 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-based Flood Forecasting: Advances in Scale, Accuracy and Reach
Dec 06, 2020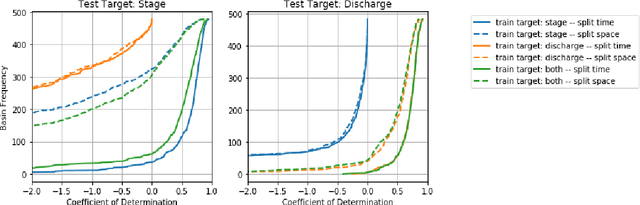
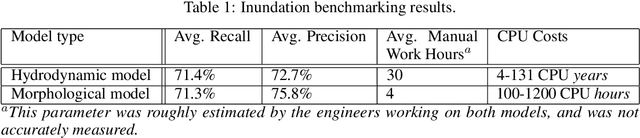
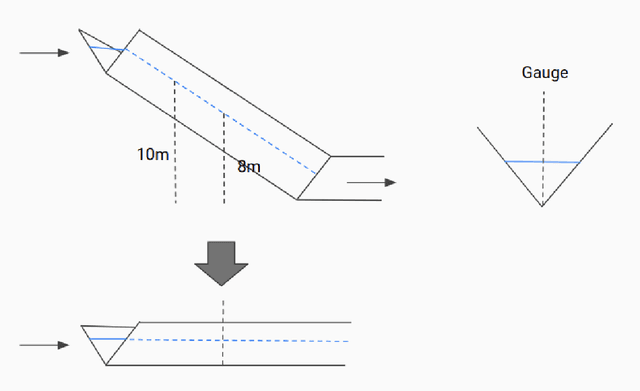
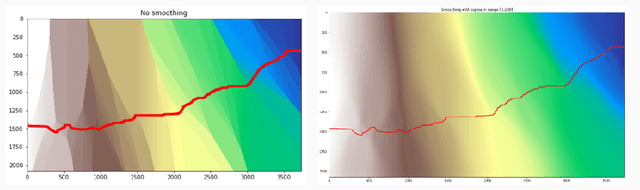
Floods are among the most common and deadly natural disasters in the world, and flood warning systems have been shown to be effective in reducing harm. Yet the majority of the world's vulnerable population does not have access to reliable and actionable warning systems, due to core challenges in scalability, computational costs, and data availability. In this paper we present two components of flood forecasting systems which were developed over the past year, providing access to these critical systems to 75 million people who didn't have this access before.
HydroNets: Leveraging River Structure for Hydrologic Modeling
Jul 01, 2020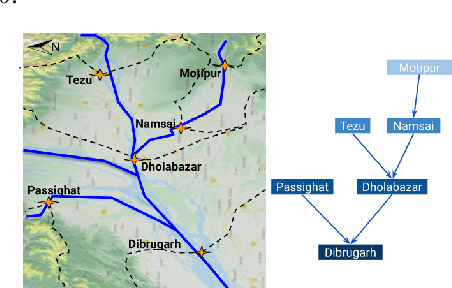
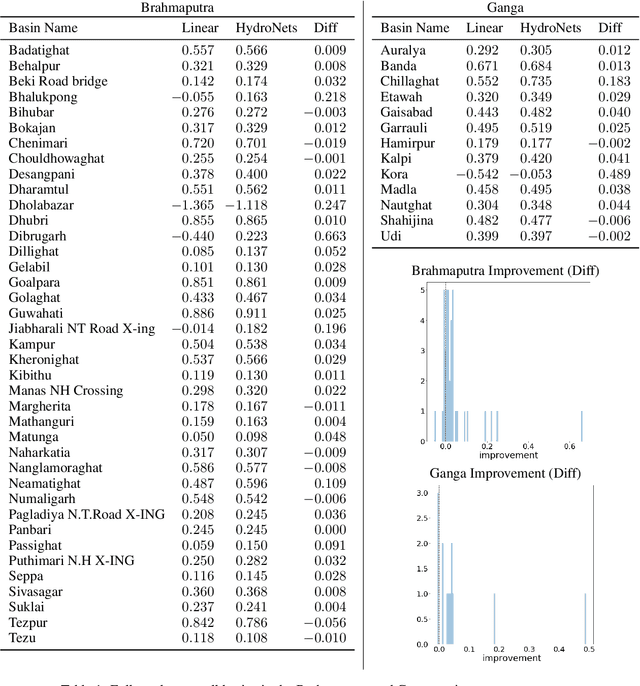
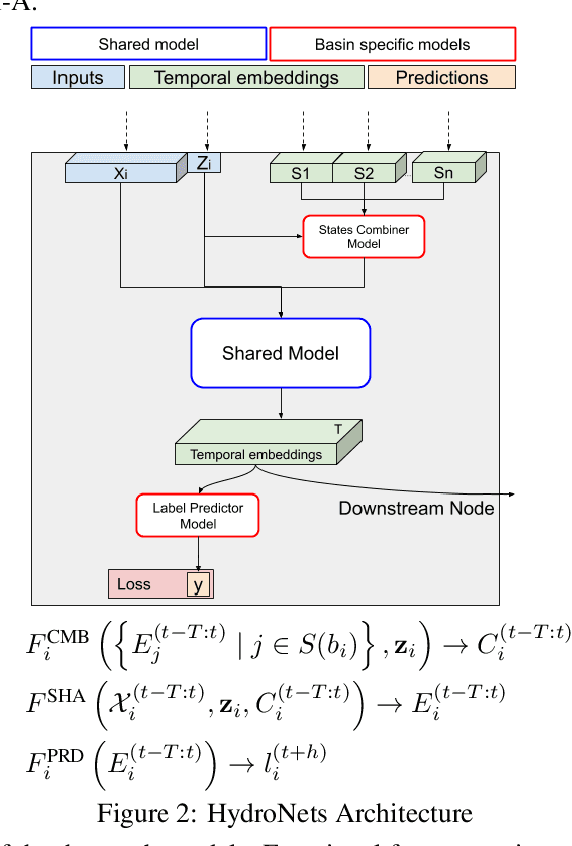
