 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifiability Assumptions and Algorithm for Directed Graphical Models with Feedback
Jul 06, 2016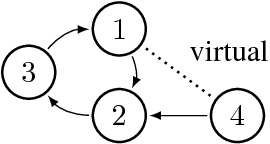
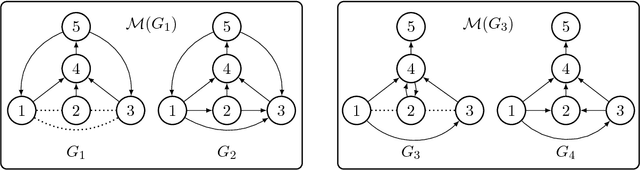
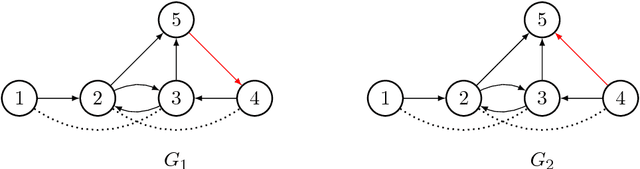
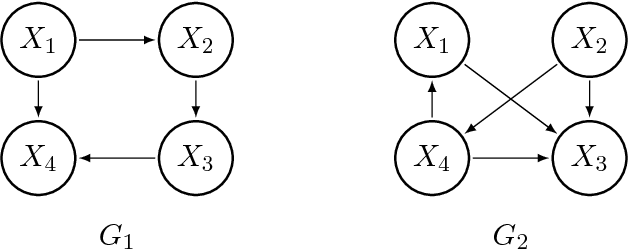
Directed graphical models provide a useful framework for modeling causal or directional relationships for multivariate data. Prior work has largely focused on identifiability and search algorithms for directed acyclic graphical (DAG) models. In many applications, feedback naturally arises and directed graphical models that permit cycles occur. In this paper we address the issue of identifiability for general directed cyclic graphical (DCG) models satisfying the Markov assumption. In particular, in addition to the faithfulness assumption which has already been introduced for cyclic models, we introduce two new identifiability assumptions, one based on selecting the model with the fewest edges and the other based on selecting the DCG model that entails the maximum number of d-separation rules. We provide theoretical results comparing these assumptions which show that: (1) selecting models with the largest number of d-separation rules is strictly weaker than the faithfulness assumption; (2) unlike for DAG models, selecting models with the fewest edges does not necessarily result in a milder assumption than the faithfulness assumption. We also provide connections between our two new principles and minimality assumptions. We use our identifiability assumptions to develop search algorithms for small-scale DCG models. Our simulation study supports our theoretical results, showing that the algorithms based on our two new principles generally out-perform algorithms based on the faithfulness assumption in terms of selecting the true skeleton for DCG models.
A Statistical Perspective on Randomized Sketching for Ordinary Least-Squares
Aug 25, 2015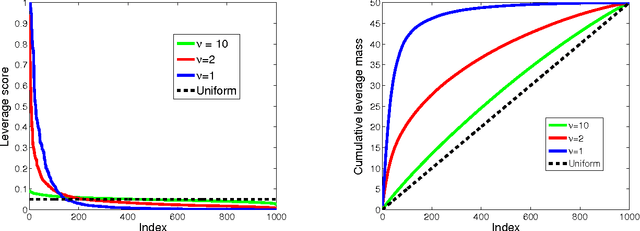
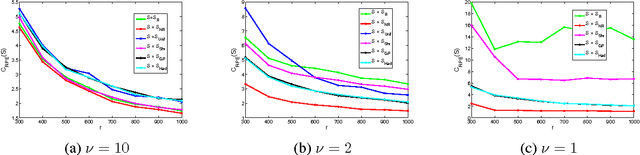
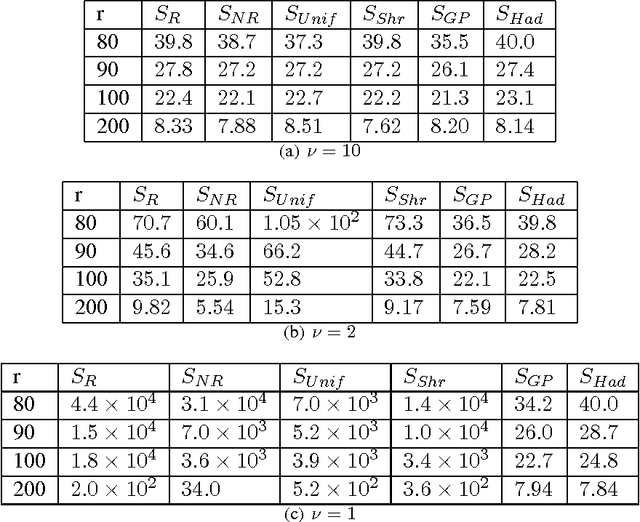
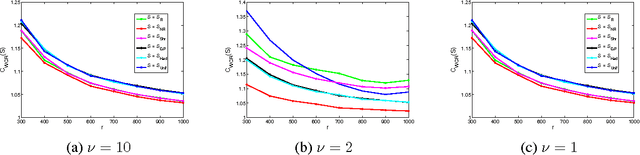
We consider statistical as well as algorithmic aspects of solving large-scale least-squares (LS) problems using randomized sketching algorithms. For a LS problem with input data $(X, Y) \in \mathbb{R}^{n \times p} \times \mathbb{R}^n$, sketching algorithms use a sketching matrix, $S\in\mathbb{R}^{r \times n}$ with $r \ll n$. Then, rather than solving the LS problem using the full data $(X,Y)$, sketching algorithms solve the LS problem using only the sketched data $(SX, SY)$. Prior work has typically adopted an algorithmic perspective, in that it has made no statistical assumptions on the input $X$ and $Y$, and instead it has been assumed that the data $(X,Y)$ are fixed and