 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Variational Block-Sparse Bayesian Learning
Jun 01, 2023


We present a fast update rule for variational block-sparse Bayesian learning (SBL) methods. Using a variational Bayesian framework, we show how repeated updates of probability density functions (PDFs) of the prior variances and weights can be expressed as a nonlinear first-order recurrence from one estimate of the parameters of the proxy PDFs to the next. Specifically, the recurrent relation turns out to be a strictly increasing rational function for many commonly used prior PDFs of the variances, such as Jeffrey's prior. Hence, the fixed points of this recurrent relation can be obtained by solving for the roots of a polynomial. This scheme allows to check for convergence/divergence of individual prior variances in a single step. Thereby, the the computational complexity of the variational block-SBL algorithm is reduced and the convergence speed is improved by two orders of magnitude in our simulations. Furthermore, the solution allows insights into the sparsity of the estimators obtained by choosing different priors.
Self-attention for Enhanced OAMP Detection in MIMO Systems
Mar 14, 2023Multiple-Input Multiple-Output (MIMO) systems are essential for wireless communications. Sinceclassical algorithms for symbol detection in MIMO setups require large computational resourcesor provide poor results, data-driven algorithms are becoming more popular. Most of the proposedalgorithms, however, introduce approximations leading to degraded performance for realistic MIMOsystems. In this paper, we introduce a neural-enhanced hybrid model, augmenting the analyticbackbone algorithm with state-of-the-art neural network components. In particular, we introduce aself-attention model for the enhancement of the iterative Orthogonal Approximate Message Passing(OAMP)-based decoding algorithm. In our experiments, we show that the proposed model canoutperform existing data-driven approaches for OAMP while having improved generalization to otherSNR values at limited computational overhead.
Variational Inference of Structured Line Spectra Exploiting Group-Sparsity
Mar 06, 2023



In this paper, we present a variational inference algorithm that decomposes a signal into multiple groups of related spectral lines. The spectral lines in each group are associated with a group parameter common to all spectral lines within the group. The proposed algorithm jointly estimates the group parameters, the number of spetral lines within a group, and the number of groups exploiting a Bernoulli-Gamma-Gaussian hierarchical prior model which promotes sparse solutions. Aiming to maximize the evidence lower bound (ELBO), variational inference provides analytic approximations of the posterior probability density functions (PDFs) and also gives estimates of the additional model parameters such as the measurement noise variance. While the activation variables of the groups and the associated group parameters (such as fundamental frequencies and the corresponding higher order harmonics) are estimated as point estimates, the remaining parameters such as the complex amplitudes of the spectral lines and their precision parameters are estimated as approximate posterior PDFs. We demonstrate the versatility and performance of the proposed algorithm on three different inference problems. In particular, the proposed algorithm is applied to the multi-pitch estimation problem, the radar signal-based extended object estimation problem, and variational mode decomposition (VMD) using synthetic measurements and to real multi-pitch estimation problem using the Bach-10 dataset. The results show that the proposed algorithm outperforms state-of-the-art model-based and pre-trained algorithms on all three inference problems.
