 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multi-modality Cell Segmentation Challenge: Towards Universal Solutions
Aug 10, 2023Cell segmentation is a critical step for quantitative single-cell analysis in microscopy images. Existing cell segmentation methods are often tailored to specific modalities or require manual interventions to specify hyperparameters in different experimental settings. Here, we present a multi-modality cell segmentation benchmark, comprising over 1500 labeled images derived from more than 50 diverse biological experiments. The top participants developed a Transformer-based deep-learning algorithm that not only exceeds existing methods, but can also be applied to diverse microscopy images across imaging platforms and tissue types without manual parameter adjustments. This benchmark and the improved algorithm offer promising avenues for more accurate and versatile cell analysis in microscopy imaging.
Spatially Resolved Gene Expression Prediction from H&E Histology Images via Bi-modal Contrastive Learning
Jun 02, 2023



Histology imaging is an important tool in medical diagnosis and research, enabling the examination of tissue structure and composition at the microscopic level. Understanding the underlying molecular mechanisms of tissue architecture is critical in uncovering disease mechanisms and developing effective treatments. Gene expression profiling provides insight into the molecular processes underlying tissue architecture, but the process can be time-consuming and expensive. In this study, we present BLEEP (Bi-modaL Embedding for Expression Prediction), a bi-modal embedding framework capable of generating spatially resolved gene expression profiles of whole-slide Hematoxylin and eosin (H&E) stained histology images. BLEEP uses a contrastive learning framework to construct a low-dimensional joint embedding space from a reference dataset using paired image and expression profiles at micrometer resolution. With this framework, the gene expression of any query image patch can be imputed using the expression profiles from the reference dataset. We demonstrate BLEEP's effectiveness in gene expression prediction by benchmarking its performance on a human liver tissue dataset captured via the 10x Visium platform, where it achieves significant improvements over existing methods. Our results demonstrate the potential of BLEEP to provide insights into the molecular mechanisms underlying tissue architecture, with important implications in diagnosis and research of various diseases. The proposed framework can significantly reduce the time and cost associated with gene expression profiling, opening up new avenues for high-throughput analysis of histology images for both research and clinical applications.
A sequence-to-sequence approach for document-level relation extraction
Apr 10, 2022
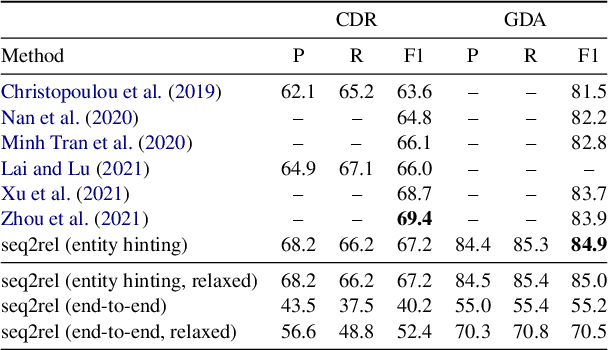
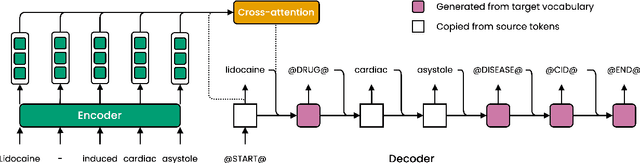
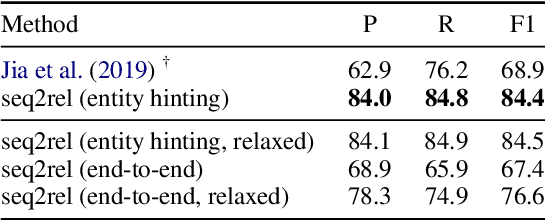
Motivated by the fact that many relations cross the sentence boundary, there has been increasing interest in document-level relation extraction (DocRE). DocRE requires integrating information within and across sentences, capturing complex interactions between mentions of entities. Most existing methods are pipeline-based, requiring entities as input. However, jointly learning to extract entities and relations can improve performance and be more efficient due to shared parameters and training steps. In this paper, we develop a sequence-to-sequence approach, seq2rel, that can learn the subtasks of DocRE (entity extraction, coreference resolution and relation extraction) end-to-end, replacing a pipeline of task-specific components. Using a simple strategy we call entity hinting, we compare our approach to existing pipeline-based methods on several popular biomedical datasets, in some cases exceeding their performance. We also report the first end-to-end results on these datasets for future comparison. Finally, we demonstrate that, under our model, an end-to-end approach outperforms a pipeline-based approach. Our code, data and trained models are available at {\url{https://github.com/johngiorgi/seq2rel}}. An online demo is available at {\url{https://share.streamlit.io/johngiorgi/seq2rel/main/demo.py}}.
DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations
Jun 11, 2020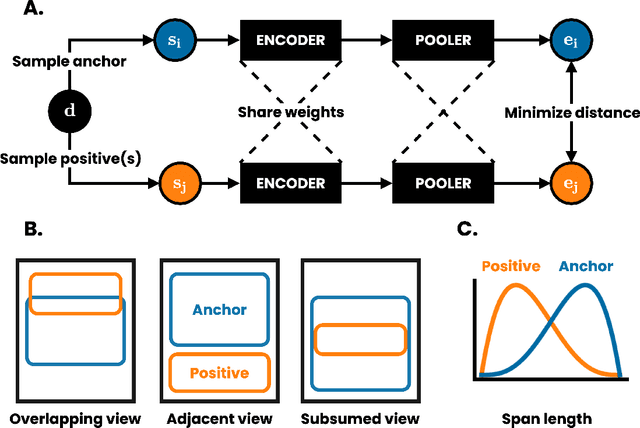
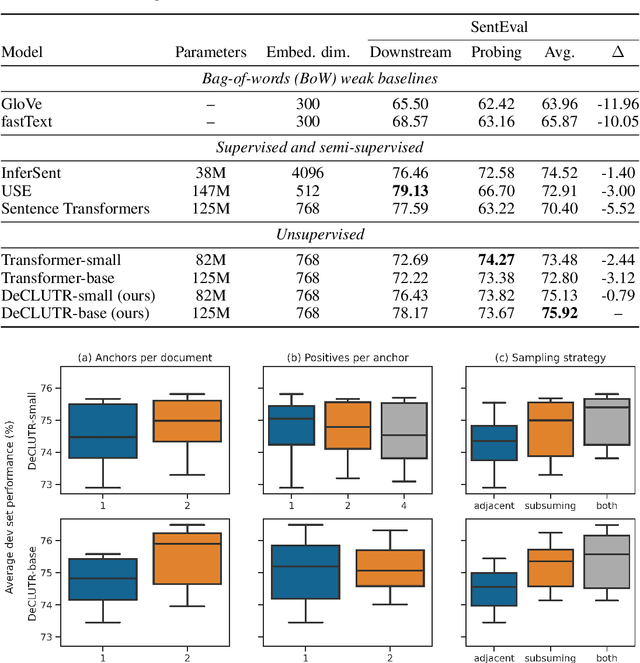
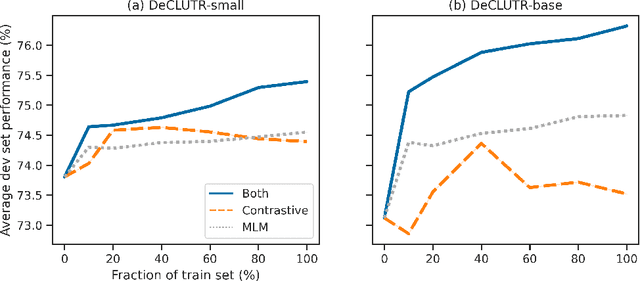
We present DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations, a self-supervised method for learning universal sentence embeddings that transfer to a wide variety of natural language processing (NLP) tasks. Our objective leverages recent advances in deep metric learning (DML) and has the advantage of being conceptually simple and easy to implement, requiring no specialized architectures or labelled training data. We demonstrate that our objective can be used to pretrain transformers to state-of-the-art performance on SentEval, a popular benchmark for evaluating universal sentence embeddings, outperforming existing supervised, semi-supervised and unsupervised methods. We perform extensive ablations to determine which factors contribute to the quality of the learned embeddings. Our code will be publicly available and can be easily adapted to new datasets or used to embed unseen text.
