 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Influence-Augmented Local Simulators for Parallel MARL in Large Networked Systems
Jul 01, 2022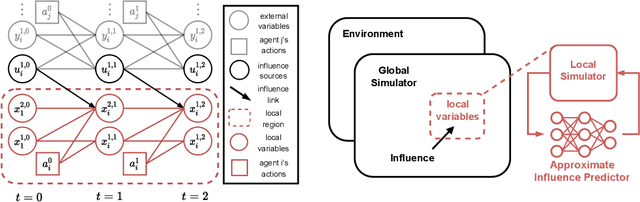
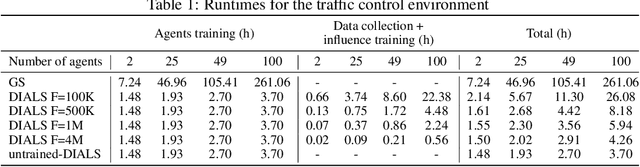
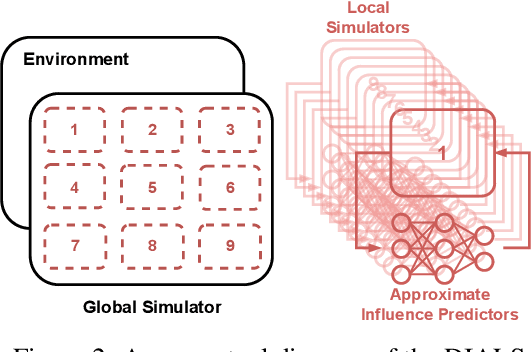
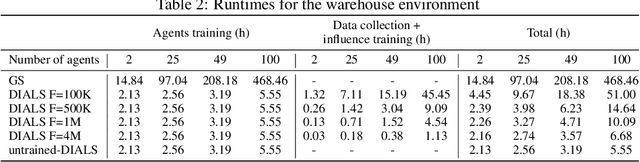
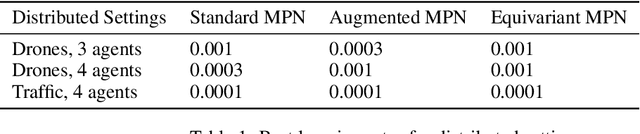
Due to its high sample complexity, simulation is, as of today, critical for the successful application of reinforcement learning. Many real-world problems, however, exhibit overly complex dynamics, which makes their full-scale simulation computationally slow. In this paper, we show how to decompose large networked systems of many agents into multiple local components such that we can build separate simulators that run independently and in parallel. To monitor the influence that the different local components exert on one another, each of these simulators is equipped with a learned model that is periodically trained on real trajectories. Our empirical results reveal that distributing the simulation among different processes not only makes it possible to train large multi-agent systems in just a few hours but also helps mitigate the negative effects of simultaneous learning.
On the Impossibility of Learning to Cooperate with Adaptive Partner Strategies in Repeated Games
Jun 20, 2022Learning to cooperate with other agents is challenging when those agents also possess the ability to adapt to our own behavior. Practical and theoretical approaches to learning in cooperative settings typically assume that other agents' behaviors are stationary, or else make very specific assumptions about other agents' learning processes. The goal of this work is to understand whether we can reliably learn to cooperate with other agents without such restrictive assumptions, which are unlikely to hold in real-world applications. Our main contribution is a set of impossibility results, which show that no learning algorithm can reliably learn to cooperate with all possible adaptive partners in a repeated matrix game, even if that partner is guaranteed to cooperate with some stationary strategy. Motivated by these results, we then discuss potential alternative assumptions which capture the idea that an adaptive partner will only adapt rationally to our behavior.