Variational Message Passing-based Respiratory Motion Estimation and Detection Using Radar Signals
Oct 14, 2022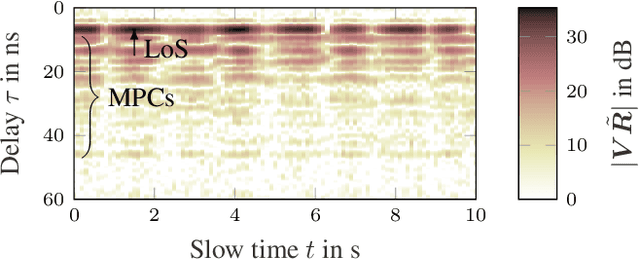
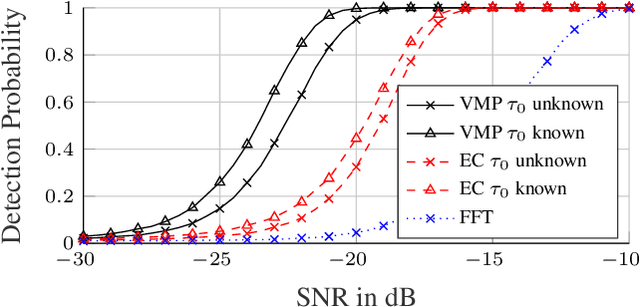
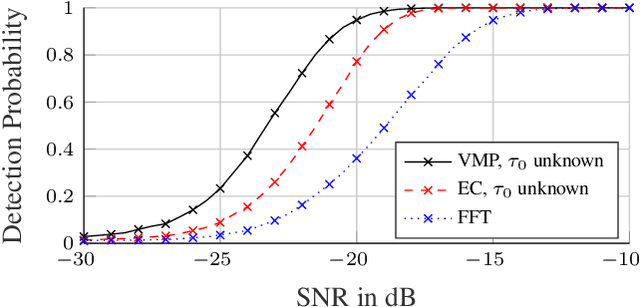
We present a variational message passing (VMP) approach to detect the presence of a person based on their respiratory chest motion using ultra-wideband (UWB) radar and to estimate the respiratory motion for contact-free vital sign monitoring. The received signal is modeled by a backscatter channel. The respiratory motion and propagation channel are estimated using VMP, while the presence of a person is detected by the evidence lower bound (ELBO). Numerical analyses and measurements demonstrate that the proposed method leads to a significant improvement in the detection performance compared to a fast fourier transform (FFT)-based detector or an estimator-correlator, since the multipath components (MPCs) are better incorporated into the detection procedure. Specifically, the proposed method has a detection probability of 0.95 at -20 dB signal-to-noise ratio (SNR), while the estimator-correlator and FFT-based detector have 0.32 and 0.05, respectively.
Active Bayesian Causal Inference
Jun 04, 2022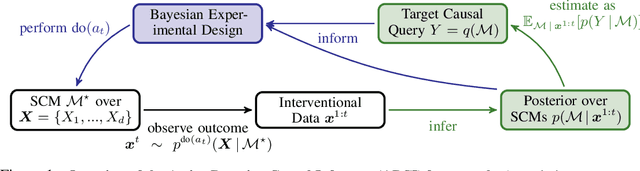

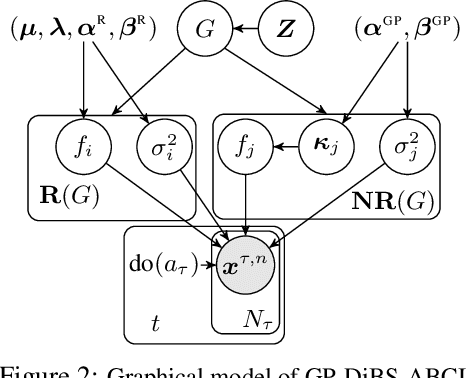
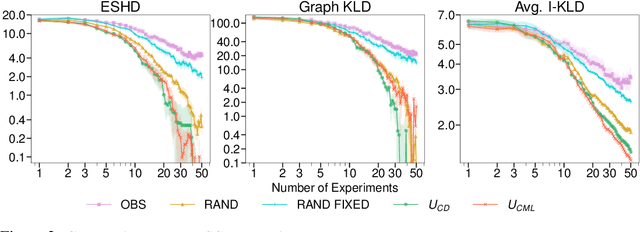
Causal discovery and causal reasoning are classically treated as separate and consecutive tasks: one first infers the causal graph, and then uses it to estimate causal effects of interventions. However, such a two-stage approach is uneconomical, especially in terms of actively collected interventional data, since the causal query of interest may not require a fully-specified causal model. From a Bayesian perspective, it is also unnatural, since a causal query (e.g., the causal graph or some causal effect) can be viewed as a latent quantity subject to posterior inference -- other unobserved quantities that are not of direct interest (e.g., the full causal model) ought to be marginalized out in this process and contribute to our epistemic uncertainty. In this work, we propose Active Bayesian Causal Inference (ABCI), a fully-Bayesian active learning framework for integrated causal discovery and reasoning, which jointly infers a posterior over causal models and queries of interest. In our approach to ABCI, we focus on the class of causally-sufficient, nonlinear additive noise models, which we model using Gaussian processes. We sequentially design experiments that are maximally informative about our target causal query, collect the corresponding interventional data, and update our beliefs to choose the next experiment. Through simulations, we demonstrate that our approach is more data-efficient than several baselines that only focus on learning the full causal graph. This allows us to accurately learn downstream causal queries from fewer samples while providing well-calibrated uncertainty estimates for the quantities of interest.