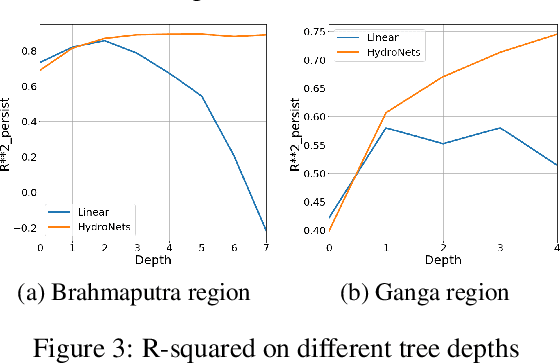
Accurate and scalable hydrologic models are essential building blocks of several important applications, from water resource management to timely flood warnings. However, as the climate changes, precipitation and rainfall-runoff pattern variations become more extreme, and accurate training data that can account for the resulting distributional shifts become more scarce. In this work we present a novel family of hydrologic models, called HydroNets, which leverages river network structure. HydroNets are deep neural network models designed to exploit both basin specific rainfall-runoff signals, and upstream network dynamics, which can lead to improved predictions at longer horizons. The injection of the river structure prior knowledge reduces sample complexity and allows for scalable and more accurate hydrologic modeling even with only a few years of data. We present an empirical study over two large basins in India that convincingly support the proposed model and its advantages.