Best-Response Bayesian Reinforcement Learning with Bayes-adaptive POMDPs for Centaurs
Apr 03, 2022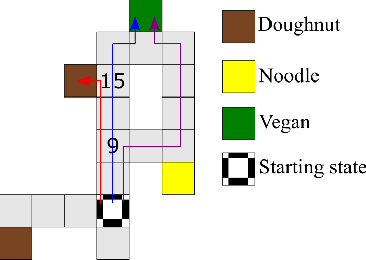
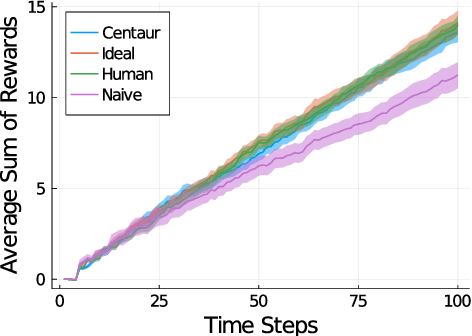
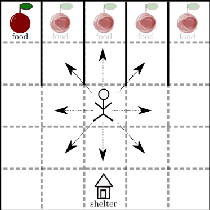
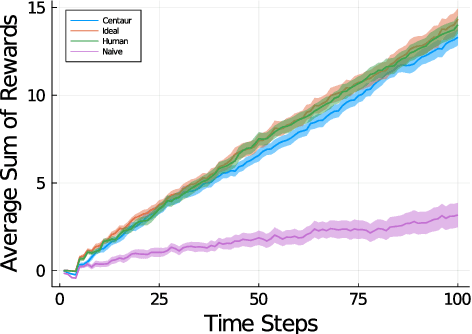
Centaurs are half-human, half-AI decision-makers where the AI's goal is to complement the human. To do so, the AI must be able to recognize the goals and constraints of the human and have the means to help them. We present a novel formulation of the interaction between the human and the AI as a sequential game where the agents are modelled using Bayesian best-response models. We show that in this case the AI's problem of helping bounded-rational humans make better decisions reduces to a Bayes-adaptive POMDP. In our simulated experiments, we consider an instantiation of our framework for humans who are subjectively optimistic about the AI's future behaviour. Our results show that when equipped with a model of the human, the AI can infer the human's bounds and nudge them towards better decisions. We discuss ways in which the machine can learn to improve upon its own limitations as well with the help of the human. We identify a novel trade-off for centaurs in partially observable tasks: for the AI's actions to be acceptable to the human, the machine must make sure their beliefs are sufficiently aligned, but aligning beliefs might be costly. We present a preliminary theoretical analysis of this trade-off and its dependence on task structure.
BADDr: Bayes-Adaptive Deep Dropout RL for POMDPs
Feb 17, 2022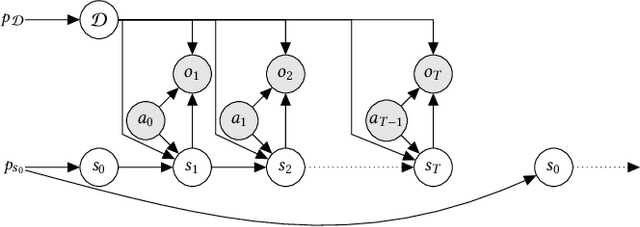

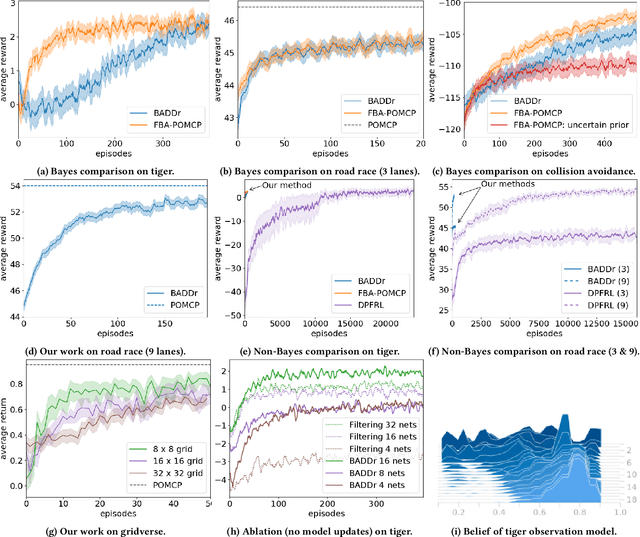

While reinforcement learning (RL) has made great advances in scalability, exploration and partial observability are still active research topics. In contrast, Bayesian RL (BRL) provides a principled answer to both state estimation and the exploration-exploitation trade-off, but struggles to scale. To tackle this challenge, BRL frameworks with various prior assumptions have been proposed, with varied success. This work presents a representation-agnostic formulation of BRL under partially observability, unifying the previous models under one theoretical umbrella. To demonstrate its practical significance we also propose a novel derivation, Bayes-Adaptive Deep Dropout rl (BADDr), based on dropout networks. Under this parameterization, in contrast to previous work, the belief over the state and dynamics is a more scalable inference problem. We choose actions through Monte-Carlo tree search and empirically show that our method is competitive with state-of-the-art BRL methods on small domains while being able to solve much larger ones.