Explainable Machine Learning for Breakdown Prediction in High Gradient RF Cavities
Feb 10, 2022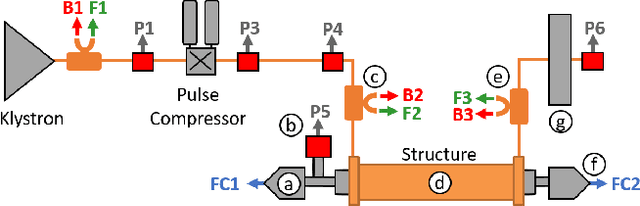
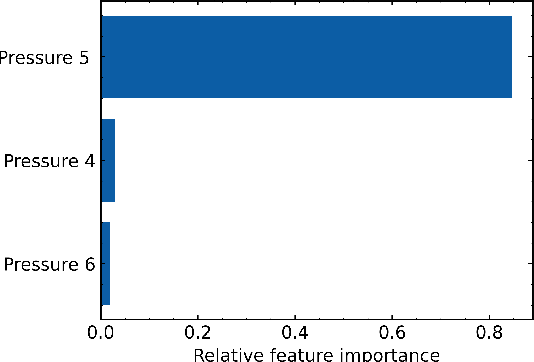


Radio Frequency (RF) breakdowns are one of the most prevalent limiting factors in RF cavities for particle accelerators. During a breakdown, field enhancement associated with small deformations on the cavity surface results in electrical arcs. Such arcs lead to beam aborts, reduce machine availability and can cause irreparable damage on the RF cavity surface. In this paper, we propose a machine learning strategy to discover breakdown precursors in CERN's Compact Linear Collider (CLIC) accelerating structures. By interpreting the parameters of the learned models with explainable Artificial Intelligence (AI), we reverse-engineer physical properties for deriving fast, reliable, and simple rule based models. Based on 6 months of historical data and dedicated experiments, our models show fractions of data with high influence on the occurrence of breakdowns. Specifically, it is shown that in many cases a rise of the vacuum pressure is observed before a breakdown is detected with the current interlock sensors.
Resource-efficient Deep Neural Networks for Automotive Radar Interference Mitigation
Jan 25, 2022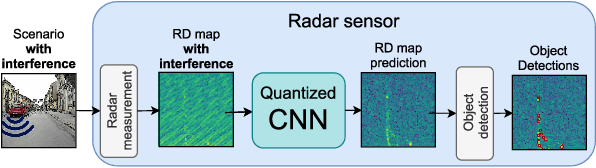
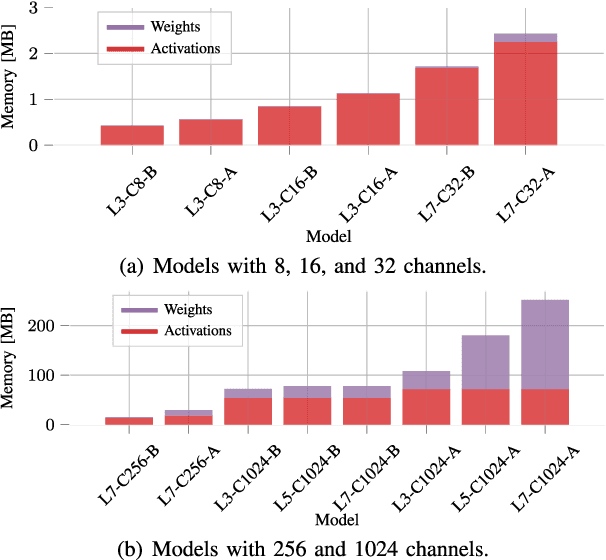
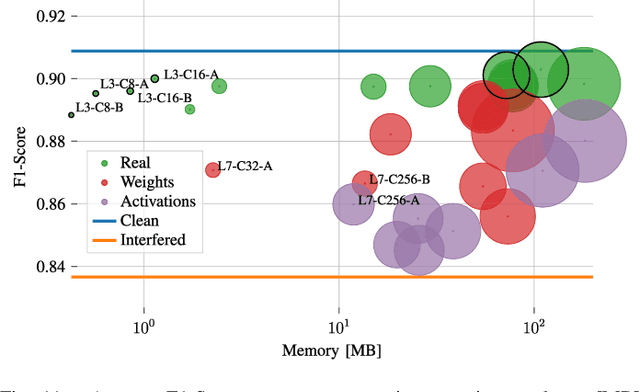
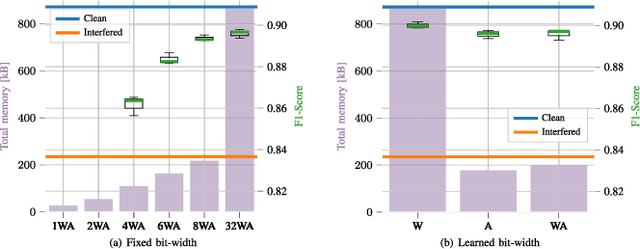
Radar sensors are crucial for environment perception of driver assistance systems as well as autonomous vehicles. With a rising number of radar sensors and the so far unregulated automotive radar frequency band, mutual interference is inevitable and must be dealt with. Algorithms and models operating on radar data are required to run the early processing steps on specialized radar sensor hardware. This specialized hardware typically has strict resource-constraints, i.e. a low memory capacity