DNF-Net: A Neural Architecture for Tabular Data
Jun 11, 2020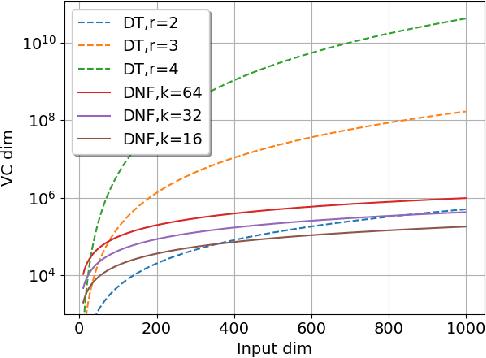
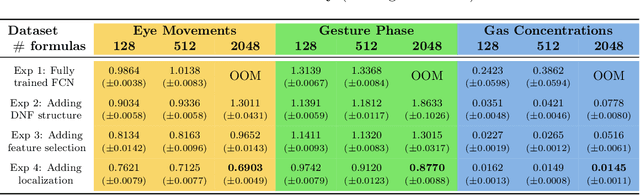
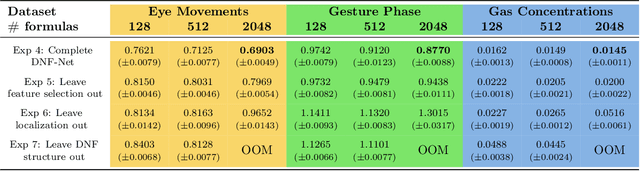
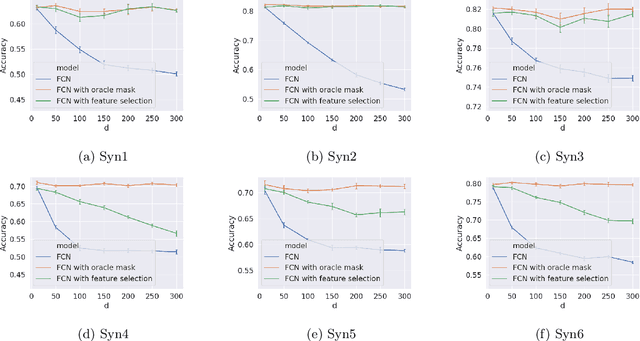
A challenging open question in deep learning is how to handle tabular data. Unlike domains such as image and natural language processing, where deep architectures prevail, there is still no widely accepted neural architecture that dominates tabular data. As a step toward bridging this gap, we present DNF-Net a novel generic architecture whose inductive bias elicits models whose structure corresponds to logical Boolean formulas in disjunctive normal form (DNF) over affine soft-threshold decision terms. In addition, DNF-Net promotes localized decisions that are taken over small subsets of the features. We present an extensive empirical study showing that DNF-Nets significantly and consistently outperform FCNs over tabular data. With relatively few hyperparameters, DNF-Nets open the door to practical end-to-end handling of tabular