Influence-Augmented Local Simulators: A Scalable Solution for Fast Deep RL in Large Networked Systems
Feb 03, 2022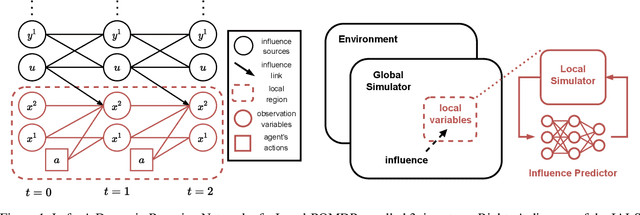
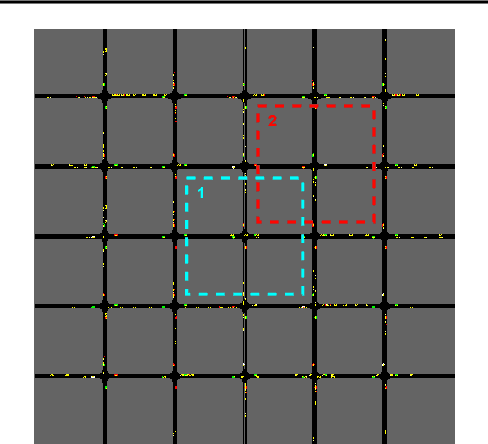
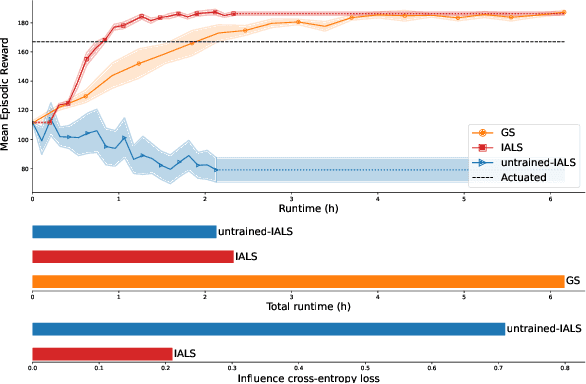

Learning effective policies for real-world problems is still an open challenge for the field of reinforcement learning (RL). The main limitation being the amount of data needed and the pace at which that data can be obtained. In this paper, we study how to build lightweight simulators of complicated systems that can run sufficiently fast for deep RL to be applicable. We focus on domains where agents interact with a reduced portion of a larger environment while still being affected by the global dynamics. Our method combines the use of local simulators with learned models that mimic the influence of the global system. The experiments reveal that incorporating this idea into the deep RL workflow can considerably accelerate the training process and presents several opportunities for the future.