End-to-end Named Entity Recognition and Relation Extraction using Pre-trained Language Models
Dec 20, 2019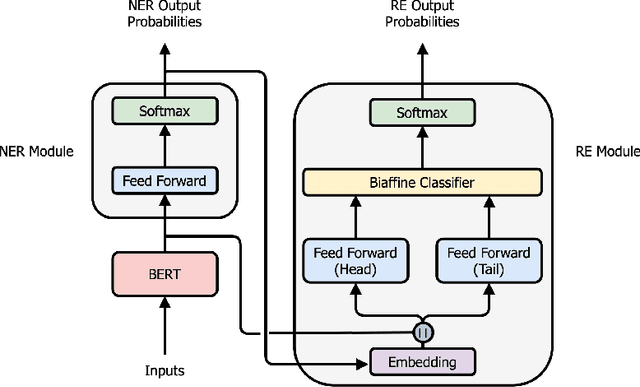
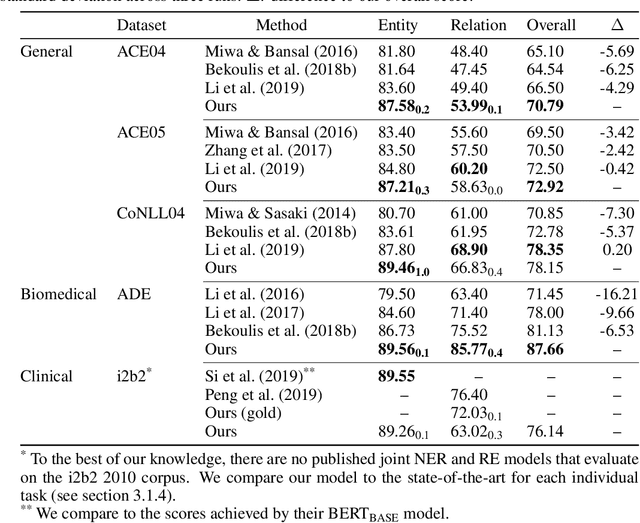
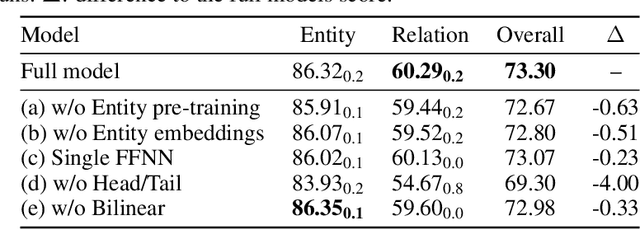
Named entity recognition (NER) and relation extraction (RE) are two important tasks in information extraction and retrieval (IE \& IR). Recent work has demonstrated that it is beneficial to learn these tasks jointly, which avoids the propagation of error inherent in pipeline-based systems and improves performance. However, state-of-the-art joint models typically rely on external natural language processing (NLP) tools, such as dependency parsers, limiting their usefulness to domains (e.g. news) where those tools perform well. The few neural, end-to-end models that have been proposed are trained almost completely from scratch. In this paper, we propose a neural, end-to-end model for jointly extracting entities and their relations which does not rely on external NLP tools and which integrates a large, pre-trained language model. Because the bulk of our model's parameters are pre-trained and we eschew recurrence for self-attention, our model is fast to train. On 5 datasets across 3 domains, our model matches or exceeds state-of-the-art performance, sometimes by a large margin.