 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Digital Twin Generation Through a Novel Simulation Framework and Quantitative Benchmarking
Feb 11, 2026The generation of 3D models from real-world objects has often been accomplished through photogrammetry, i.e., by taking 2D photos from a variety of perspectives and then triangulating matched point-based features to create a textured mesh. Many design choices exist within this framework for the generation of digital twins, and differences between such approaches are largely judged qualitatively. Here, we present and test a novel pipeline for generating synthetic images from high-quality 3D models and programmatically generated camera poses. This enables a wide variety of repeatable, quantifiable experiments which can compare ground-truth knowledge of virtual camera parameters and of virtual objects against the reconstructed estimations of those perspectives and subjects.
Presentation and Analysis of a Multimodal Dataset for Grounded LanguageLearning
Jul 31, 2020
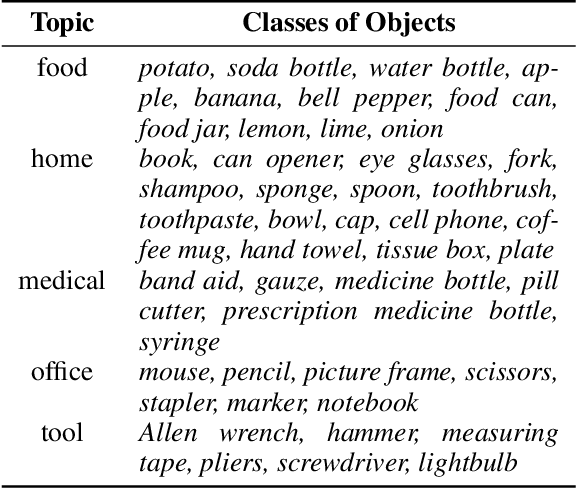


Grounded language acquisition -- learning how language-based interactions refer to the world around them -- is amajor area of research in robotics, NLP, and HCI. In practice the data used for learning consists almost entirely of textual descriptions, which tend to be cleaner, clearer, and more grammatical than actual human interactions. In this work, we present the Grounded Language Dataset (GoLD), a multimodal dataset of common household objects described by people using either spoken or written language. We analyze the differences and present an experiment showing how the different modalities affect language learning from human in-put. This will enable researchers studying the intersection of robotics, NLP, and HCI to better investigate how the multiple modalities of image, text, and speech interact, as well as show differences in the vernacular of these modalities impact results.