Online Planning in POMDPs with Self-Improving Simulators
Jan 27, 2022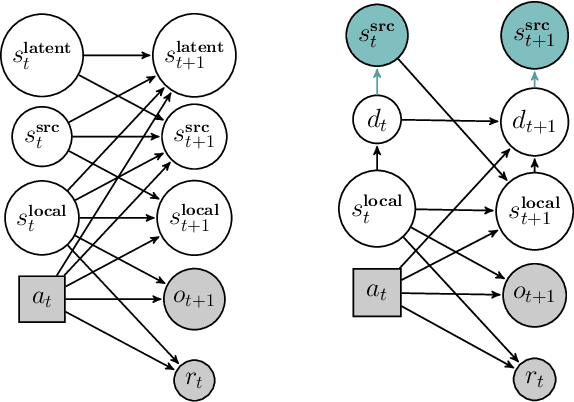

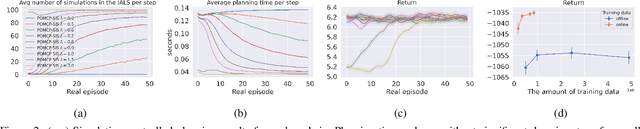

How can we plan efficiently in a large and complex environment when the time budget is limited? Given the original simulator of the environment, which may be computationally very demanding, we propose to learn online an approximate but much faster simulator that improves over time. To plan reliably and efficiently while the approximate simulator is learning, we develop a method that adaptively decides which simulator to use for every simulation, based on a statistic that measures the accuracy of the approximate simulator. This allows us to use the approximate simulator to replace the original simulator for faster simulations when it is accurate enough under the current context, thus trading off simulation speed and accuracy. Experimental results in two large domains show that when integrated with POMCP, our approach allows to plan with improving efficiency over time.
MORAL: Aligning AI with Human Norms through Multi-Objective Reinforced Active Learning
Dec 30, 2021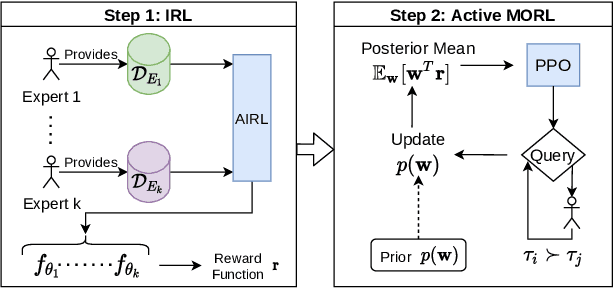
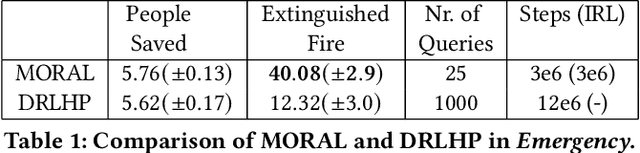
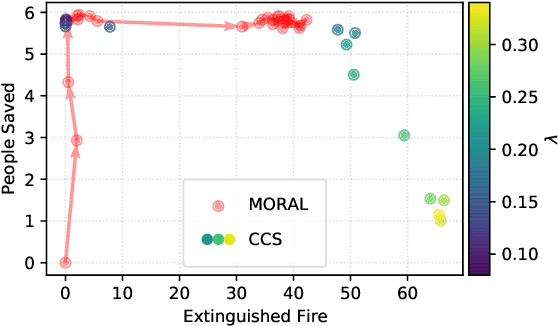
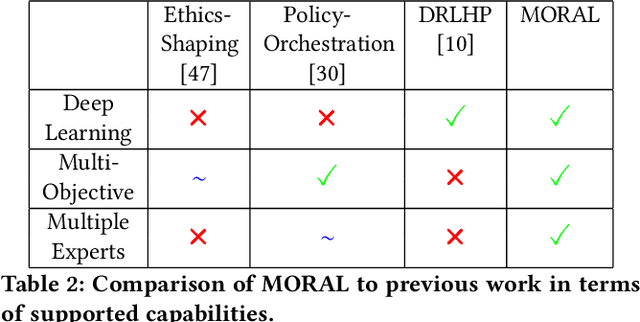
Inferring reward functions from demonstrations and pairwise preferences are auspicious approaches for aligning Reinforcement Learning (RL) agents with human intentions. However, state-of-the art methods typically focus on learning a single reward model, thus rendering it difficult to trade off different reward functions from multiple experts. We propose Multi-Objective Reinforced Active Learning (MORAL), a novel method for combining diverse demonstrations of social norms into a Pareto-optimal policy. Through maintaining a distribution over scalarization weights, our approach is able to interactively tune a deep RL agent towards a variety of preferences, while eliminating the need for computing multiple policies. We empirically demonstrate the effectiveness of MORAL in two scenarios, which model a delivery and an emergency task that require an agent to act in the presence of normative conflicts. Overall, we consider our research a step towards multi-objective RL with learned rewards, bridging the gap between current reward learning and machine ethics literature.