worst-case (WC). Prior results show that, when using sketching matrices such as random projections and leverage-score sampling algorithms, with $p < r \ll n$, the WC error is the same as solving the original problem, up to a small constant. From a statistical perspective, we typically consider the mean-squared error performance of randomized sketching algorithms, when data $(X, Y)$ are generated according to a statistical model $Y = X \beta + \epsilon$, where $\epsilon$ is a noise process. We provide a rigorous comparison of both perspectives leading to insights on how they differ. To do this, we first develop a framework for assessing algorithmic and statistical aspects of randomized sketching methods. We then consider the statistical prediction efficiency (PE) and the statistical residual efficiency (RE) of the sketched LS estimator; and we use our framework to provide upper bounds for several types of random projection and random sampling sketching algorithms. Among other results, we show that the RE can be upper bounded when $p < r \ll n$ while the PE typically requires the sample size $r$ to be substantially larger. Lower bounds developed in subsequent results show that our upper bounds on PE can not be improved.
Statistical and Algorithmic Perspectives on Randomized Sketching for Ordinary Least-Squares -- ICML
May 25, 2015We consider statistical and algorithmic aspects of solving large-scale least-squares (LS) problems using randomized sketching algorithms. Prior results show that, from an \emph{algorithmic perspective}, when using sketching matrices constructed from random projections and leverage-score sampling, if the number of samples $r$ much smaller than the original sample size $n$, then the worst-case (WC) error is the same as solving the original problem, up to a very small relative error. From a \emph{statistical perspective}, one typically considers the mean-squared error performance of randomized sketching algorithms, when data are generated according to a statistical linear model. In this paper, we provide a rigorous comparison of both perspectives leading to insights on how they differ. To do this, we first develop a framework for assessing, in a unified manner, algorithmic and statistical aspects of randomized sketching methods. We then consider the statistical prediction efficiency (PE) and the statistical residual efficiency (RE) of the sketched LS estimator; and we use our framework to provide upper bounds for several types of random projection and random sampling algorithms. Among other results, we show that the RE can be upper bounded when $r$ is much smaller than $n$, while the PE typically requires the number of samples $r$ to be substantially larger. Lower bounds developed in subsequent work show that our upper bounds on PE can not be improved.