data using neural networks. We present ablation studies, which justify the design choices of DNF-Net including the three inductive bias elements, namely, Boolean formulation, locality, and feature selection.
Normalizing Flow Regression
Apr 21, 2020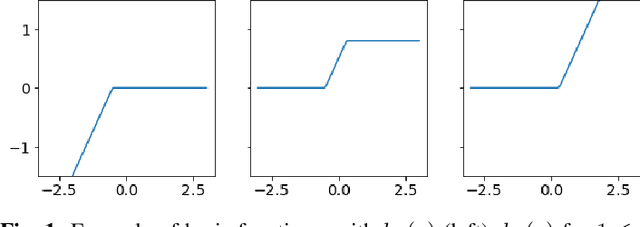
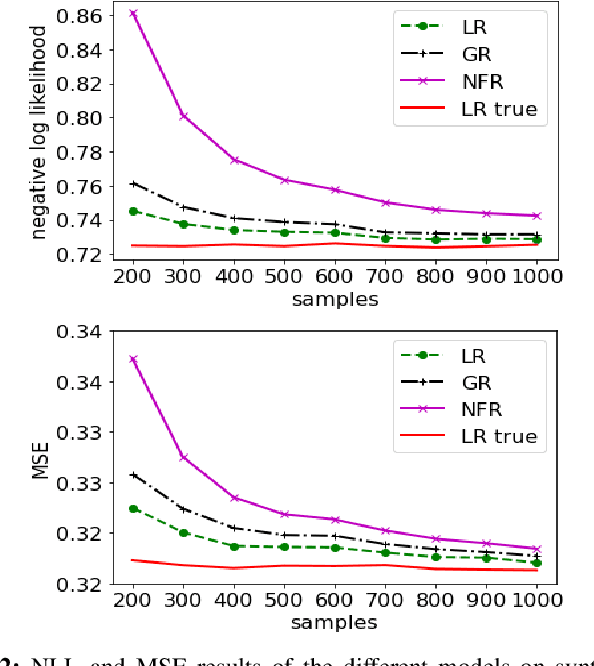
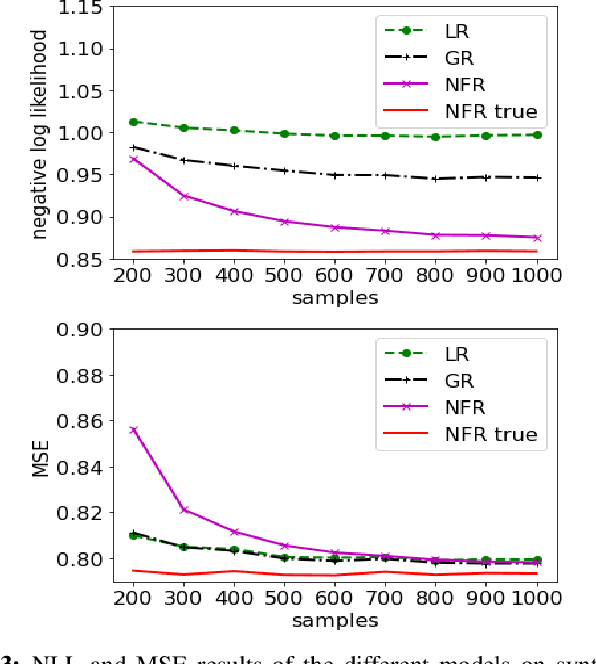
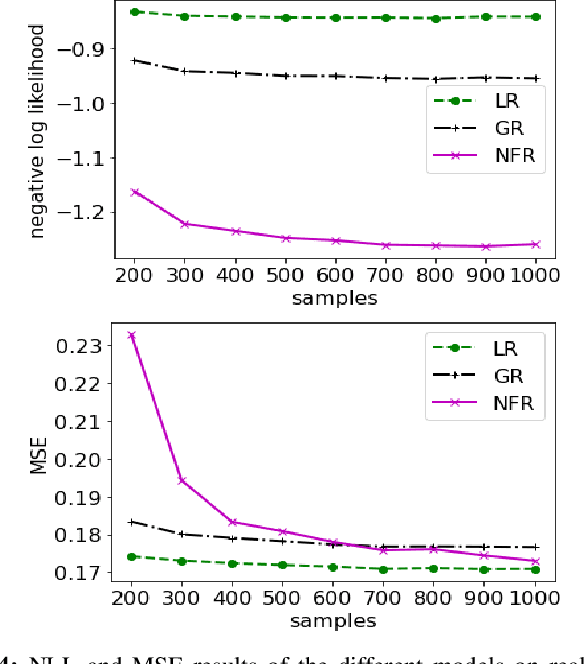
In this letter we propose a convex approach to learning expressive scalar conditional distributions. The model denoted by Normalizing Flow Regression (NFR) is inspired by deep normalizing flow networks but is convex due to the use of a dictionary of pre-defined transformations. By defining a rich enough dictionary, NFR generalizes the Gaussian posterior associated with linear regression to an arbitrary conditional distribution. In the special case of piece wise linear dictionary, we also provide a closed form solution for the conditional mean. We demonstrate the advantages of NFR over competitors using synthetic data as well as real world data.