Multi-Agent MDP Homomorphic Networks
Oct 09, 2021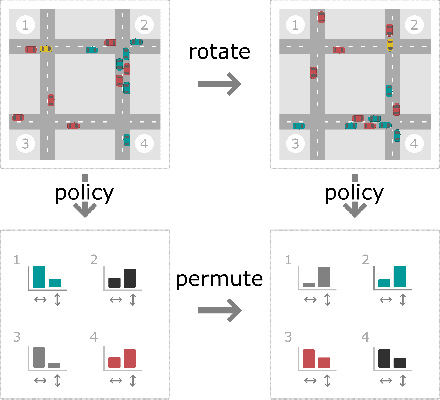
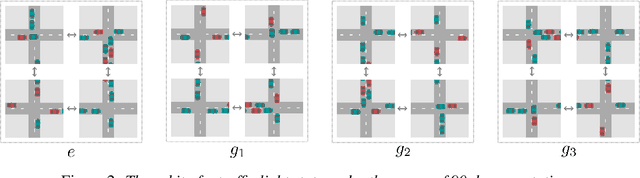
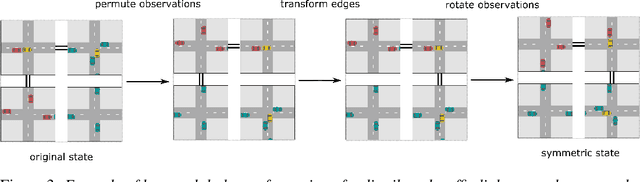
This paper introduces Multi-Agent MDP Homomorphic Networks, a class of networks that allows distributed execution using only local information, yet is able to share experience between global symmetries in the joint state-action space of cooperative multi-agent systems. In cooperative multi-agent systems, complex symmetries arise between different configurations of the agents and their local observations. For example, consider a group of agents navigating: rotating the state globally results in a permutation of the optimal joint policy. Existing work on symmetries in single agent reinforcement learning can only be generalized to the fully centralized setting, because such approaches rely on the global symmetry in the full state-action spaces, and these can result in correspondences across agents. To encode such symmetries while still allowing distributed execution we propose a factorization that decomposes global symmetries into local transformations. Our proposed factorization allows for distributing the computation that enforces global symmetries over local agents and local interactions. We introduce a multi-agent equivariant policy network based on this factorization. We show empirically on symmetric multi-agent problems that distributed execution of globally symmetric policies improves data efficiency compared to non-equivariant baselines.
Difference Rewards Policy Gradients
Dec 21, 2020

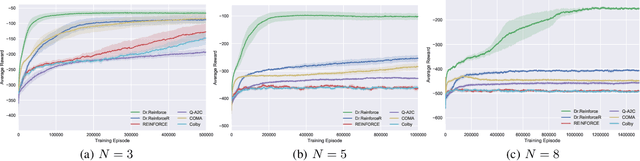
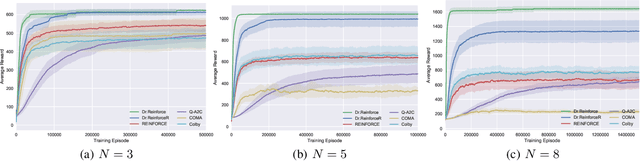
Policy gradient methods have become one of the most popular classes of algorithms for multi-agent reinforcement learning. A key challenge, however, that is not addressed by many of these methods is multi-agent credit assignment: assessing an agent's contribution to the overall performance, which is crucial for learning good policies. We propose a novel algorithm called Dr.Reinforce that explicitly tackles this by combining difference rewards with policy gradients to allow for learning decentralized policies when the reward function is known. By differencing the reward function directly, Dr.Reinforce avoids difficulties associated with learning the Q-function as done by Counterfactual Multiagent Policy Gradients (COMA), a state-of-the-art difference rewards method. For applications where the reward function is unknown, we show the effectiveness of a version of Dr.Reinforce that learns an additional reward network that is used to estimate the difference rewards.