The Information Geometry of Mirror Descent
Apr 29, 2014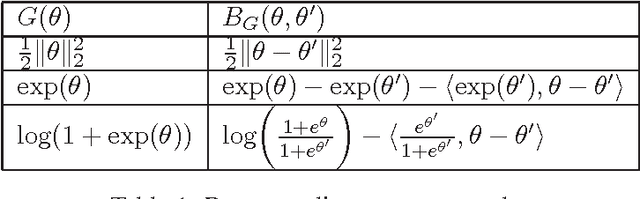

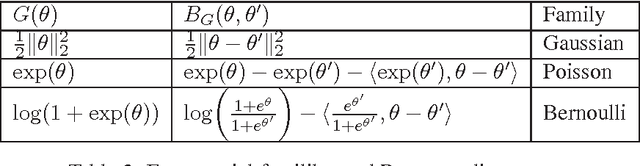
Information geometry applies concepts in differential geometry to probability and statistics and is especially useful for parameter estimation in exponential families where parameters are known to lie on a Riemannian manifold. Connections between the geometric properties of the induced manifold and statistical properties of the estimation problem are well-established. However developing first-order methods that scale to larger problems has been less of a focus in the information geometry community. The best known algorithm that incorporates manifold structure is the second-order natural gradient descent algorithm introduced by Amari. On the other hand, stochastic approximation methods have led to the development of first-order methods for optimizing noisy objective functions. A recent generalization of the Robbins-Monro algorithm known as mirror descent, developed by Nemirovski and Yudin is a first order method that induces non-Euclidean geometries. However current analysis of mirror descent does not precisely characterize the induced non-Euclidean geometry nor does it consider performance in terms of statistical relative efficiency. In this paper, we prove that mirror descent induced by Bregman divergences is equivalent to the natural gradient descent algorithm on the dual Riemannian manifold. Using this equivalence, it follows that (1) mirror descent is the steepest descent direction along the Riemannian manifold of the exponential family; (2) mirror descent with log-likelihood loss applied to parameter estimation in exponential families asymptotically achieves the classical Cram\'er-Rao lower bound and (3) natural gradient descent for manifolds corresponding to exponential families can be implemented as a first-order method through mirror descent.
Learning directed acyclic graphs based on sparsest permutations
Feb 24, 2014
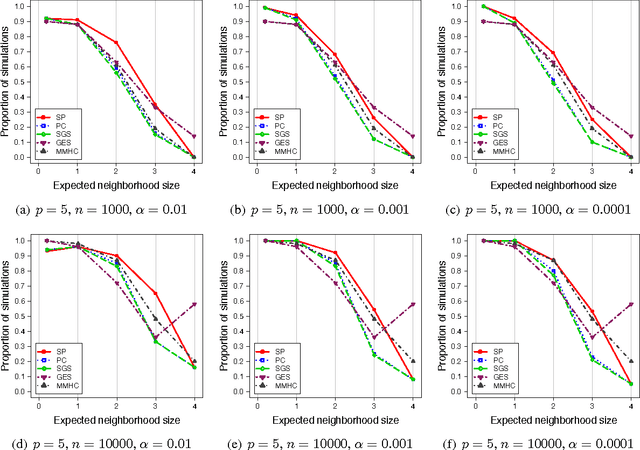
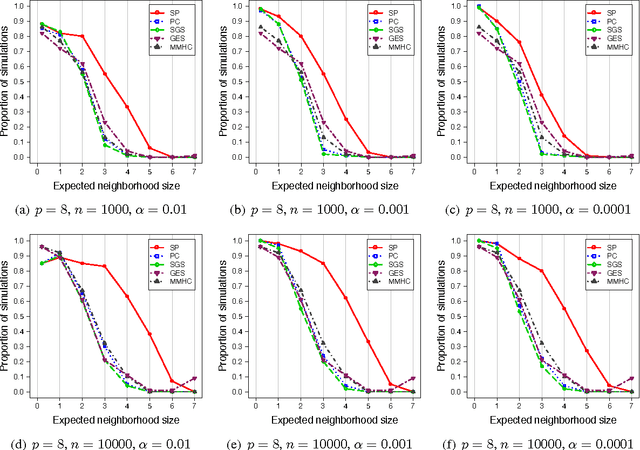
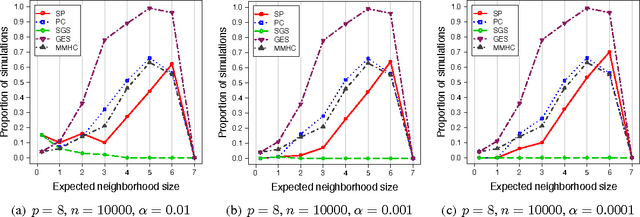