and low computational power. Convolutional Neural Network (CNN)-based approaches for denoising and interference mitigation yield promising results for radar processing in terms of performance. Regarding resource-constraints, however, CNNs typically exceed the hardware's capacities by far. In this paper we investigate quantization techniques for CNN-based denoising and interference mitigation of radar signals. We analyze the quantization of (i) weights and (ii) activations of different CNN-based model architectures. This quantization results in reduced memory requirements for model storage and during inference. We compare models with fixed and learned bit-widths and contrast two different methodologies for training quantized CNNs, i.e. the straight-through gradient estimator and training distributions over discrete weights. We illustrate the importance of structurally small real-valued base models for quantization and show that learned bit-widths yield the smallest models. We achieve a memory reduction of around 80\% compared to the real-valued baseline. Due to practical reasons, however, we recommend the use of 8 bits for weights and activations, which results in models that require only 0.2 megabytes of memory.
* 15 pages; published in IEEE Journal of Selected Topics in Signal Processing, Special Issue on Recent Advances in Automotive Radar Signal Processing, Volume: 15, Issue: 4, June 2021. arXiv admin note: text overlap with arXiv:2011.12706
Distribution Mismatch Correction for Improved Robustness in Deep Neural Networks
Oct 05, 2021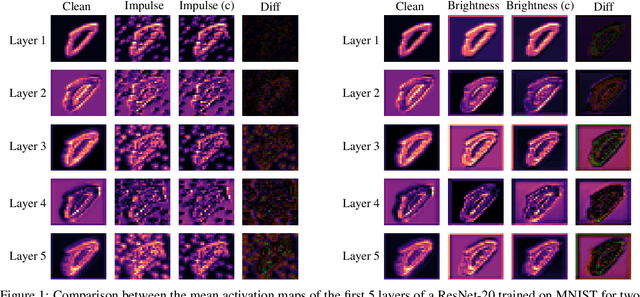
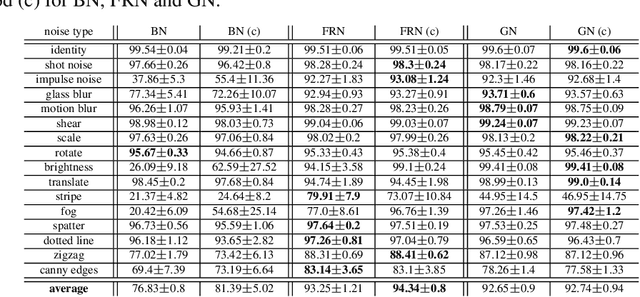
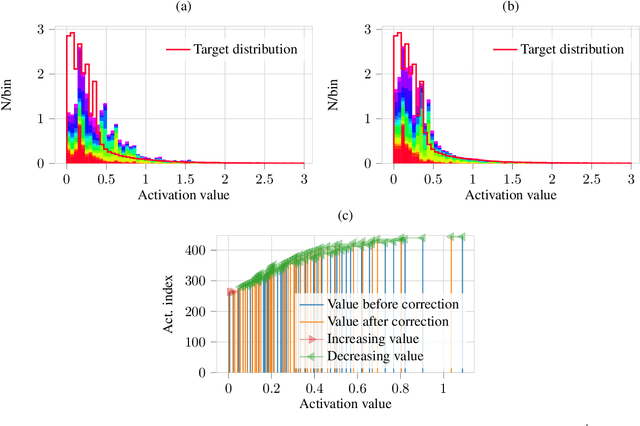
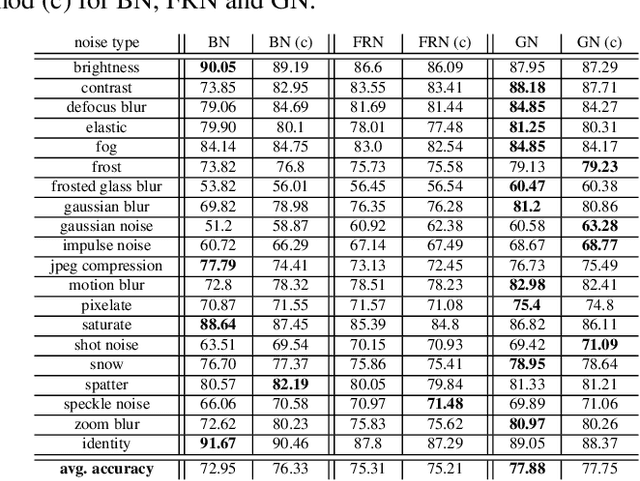