Analog Circuit Design with Dyna-Style Reinforcement Learning
Nov 16, 2020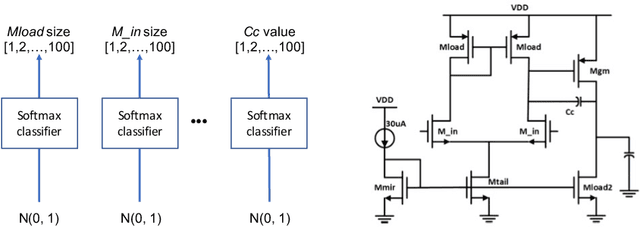
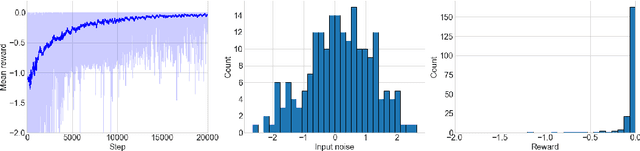
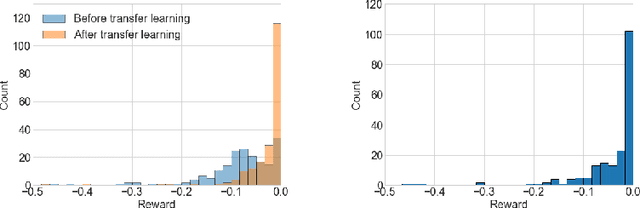
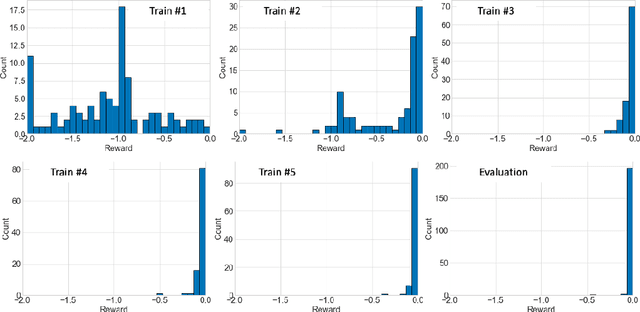
In this work, we present a learning based approach to analog circuit design, where the goal is to optimize circuit performance subject to certain design constraints. One of the aspects that makes this problem challenging to optimize, is that measuring the performance of candidate configurations with simulation can be computationally expensive, particularly in the post-layout design. Additionally, the large number of design constraints and the interaction between the relevant quantities makes the problem complex. Therefore, to better facilitate supporting the human designers, it is desirable to gain knowledge about the whole space of feasible solutions. In order to tackle these challenges, we take inspiration from model-based reinforcement learning and propose a method with two key properties. First, it learns a reward model, i.e., surrogate model of the performance approximated by neural networks, to reduce the required number of simulation. Second, it uses a stochastic policy generator to explore the diverse solution space satisfying constraints. Together we combine these in a Dyna-style optimization framework, which we call DynaOpt, and empirically evaluate the performance on a circuit benchmark of a two-stage operational amplifier. The results show that, compared to the model-free method applied with 20,000 circuit simulations to train the policy, DynaOpt achieves even much better performance by learning from scratch with only 500 simulations.