Improved Detection of Adversarial Attacks via Penetration Distortion Maximization
Nov 03, 2019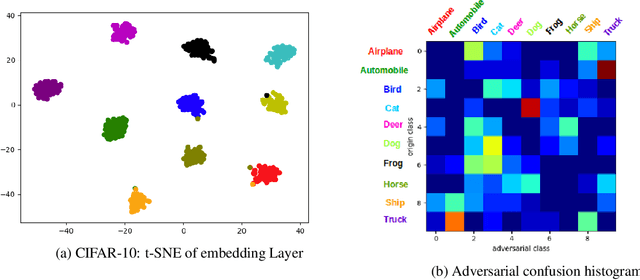
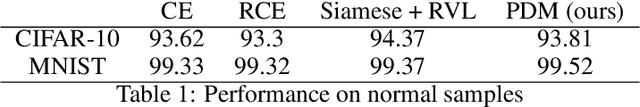
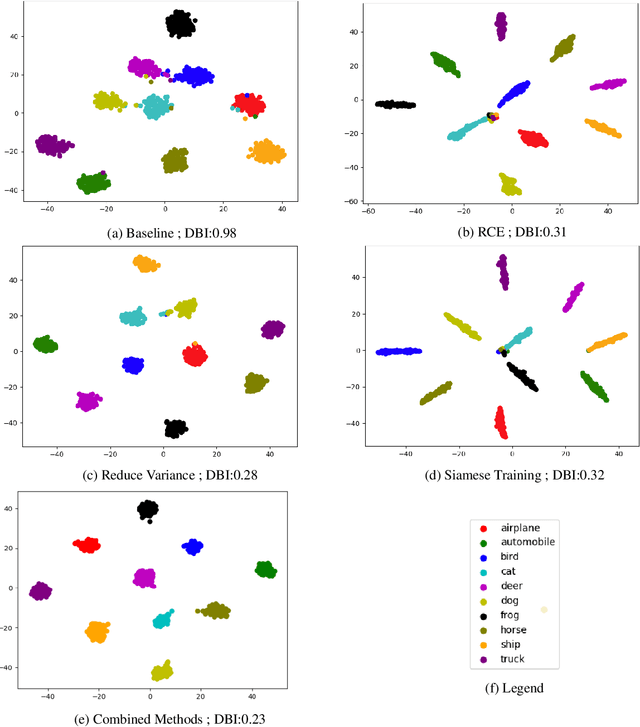
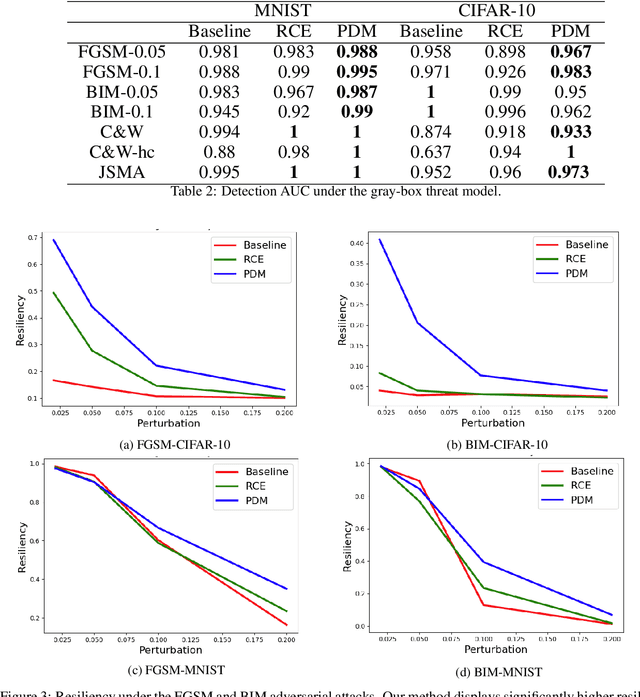
This paper is concerned with the defense of deep models against adversarial attacks. We developan adversarial detection method, which is inspired by the certificate defense approach, and capturesthe idea of separating class clusters in the embedding space to increase the margin. The resultingdefense is intuitive, effective, scalable, and can be integrated into any given neural classificationmodel. Our method demonstrates state-of-the-art (detection) performance under all threat models.