Deep neural networks rely heavily on normalization methods to improve their performance and learning behavior. Although normalization methods spurred the development of increasingly deep and efficient architectures, they also increase the vulnerability with respect to noise and input corruptions. In most applications, however, noise is ubiquitous and diverse; this can often lead to complete failure of machine learning systems as they fail to cope with mismatches between the input distribution during training- and test-time. The most common normalization method, batch normalization, reduces the distribution shift during training but is agnostic to changes in the input distribution during test time. This makes batch normalization prone to performance degradation whenever noise is present during test-time. Sample-based normalization methods can correct linear transformations of the activation distribution but cannot mitigate changes in the distribution shape; this makes the network vulnerable to distribution changes that cannot be reflected in the normalization parameters. We propose an unsupervised non-parametric distribution correction method that adapts the activation distribution of each layer. This reduces the mismatch between the training and test-time distribution by minimizing the 1-D Wasserstein distance. In our experiments, we empirically show that the proposed method effectively reduces the impact of intense image corruptions and thus improves the classification performance without the need for retraining or fine-tuning the model.
Lung Sound Classification Using Co-tuning and Stochastic Normalization
Aug 04, 2021
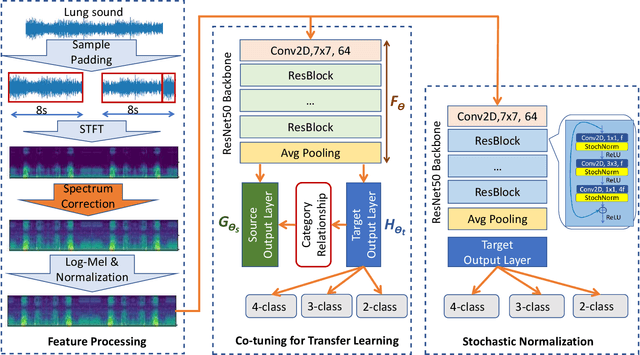
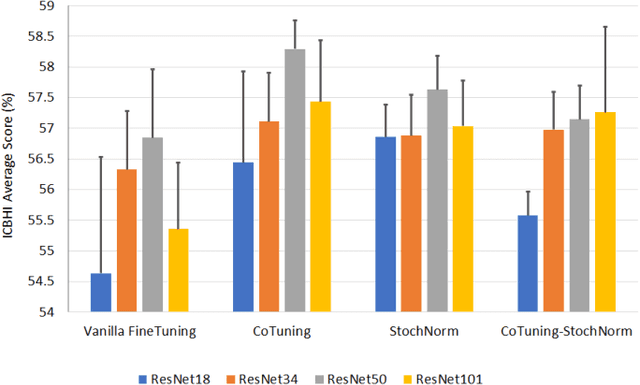
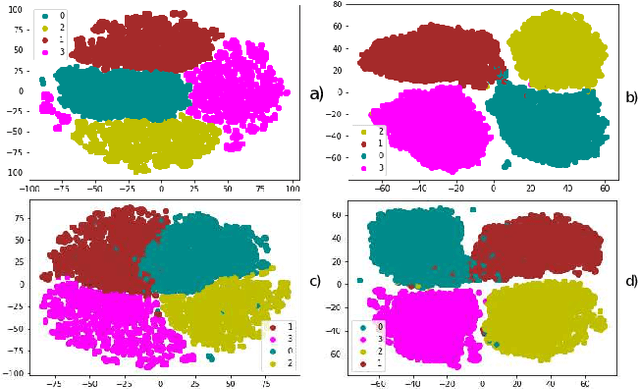
In this paper, we use pre-trained ResNet models as backbone architectures for classification of adventitious lung sounds and respiratory diseases. The knowledge of the pre-trained model is transferred by using vanilla fine-tuning, co-tuning, stochastic normalization and the combination of the co-tuning and stochastic normalization techniques. Furthermore, data augmentation in both time domain and