FedExP in underparameterized and non-convex settings. Experimental results show that FedExP consistently converges faster than FedAvg and competing baselines on a range of realistic FL datasets.
FedVARP: Tackling the Variance Due to Partial Client Participation in Federated Learning
Jul 28, 2022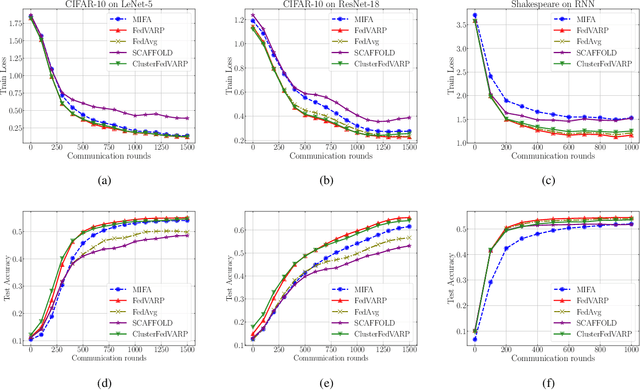
Data-heterogeneous federated learning (FL) systems suffer from two significant sources of convergence error: 1) client drift error caused by performing multiple local optimization steps at clients, and 2) partial client participation error caused by the fact that only a small subset of the edge clients participate in every training round. We find that among these, only the former has received significant attention in the literature. To remedy this, we propose FedVARP, a novel variance reduction algorithm applied at the server that eliminates error due to partial client participation. To do so, the server simply maintains in memory the most recent update for each client and uses these as surrogate updates for the non-participating clients in every round. Further, to alleviate the memory requirement at the server, we propose a novel clustering-based variance reduction algorithm ClusterFedVARP. Unlike previously proposed methods, both FedVARP and ClusterFedVARP do not require additional computation at clients or communication of additional optimization parameters. Through extensive experiments, we show that FedVARP outperforms state-of-the-art methods, and ClusterFedVARP achieves performance comparable to FedVARP with much less memory requirements.
Multi-Model Federated Learning with Provable Guarantees
Jul 17, 2022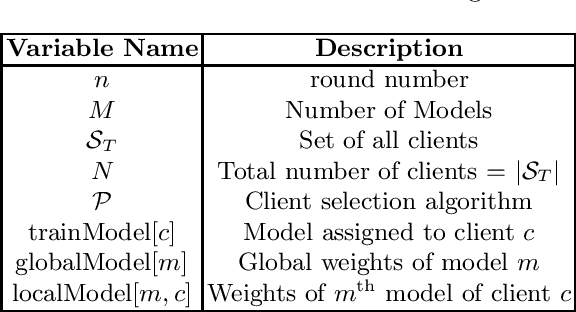
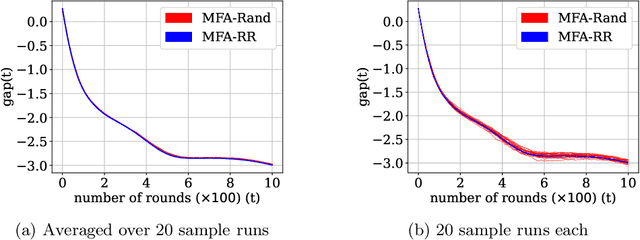

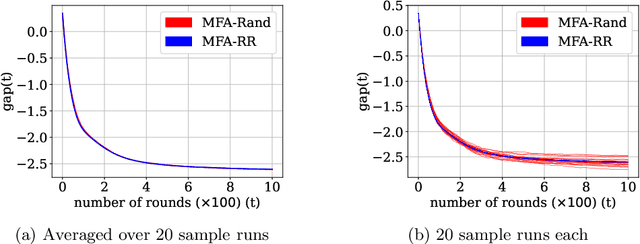
Federated Learning (FL) is a variant of distributed learning where edge devices collaborate to learn a model without sharing their data with the central server or each other. We refer to the process of training multiple independent models simultaneously in a federated setting using a common pool of clients as multi-model FL. In this work, we propose two variants of the popular FedAvg algorithm for multi-model FL, with provable convergence guarantees. We further show that for the same amount of computation, multi-model FL can have better performance than training each model separately. We supplement our theoretical results with experiments in strongly convex, convex, and non-convex settings.