Spectral Algorithm for Low-rank Multitask Regression
Oct 27, 2019

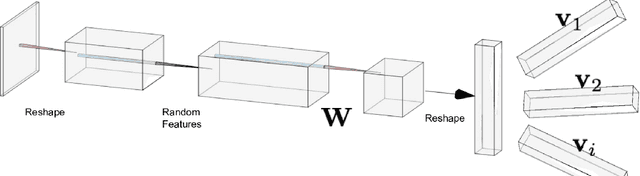
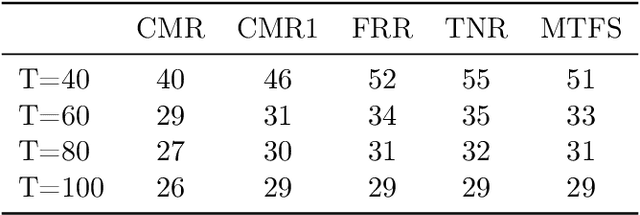
Multitask learning, i.e. taking advantage of the relatedness of individual tasks in order to improve performance on all of them, is a core challenge in the field of machine learning. We focus on matrix regression tasks where the rank of the weight matrix is constrained to reduce sample complexity. We introduce the common mechanism regression (CMR) model which assumes a shared left low-rank component across all tasks, but allows an individual per-task right low-rank component. This dramatically reduces the number of samples needed for accurate estimation. The problem of jointly recovering the common and the local components has a non-convex bi-linear structure. We overcome this hurdle and provide a provably beneficial non-iterative spectral algorithm. Appealingly, the solution has favorable behavior as a function of the number of related tasks and the small number of samples available for each one. We demonstrate the efficacy of our approach for the challenging task of remote river discharge estimation across multiple river sites, where data for each task is naturally scarce. In this scenario sharing a low-rank component between the tasks translates to a shared spectral reflection of the water, which is a true underlying physical model. We also show the benefit of the approach on the markedly different setting of image classification where the common component can be interpreted as the shared convolution filters.
ML for Flood Forecasting at Scale
Jan 28, 2019Effective riverine flood forecasting at scale is hindered by a multitude of factors, most notably the need to rely on human calibration in current methodology, the limited amount of data for a specific location, and the computational difficulty of building continent/global level models that are sufficiently accurate. Machine learning (ML) is primed to be useful in this scenario: learned models often surpass human experts in complex high-dimensional scenarios, and the framework of transfer or multitask learning is an appealing solution for leveraging local signals to achieve improved global performance. We propose to build on these strengths and develop ML systems for timely and accurate riverine flood prediction.
Towards Global Remote Discharge Estimation: Using the Few to Estimate The Many
Jan 03, 2019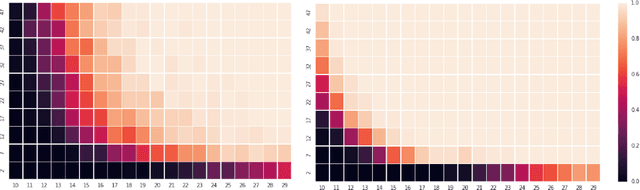
Learning hydrologic models for accurate riverine flood prediction at scale is a challenge of great importance. One of the key difficulties is the need to rely on in-situ river discharge measurements, which can be quite scarce and unreliable, particularly in regions where floods cause the most damage every year. Accordingly, in this work we tackle the problem of river discharge estimation at different river locations. A core characteristic of the data at hand (e.g. satellite measurements) is that we have few measurements for many locations, all sharing the same physics that underlie the water discharge. We capture this scenario in a simple but powerful common mechanism regression (CMR) model with a local component as well as a shared one which captures the global discharge mechanism. The resulting learning objective is non-convex, but we show that we can find its global optimum by leveraging the power of joining local measurements across sites. In particular, using a spectral initialization with provable near-optimal accuracy, we can find the optimum using standard descent methods. We demonstrate the efficacy of our approach for the problem of discharge estimation using simulations.