time-frequency domain is used to account for the class imbalance of the ICBHI and our multi-channel lung sound dataset. Additionally, we apply spectrum correction to consider the variations of the recording device properties on the ICBHI dataset. Empirically, our proposed systems mostly outperform all state-of-the-art lung sound classification systems for the adventitious lung sounds and respiratory diseases of both datasets.
Crackle Detection In Lung Sounds Using Transfer Learning And Multi-Input Convolitional Neural Networks
Apr 30, 2021
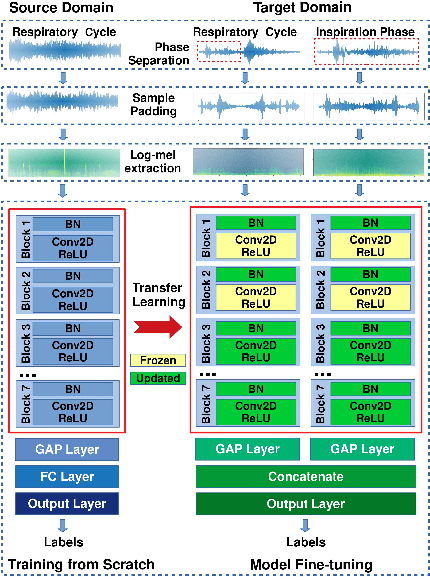
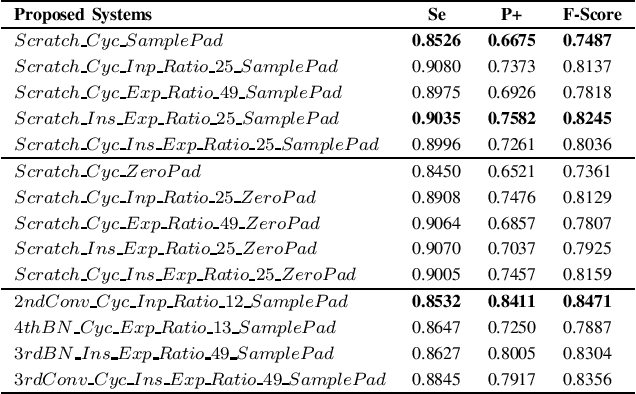
Large annotated lung sound databases are publicly available and might be used to train algorithms for diagnosis systems. However, it might be a challenge to develop a well-performing algorithm for small non-public data, which have only a few subjects and show differences in recording devices and setup. In this paper, we use transfer learning to tackle the mismatch of the recording setup. This allows us to transfer knowledge from one dataset to another dataset for crackle detection in lung sounds. In particular, a single input convolutional neural network (CNN) model is pre-trained on a source domain using ICBHI 2017, the largest publicly available database of lung sounds. We use log-mel spectrogram features of respiratory cycles of lung sounds. The pre-trained network is used to build a multi-input CNN model, which shares the same network architecture for respiratory cycles and their corresponding respiratory phases. The multi-input model is then fine-tuned on the target domain of our self-collected lung sound database for classifying crackles and normal lung sounds. Our experimental results show significant performance improvements of 9.84% (absolute) in F-score on the target domain using the multi-input CNN model based on transfer learning for crackle detection in adventitious lung sound classification task.