Federated Reinforcement Learning: Linear Speedup Under Markovian Sampling
Jun 21, 2022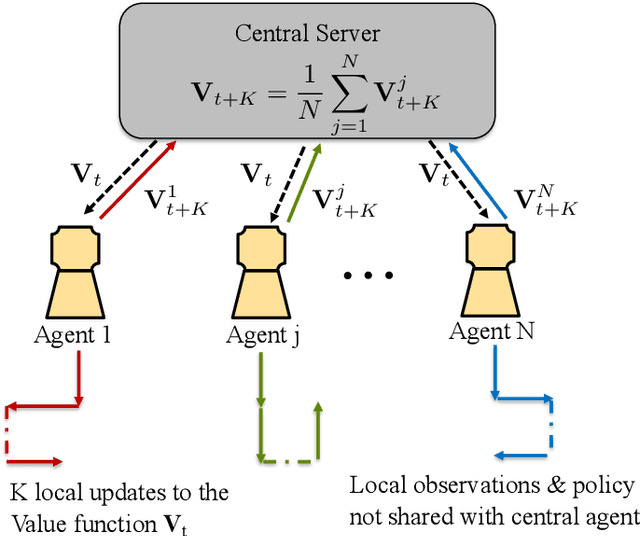
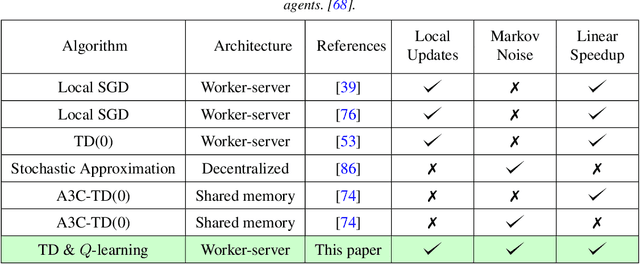
Since reinforcement learning algorithms are notoriously data-intensive, the task of sampling observations from the environment is usually split across multiple agents. However, transferring these observations from the agents to a central location can be prohibitively expensive in terms of the communication cost, and it can also compromise the privacy of each agent's local behavior policy. In this paper, we consider a federated reinforcement learning framework where multiple agents collaboratively learn a global model, without sharing their individual data and policies. Each agent maintains a local copy of the model and updates it using locally sampled data. Although having N agents enables the sampling of N times more data, it is not clear if it leads to proportional convergence speedup. We propose federated versions of on-policy TD, off-policy TD and Q-learning, and analyze their convergence. For all these algorithms, to the best of our knowledge, we are the first to consider Markovian noise and multiple local updates, and prove a linear convergence speedup with respect to the number of agents. To obtain these results, we show that federated TD and Q-learning are special cases of a general framework for federated stochastic approximation with Markovian noise, and we leverage this framework to provide a unified convergence analysis that applies to all the algorithms.
On the Unreasonable Effectiveness of Federated Averaging with Heterogeneous Data
Jun 09, 2022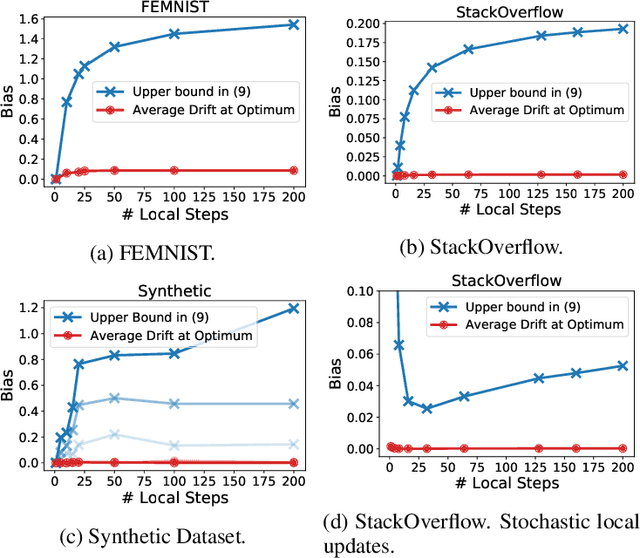
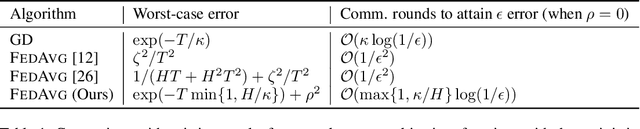
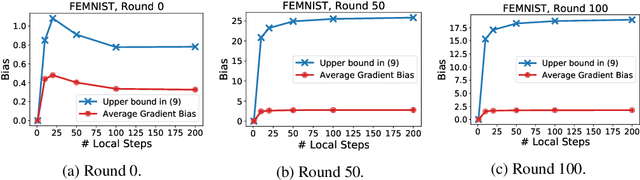
Existing theory predicts that data heterogeneity will degrade the performance of the Federated Averaging (FedAvg) algorithm in federated learning. However, in practice, the simple FedAvg algorithm converges very well. This paper explains the seemingly unreasonable effectiveness of FedAvg that contradicts the previous theoretical predictions. We find that the key assumption of bounded gradient dissimilarity in previous theoretical analyses is too pessimistic to characterize data heterogeneity in practical applications. For a simple quadratic problem, we demonstrate there exist regimes where large gradient dissimilarity does not have any negative impact on the convergence of FedAvg. Motivated by this observation, we propose a new quantity, average drift at optimum, to measure the effects of data heterogeneity, and explicitly use it to present a new theoretical analysis of FedAvg. We show that the average drift at optimum is nearly zero across many real-world federated training tasks, whereas the gradient dissimilarity can be large. And our new analysis suggests FedAvg can have identical convergence rates in homogeneous and heterogeneous data settings, and hence, leads to better understanding of its empirical success.