Learning with Rules
May 22, 2018
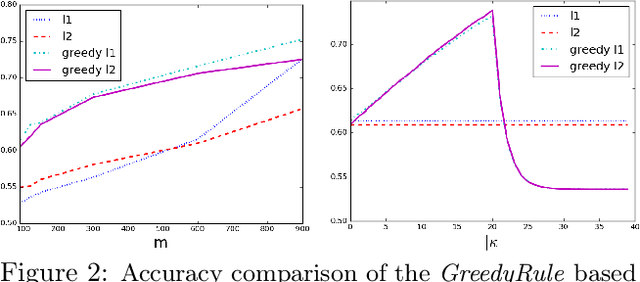

Complex classifiers may exhibit "embarassing" failures in cases where a human can easily provide a justified classification. Avoiding such failures is obviously of key importance. In this work, we focus on one such setting, where a label is perfectly predictable if the input contains certain features, and otherwise it is predictable by a linear classifier. We define a hypothesis class that captures this notion and determine its sample complexity. We also give evidence that efficient algorithms cannot achieve this sample complexity. We then derive a simple and efficient algorithm and give evidence that its sample complexity is optimal, among efficient algorithms. Experiments on synthetic and sentiment analysis data demonstrate the efficacy of the method, both in terms of accuracy and interpretability.
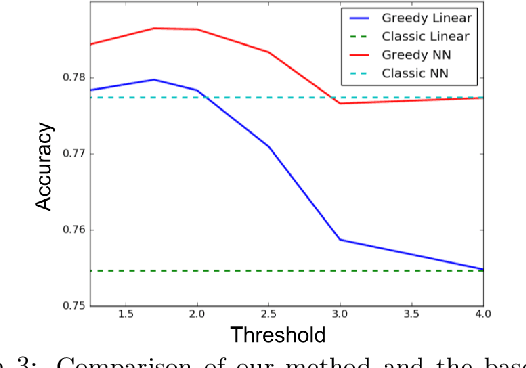
Scalable Learning of Non-Decomposable Objectives
Mar 01, 2017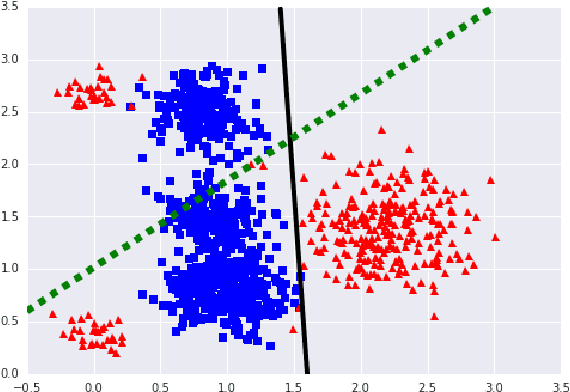
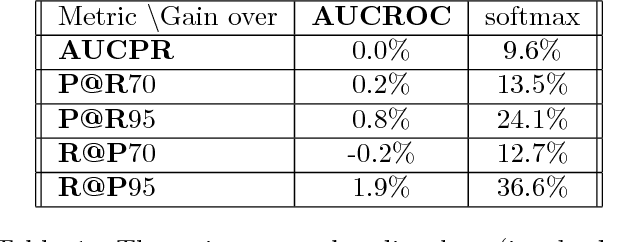
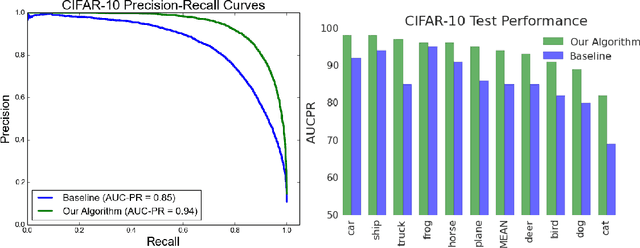
Modern retrieval systems are often driven by an underlying machine learning model. The goal of such systems is to identify and possibly rank the few most relevant items for a given query or context. Thus, such systems are typically evaluated using a ranking-based performance metric such as the area under the precision-recall curve, the $F_\beta$ score, precision at fixed recall, etc. Obviously, it is desirable to train such systems to optimize the metric of interest. In practice, due to the scalability limitations of existing approaches for optimizing such objectives, large-scale retrieval systems are instead trained to maximize classification accuracy, in the hope that performance as measured via the true objective will also be favorable. In this work we present a unified framework that, using straightforward building block bounds, allows for highly scalable optimization of a wide range of ranking-based objectives. We demonstrate the advantage of our approach on several real-life retrieval problems that are significantly larger than those considered in the literature, while achieving substantial improvement in performance over the accuracy-objective baseline.