We consider the problem of learning a Bayesian network or directed acyclic graph (DAG) model from observational data. A number of constraint-based, score-based and hybrid algorithms have been developed for this purpose. For constraint-based methods, statistical consistency guarantees typically rely on the faithfulness assumption, which has been show to be restrictive especially for graphs with cycles in the skeleton. However, there is only limited work on consistency guarantees for score-based and hybrid algorithms and it has been unclear whether consistency guarantees can be proven under weaker conditions than the faithfulness assumption. In this paper, we propose the sparsest permutation (SP) algorithm. This algorithm is based on finding the causal ordering of the variables that yields the sparsest DAG. We prove that this new score-based method is consistent under strictly weaker conditions than the faithfulness assumption. We also demonstrate through simulations on small DAGs that the SP algorithm compares favorably to the constraint-based PC and SGS algorithms as well as the score-based Greedy Equivalence Search and hybrid Max-Min Hill-Climbing method. In the Gaussian setting, we prove that our algorithm boils down to finding the permutation of the variables with sparsest Cholesky decomposition for the inverse covariance matrix. Using this connection, we show that in the oracle setting, where the true covariance matrix is known, the SP algorithm is in fact equivalent to $\ell_0$-penalized maximum likelihood estimation.
Early stopping and non-parametric regression: An optimal data-dependent stopping rule
Jun 15, 2013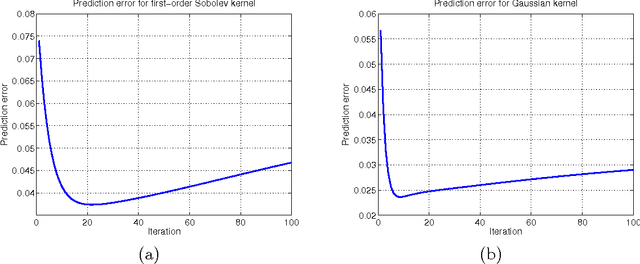
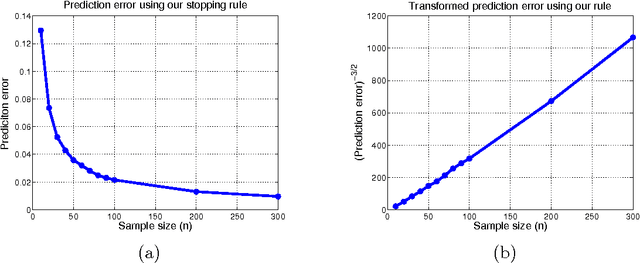
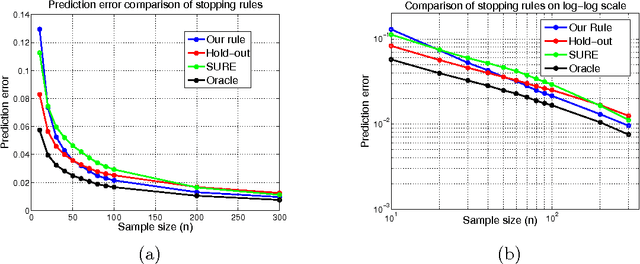
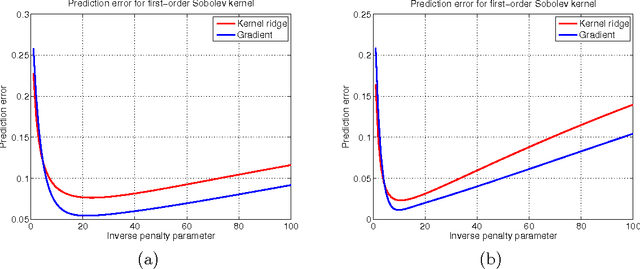
The strategy of early stopping is a regularization technique based on choosing a stopping time for an iterative algorithm. Focusing on non-parametric regression in a reproducing kernel Hilbert space, we analyze the early stopping strategy for a form of gradient-descent applied to the least-squares loss function. We propose a data-dependent stopping rule that does not involve hold-out or cross-validation data, and we prove upper bounds on the squared error of the resulting function estimate, measured in either the $L^2(P)$ and $L^2(P_n)$ norm. These upper bounds lead to minimax-optimal rates for various kernel classes, including Sobolev smoothness classes and