 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024



We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning
May 01, 2022
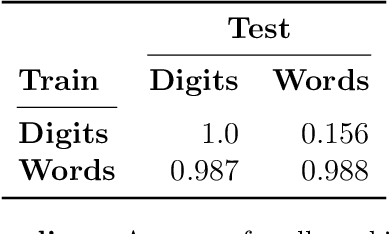

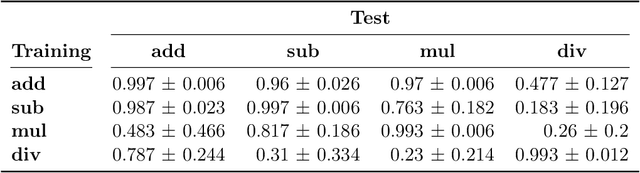
Huge language models (LMs) have ushered in a new era for AI, serving as a gateway to natural-language-based knowledge tasks. Although an essential element of modern AI, LMs are also inherently limited in a number of ways. We discuss these limitations and how they can be avoided by adopting a systems approach. Conceptualizing the challenge as one that involves knowledge and reasoning in addition to linguistic processing, we define a flexible architecture with multiple neural models, complemented by discrete knowledge and reasoning modules. We describe this neuro-symbolic architecture, dubbed the Modular Reasoning, Knowledge and Language (MRKL, pronounced "miracle") system, some of the technical challenges in implementing it, and Jurassic-X, AI21 Labs' MRKL system implementation.
Learning to Retrieve Passages without Supervision
Dec 14, 2021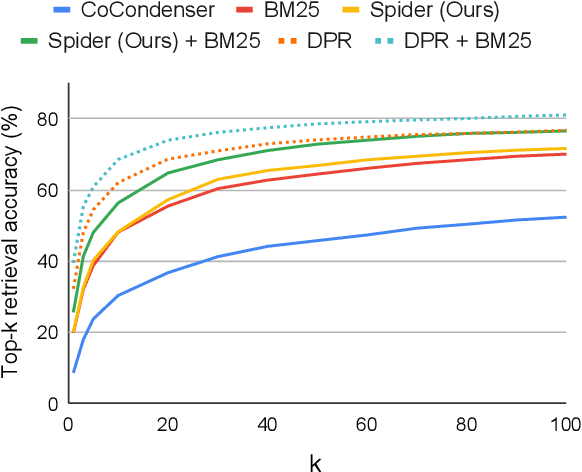
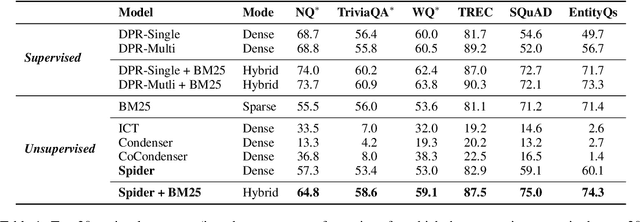
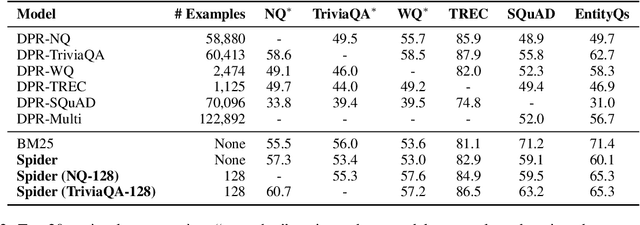
Dense retrievers for open-domain question answering (ODQA) have been shown to achieve impressive performance by training on large datasets of question-passage pairs. We investigate whether dense retrievers can be learned in a self-supervised fashion, and applied effectively without any annotations. We observe that existing pretrained models for retrieval struggle in this scenario, and propose a new pretraining scheme designed for retrieval: recurring span retrieval. We use recurring spans across passages in a document to create pseudo examples for contrastive learning. The resulting model -- Spider -- performs surprisingly well without any examples on a wide range of ODQA datasets, and is competitive with BM25, a strong sparse baseline. In addition, Spider often outperforms strong baselines like DPR trained on Natural Questions, when evaluated on questions from other datasets. Our hybrid retriever, which combines Spider with BM25, improves over its components across all datasets, and is often competitive with in-domain DPR models, which are trained on tens of thousands of examples.
A Theoretical Analysis of Fine-tuning with Linear Teachers
Jul 04, 2021
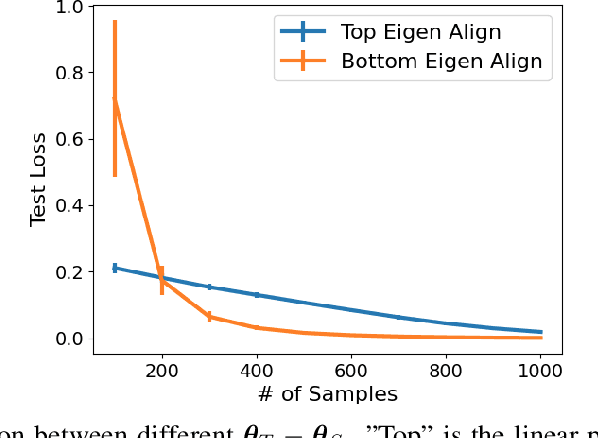
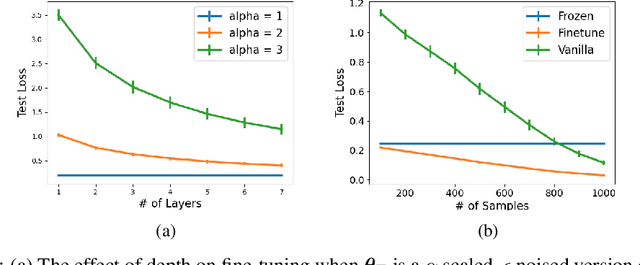
Fine-tuning is a common practice in deep learning, achieving excellent generalization results on downstream tasks using relatively little training data. Although widely used in practice, it is lacking strong theoretical understanding. We analyze the sample complexity of this scheme for regression with linear teachers in several architectures. Intuitively, the success of fine-tuning depends on the similarity between the source tasks and the target task, however measuring it is non trivial. We show that a relevant measure considers the relation between the source task, the target task and the covariance structure of the target data. In the setting of linear regression, we show that under realistic settings a substantial sample complexity reduction is plausible when the above measure is low. For deep linear regression, we present a novel result regarding the inductive bias of gradient-based training when the network is initialized with pretrained weights. Using this result we show that the similarity measure for this setting is also affected by the depth of the network. We further present results on shallow ReLU models, and analyze the dependence of sample complexity there on source and target tasks. We empirically demonstrate our results for both synthetic and realistic data.