other forms of reproducing kernel Hilbert spaces. We show through simulation that our stopping rule compares favorably to two other stopping rules, one based on hold-out data and the other based on Stein's unbiased risk estimate. We also establish a tight connection between our early stopping strategy and the solution path of a kernel ridge regression estimator.
High-dimensional covariance estimation by minimizing $\ell_1$-penalized log-determinant divergence
Nov 21, 2008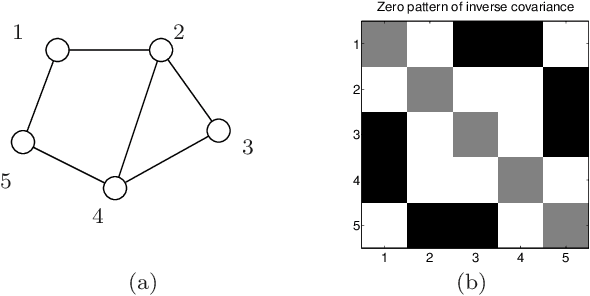
Given i.i.d. observations of a random vector $X \in \mathbb{R}^p$, we study the problem of estimating both its covariance matrix $\Sigma^*$, and its inverse covariance or concentration matrix {$\Theta^* = (\Sigma^*)^{-1}$.} We estimate $\Theta^*$ by minimizing an $\ell_1$-penalized log-determinant Bregman divergence; in the multivariate Gaussian case, this approach corresponds to $\ell_1$-penalized maximum likelihood, and the structure of $\Theta^*$ is specified by the graph of an associated Gaussian Markov random field. We analyze the performance of this estimator under high-dimensional scaling, in which the number of nodes in the graph $p$, the number of edges $s$ and the maximum node degree $d$, are allowed to grow as a function of the sample size $n$. In addition to the parameters $(p,s,d)$, our analysis identifies other key quantities covariance matrix $\Sigma^*$; and (b) the $\ell_\infty$ operator norm of the sub-matrix $\Gamma^*_{S S}$, where $S$ indexes the graph edges, and $\Gamma^* = (\Theta^*)^{-1} \otimes (\Theta^*)^{-1}$; and (c) a mutual incoherence or irrepresentability measure on the matrix $\Gamma^*$ and (d) the rate of decay $1/f(n,\delta)$ on the probabilities $ \{|\hat{\Sigma}^n_{ij}- \Sigma^*_{ij}| > \delta \}$, where $\hat{\Sigma}^n$ is the sample covariance based on $n$ samples. Our first result establishes consistency of our estimate $\hat{\Theta}$ in the elementwise maximum-norm. This in turn allows us to derive convergence rates in Frobenius and spectral norms, with improvements upon existing results for graphs with maximum node degrees $d = o(\sqrt{s})$. In our second result, we show that with probability converging to one, the estimate $\hat{\Theta}$ correctly specifies the zero pattern of the concentration matrix $\Theta^*$.